BIT大数据开发课程-实践部分全指南(下-运行代码)
手把手教你如何搭建Hadoop+Hbase+Zookeeper环境。下一篇文章将会教你如何设计一个倒序排列词句的应用。BIT大三小学期,大数据开发实践。
BIT大数据开发课程-实践部分全指南(下-运行代码)
小学期大数据系统开发实践
大数据开发实践
前文提要
上一章,完整记录了如何从几个jar包开始,一步步建立Hadoop+Hbase+ZooKeeper集群。在集群建立好之后,我们将可以尝试编写和运行代码。
提示,所有的的代码文本将会另存在Github,同时,为方便国内高速访问,设置了GitCode的镜像仓供同学们使用。
0. 明确题目要求
实现文档的倒排索引
(1) 运用MapReduce算法计算,构建一个倒排索引, 将倒排索引存储在HBase中
(2) 数据集,压缩文件sentences.txt.zip,大小500MB,解压文件1.43GB,下载地址:i北理课程群
(3) 下载数据之后,按照文件大小或者句子数量(例如10000个句子)构成一个文件,形成一个文件集合。可以编程实现文件分割或者使已有的文件分割工具软件。
故运行代码部分被分为了:1.编写切分代码(对数据集进行拆分),并上传;2. 编写MapReduce代码(倒排索引);3. 给代码打包Jar包;4. 运行项目。
1. 编写句子拆分代码
由于原句子数据集,解压缩后1.3g,不便于传输;故考虑在传输前,先进行句子拆分。
1.1 拆分代码
选择使用python,将每10000行视为一个文件,来进行原文件的拆分。实现代码如下图所示,已经做出了详细的注释。
注,代码已在Github和GitCode社区以MIT LICENSE开源,代码已经复现多次可用
def split_file(input_filename, lines_per_file=10000):
# 打开输入文件
with open(input_filename, 'r', encoding='utf-8') as input_file:
# 为输出文件设置计数器
file_count = 1
# 当前正在写入的文件对象
current_output = None
for line_number, line in enumerate(input_file, 1):
# 如果是第一行或当前行号能被lines_per_file整除,那么创建新的输出文件
if line_number % lines_per_file == 1:
# 如果不是第一个文件,先关闭上一个文件
if current_output:
current_output.close()
# 创建新文件并打开以准备写入
output_filename = f"split_{file_count}.txt"
current_output = open(output_filename, 'w', encoding='utf-8')
file_count += 1
# 写入当前行到输出文件
current_output.write(line)
# 在循环结束时确保最后一个文件被正确关闭
if current_output:
current_output.close()
# 使用函数分割文件
split_file('./sentence-cut/sentences.txt')
运行完得到分块文件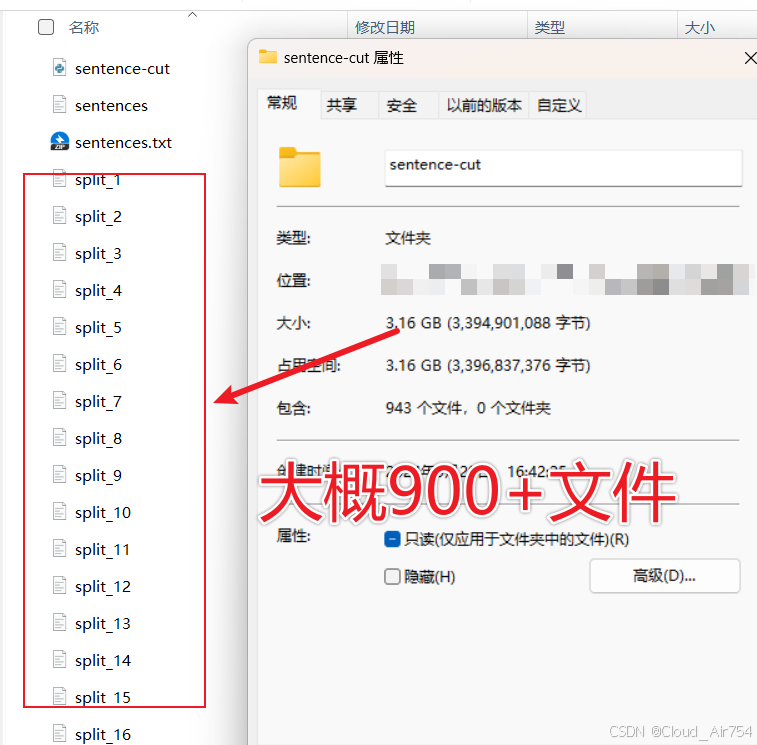
1.2 启动集群
上传之前需要启动所有集群,如果已经启动好,则跳过到1.3。
三台机器单独启动:
zkServer.sh start
第一台机器:
start-all.sh
第一台机器:
start-hbase.sh
1.3 拆分后内容上传
-
访问
node1:9870 -
选择
Browse the file system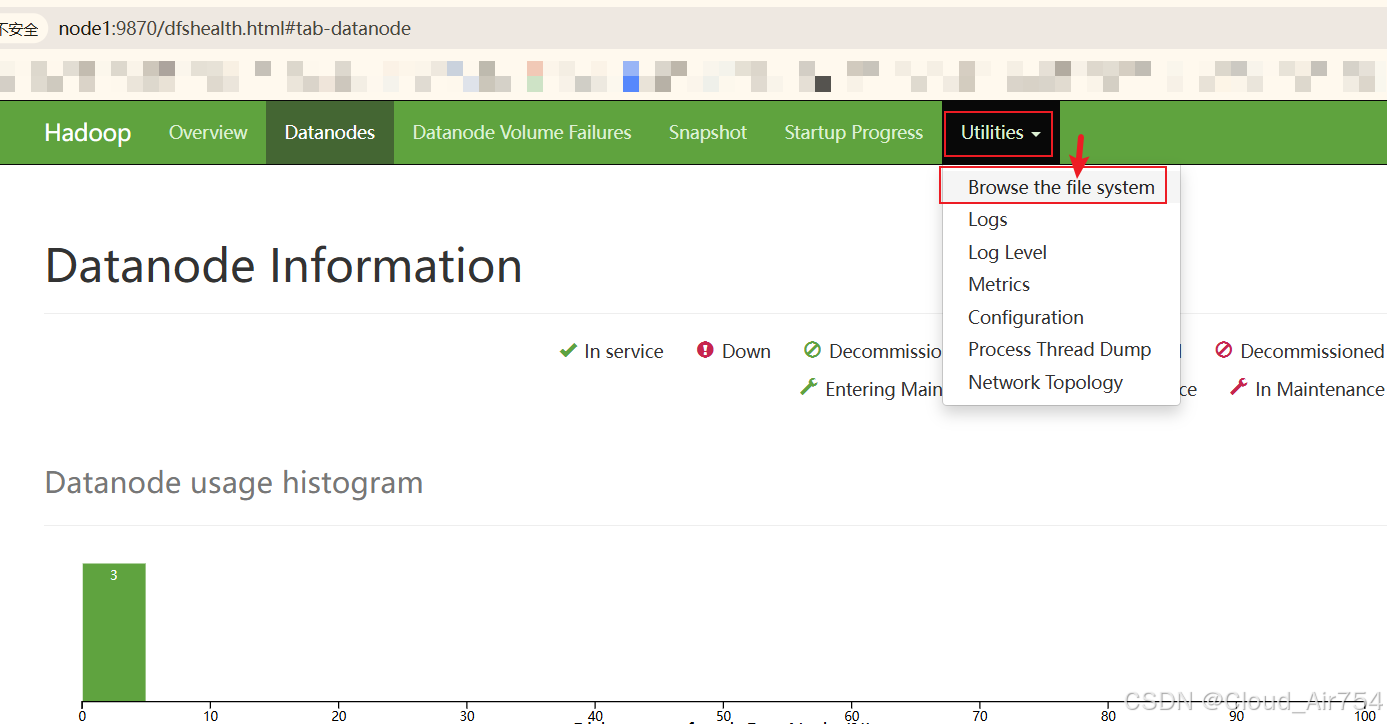
-
新建文件夹
/user/root/sentence_split! -
进入
sentence_split,然后点击上传。将所有的940个文本文件全部上传。静静等待上传完成。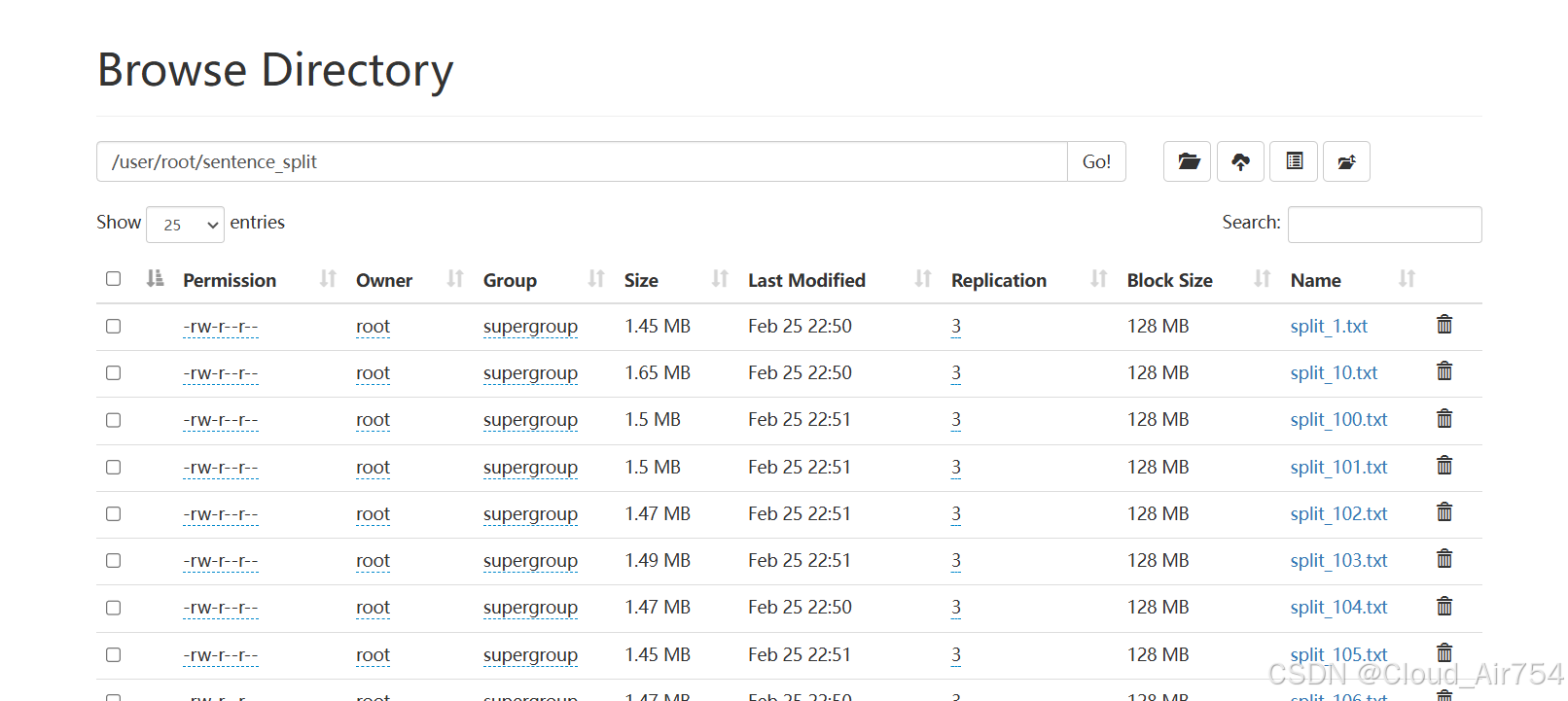
2. 编写MapReduce代码
注,代码已在Github和GitCode社区以MIT LICENSE开源,代码已经复现多次可用。
package com.example;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.io.Text;
public class InvertedIndex {
public static class Map extends Mapper<Object, Text, Text, Text> {
private Text keyInfo = new Text();
private Text valueInfo = new Text();
private FileSplit split;
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
split = (FileSplit) context.getInputSplit();
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {//按行map,然后放文件名,如果相对路径名就太长了
String fileName = split.getPath().getName();
keyInfo.set(itr.nextToken() + ":" + fileName);
valueInfo.set("1");
context.write(keyInfo, valueInfo);
}
}
}
public static class Combine extends Reducer<Text, Text, Text, Text> {
private Text info = new Text();
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {//这个是combine步骤
int sum = 0;
for (Text value : values) {
sum += Integer.parseInt(value.toString());
}
int splitIndex = key.toString().indexOf(":");
info.set(key.toString().substring(splitIndex + 1) + ":" + sum);
key.set(key.toString().substring(0, splitIndex));
context.write(key, info);
}
}
public static class Reduce extends Reducer<Text, Text, ImmutableBytesWritable, Put> {
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//开始写入数据库中。
String fileList = "";
for (Text value : values) {
fileList += value.toString() + ";";
}
Put put = new Put(Bytes.toBytes(key.toString()));
put.addColumn(Bytes.toBytes("fileInfo"), Bytes.toBytes("fileList"), Bytes.toBytes(fileList));
context.write(new ImmutableBytesWritable(key.getBytes()), put);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
String[] ioArgs = new String[]{"sentence_split", "output"};
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: Inverted Index <in> <out>");
System.exit(2);
}
//现在就是把job建起来,然后启动
Job job = new Job(conf, "Inverted Index");
job.setJarByClass(InvertedIndex.class);
job.setMapperClass(Map.class);
job.setCombinerClass(Combine.class);
job.setReducerClass(Reduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(ImmutableBytesWritable.class);
job.setOutputValueClass(Put.class);
//向hbase中写入InvertedIndexTable是已经建立好的表
job.setOutputFormatClass(TableOutputFormat.class);
job.getConfiguration().set(TableOutputFormat.OUTPUT_TABLE, "InvertedIndexTable");
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
3. 对Java进行打包
由于代码中使用了多个hadoop的包,为了方便版本管理,最好是放在Linux机器上进行打包操作。此处对Java的命令行操作有一定要求,无Java基础可以按照顺序依次进行。
3.1 使用mvn进行包管理
安装MVN
yum install maven
生成包
建立好后,使用mvn创建软件结构
mvn archetype:generate -DgroupId=com.example -DartifactId=InvertedIndex -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
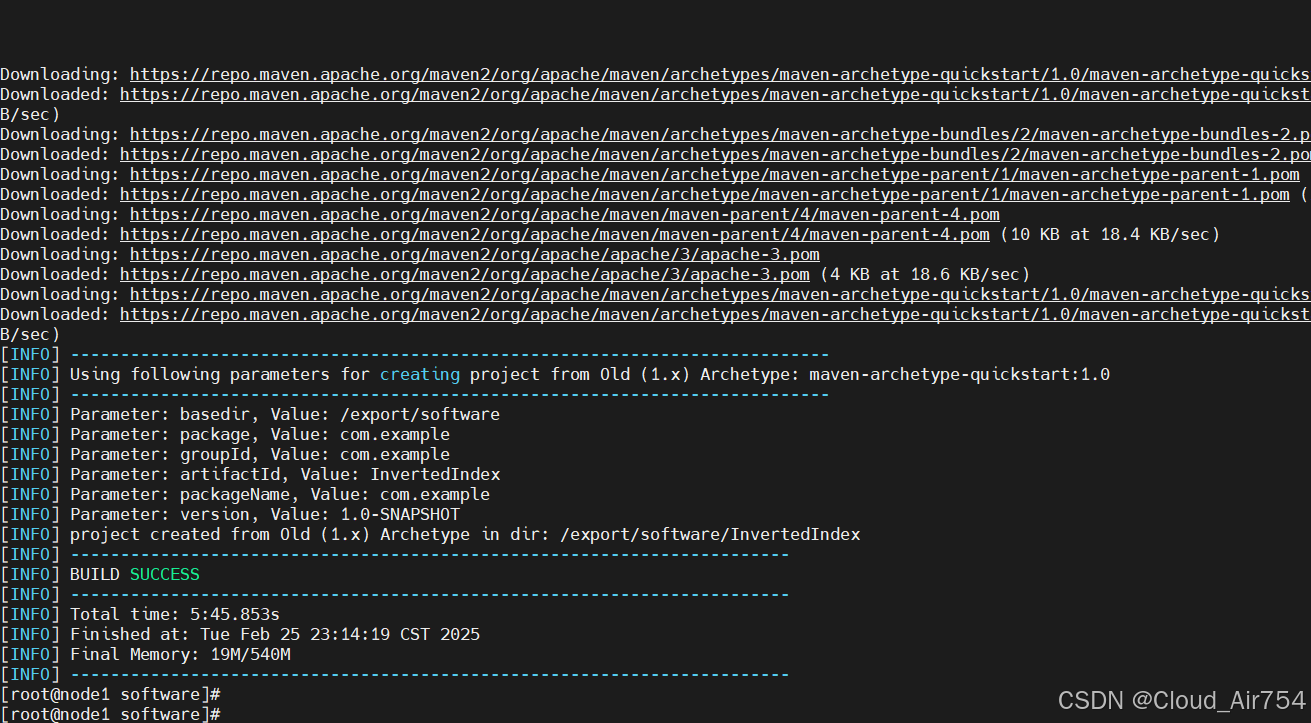
形成的文件架构如图,重点关注这两个文件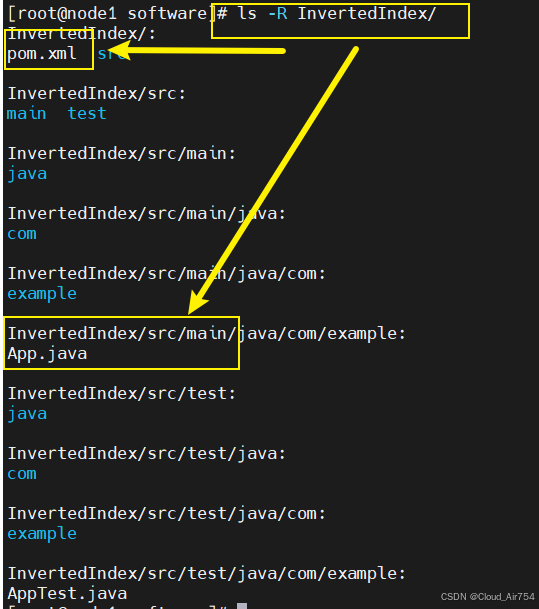
编辑pom.xml
添加以下依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>InvertedIndex</artifactId>
<packaging>jar</packaging>
<version>1.0-SNAPSHOT</version>
<name>InvertedIndex</name>
<url>http://maven.apache.org</url>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.6</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.5.5</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.5.5</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-mapreduce</artifactId>
<version>2.5.5</version> <!-- 确保版本与HBase其他模块兼容 -->
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.2.0</version> <!-- 请使用最新版本 -->
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<mainClass>com.example.InvertedIndex</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version> <!-- 请使用最新版本 -->
<configuration>
<archive>
<manifest>
<mainClass>com.example.InvertedIndex</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
3.2 上传Java代码
-
拖动
InvertedIndex.java到/tmp文件夹 -
将你的InvertedIndex.java文件放置到src/main/java/com/example/目录下
-
mv /tmp/InvertedIndex.java /export/software/Invertedindex/src/main/java/com/example/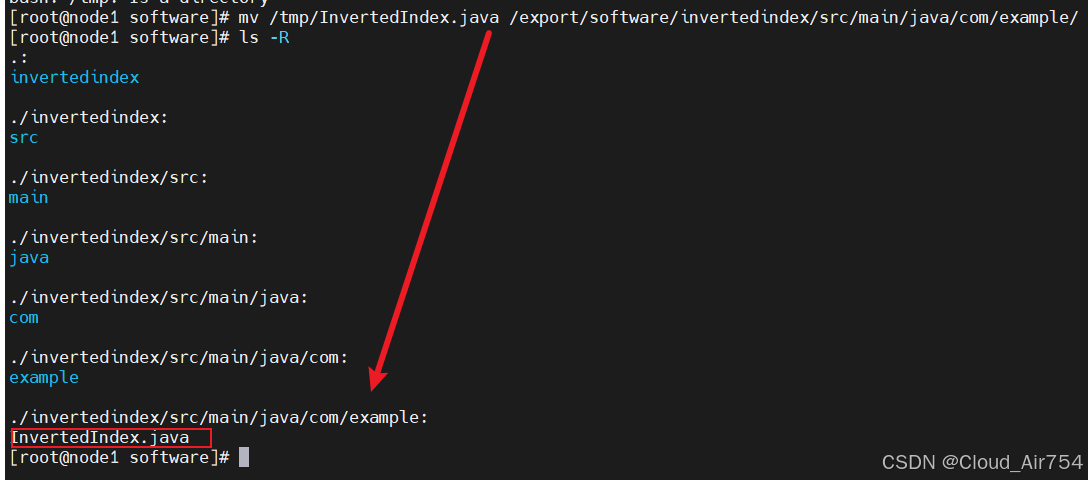
最终将*.java存放到这个结构下;并删除原来的*.java
3.3 使用mvn打包
在项目的根目录下运行以下命令:
mvn clean install
mvn clean package
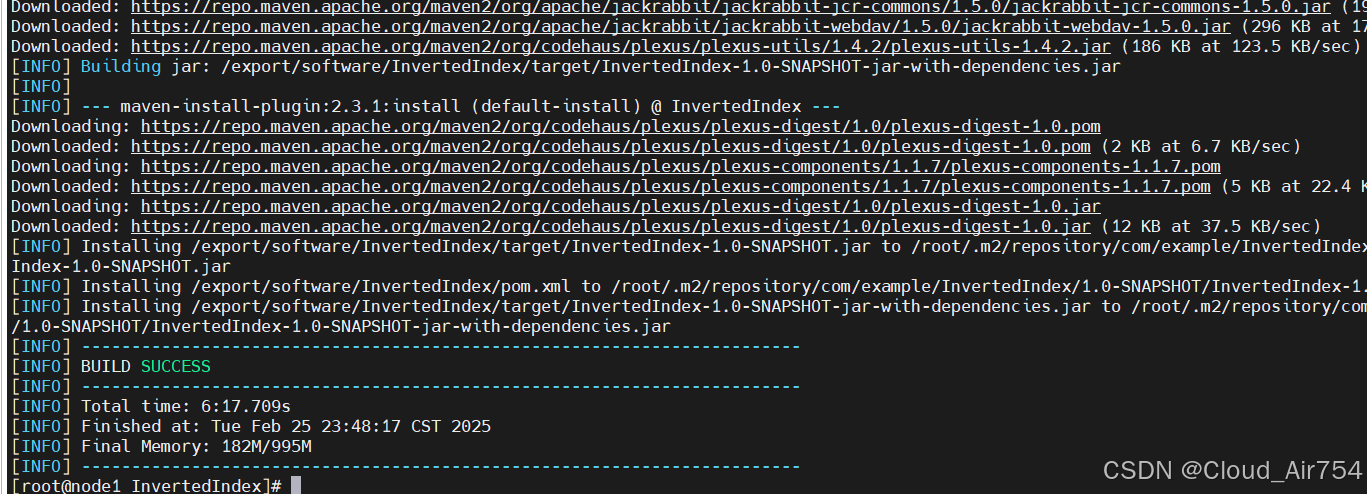
得到两个jar包
4. 运行MapReduce
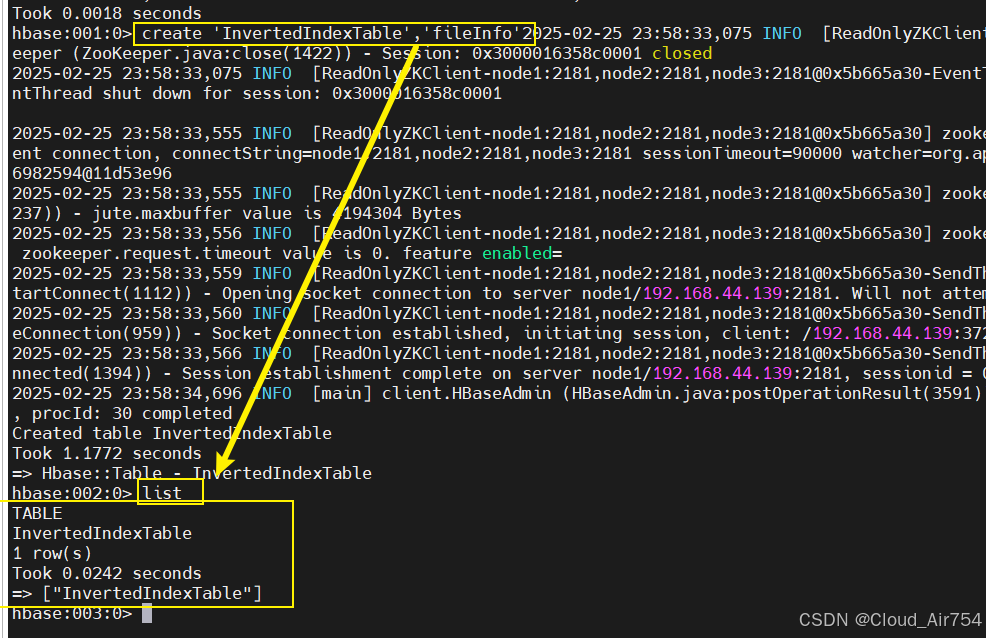
4.1 创建hbase table
hbase shell
create 'InvertedIndexTable','fileInfo'
list
exit
4.2 运行jar包
按照这个语法运行
hadoop jar your-jar-file.jar com.example.InvertedIndex input_path output_path
实际代码是这个
hadoop jar /export/software/InvertedIndex/target/InvertedIndex-1.0-SNAPSHOT-jar-with-dependencies.jar InvertedIndex /sentences
5. 运行实况
启动情况
运行情况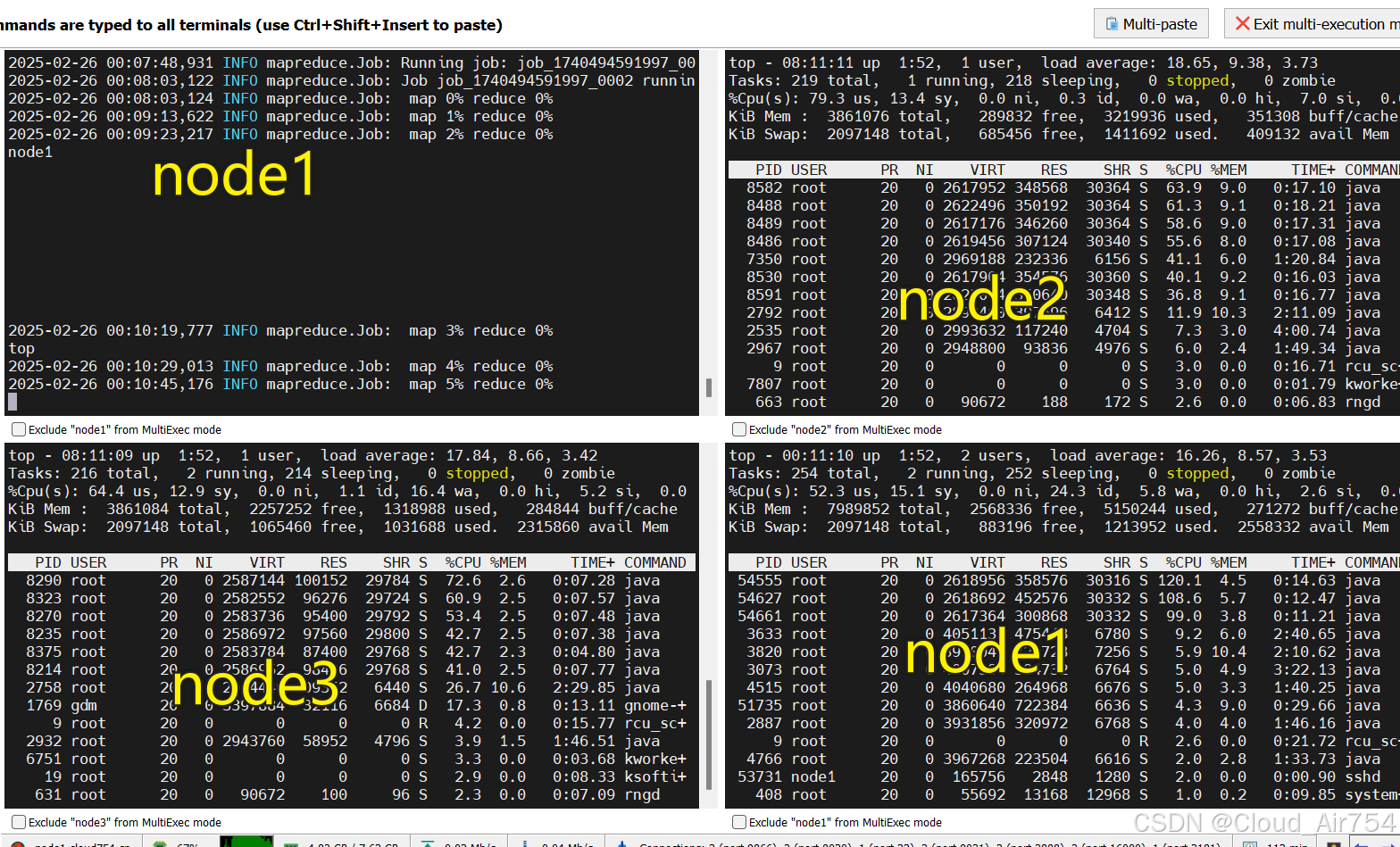
以下照片为当时交作业的时候跑的截图
 结算动画
结算动画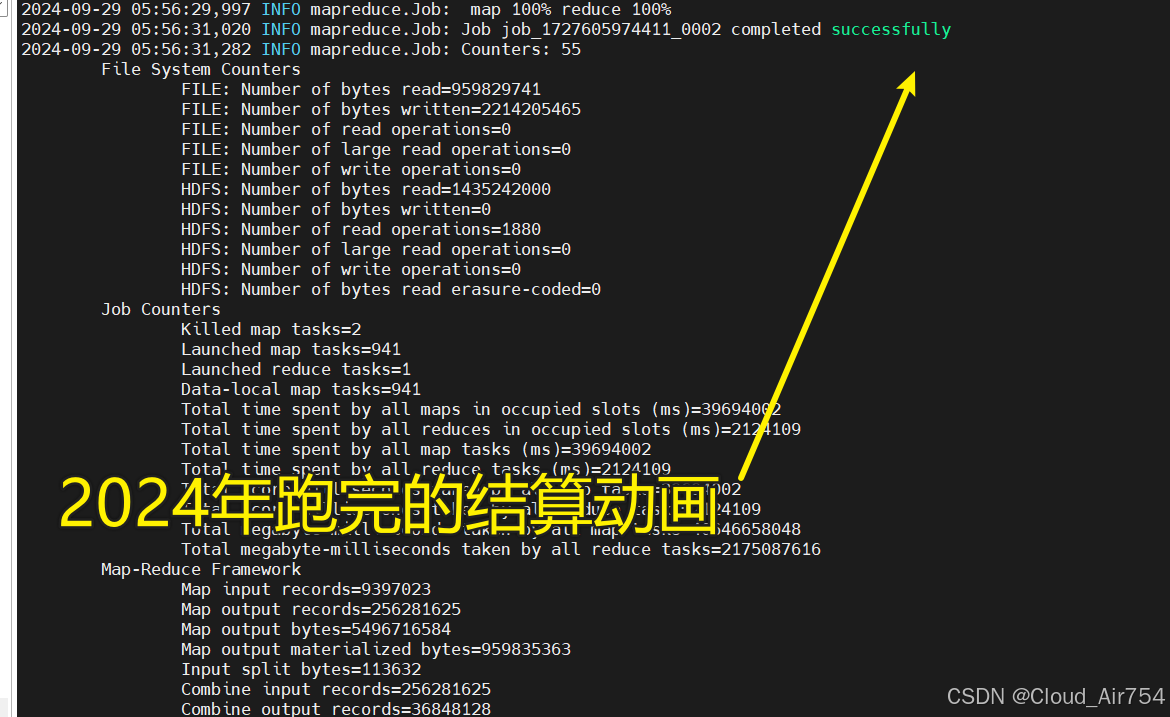
倒排索引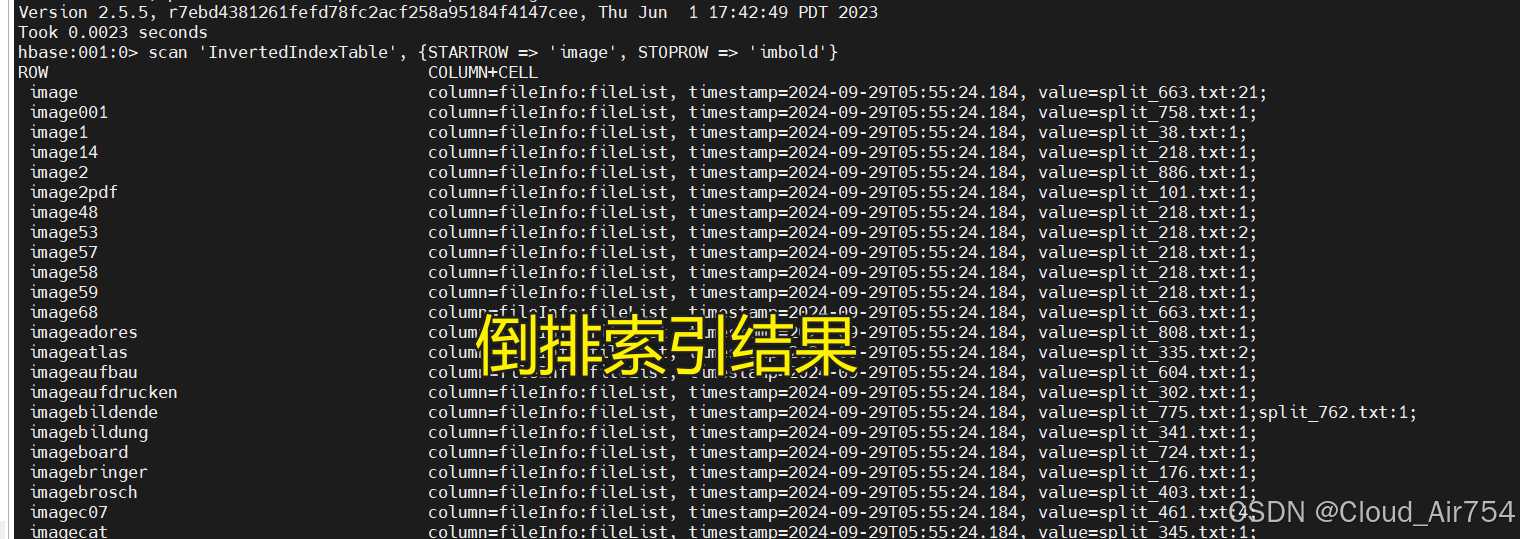
友情链接
参考文献
以下网页、视频、工具,在不同程度帮助我学习了本文章的内容,在此对提供帮助的技术前辈表示感谢~
- 通义千问

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)