

Update: This post is part of a blog series on Meta-Learning that I’m working on. Check out part 1, part 2, and part 3.
更新:这篇文章是我正在从事的有关元学习的博客系列的一部分。 检出第1部分,第2部分和第3部分。
介绍 (Introduction)
In my previous posts, “Meta-Learning Is All You Need” and “Bayesian Meta-Learning Is All You Need,” we have only discussed meta-learning in the supervised setting, in which we have access to labeled data and hand-specified task distributions. However, acquiring labeled data for many tasks and manually constructing task distributions is challenging and time-consuming. Such dependencies put conceptual limits on the type of problems that can be solved through meta-learning.
在我以前的文章“仅需要元学习”和“贝叶斯元学习就是你所需要的”中,我们仅讨论了在监督设置下的元学习,在这种环境下,我们可以访问标记的数据并手动指定任务分配。 但是,获取许多任务的标记数据并手动构建任务分布是一项挑战,而且很耗时。 这种依赖性在概念上限制了可以通过元学习解决的问题类型。
Can we design a meta-learning algorithm to handle unlabeled data, where the algorithm can come up with its own tasks that prepare for future downstream tasks?
我们可以设计一个元学习算法来处理未标记的数据,该算法可以提出自己的任务,为将来的下游任务做准备吗?
Unsupervised meta-learning algorithms effectively use unlabeled data to tune their learning procedures by proposing their task distributions. A robust unsupervised meta-learner, once trained, should be able to take new and different data from a task with labels, acquire task-specific knowledge from the training set, and generalize well on the test set during inference.
Unsuper v ISED元学习算法有效地提出自己的任务分配使用无标签数据来调整自己的学习方法。 一个健壮的无监督元学习者,一旦经过训练,就应该能够从带有标签的任务中获取新的和不同的数据,从训练集中获取特定于任务的知识,并在推理过程中很好地概括测试集。
This blog post is my attempt to explore the unsupervised lens of meta-learning and tackle the most prominent papers in this sub-domain.
这篇博客文章是我尝试探索元学习的无监督视角并解决该子领域中最杰出的论文。
1 —仙人掌 (1 — CACTUs)
Hsu, Levine, and Finn come up with Clustering to Automatically Construct Tasks for Unsupervised Meta-Learning (CACTUs) — an unsupervised meta-learning method that learns a learning procedure, without supervision, that is useful to solve a wide range of new human-specified tasks. With only raw unlabeled observations, the model can learn a reasonable prior such that, after meta-training, when presented with a small dataset for a human-specified task, the model can transfer its previous experience to learn to perform the new task efficiently.
Hsu,Levine和Finn提出了聚类功能,以自动构造无监督元学习(CACTU)的任务。无监督元学习方法是一种无监督元学习方法,无需监督即可学习学习程序,可用于解决各种新的人类学习问题。指定的任务。 仅使用原始的未标记观察值,模型就可以学习合理的先验,从而在元训练之后,当为人指定的任务提供小的数据集时,模型可以转移其先前的经验来学习有效地执行新任务。
The diagram below illustrates CACTUs:
下图说明了CACTU:
- Given raw unlabeled images, the algorithm first runs unsupervised learning on the images to get a low-dimensional embedding space. 给定原始的未标记图像,该算法首先在图像上运行无监督学习以获得低维嵌入空间。
- Second, the algorithm proposes tasks by clustering the embeddings multiple times within this low-dimensional latent space. Different data groupings will then be generated. To get a task, the algorithm samples these different groupings and treat each grouping as a separate class label. 其次,该算法通过在低维潜在空间内多次对嵌入进行聚类来提出任务。 然后将生成不同的数据分组。 为了获得任务,该算法对这些不同的分组进行采样,并将每个分组视为一个单独的类标签。
- Third, the algorithm runs meta-learning methods (black-box, optimization-based, or non-parametric) on the tasks. The result of this process is going to be a representation that is suitable for learning downstream tasks. 第三,该算法在任务上运行元学习方法(黑盒,基于优化或非参数的)。 该过程的结果将是适合学习下游任务的表示形式。
Let’s unpack CACTUs further: The key question is how to construct classification tasks from unlabeled data D = {xᵢ} automatically.
让我们进一步解压缩CACTU:关键问题是如何从未标记的数据D = {xᵢ}自动构造分类任务。
CACTUs use k-means clustering to group data points into consistent and distinct subsets based on salient features. If the clusters can recover a semblance of the true class-conditional generative distributions, creating tasks based on treating these clusters as classes should result in useful unsupervised meta-learning. However, the result of k-means is critically dependent on the metric space on which its objective is defined. Thus, CACTUs use SOTA unsupervised learning methods to produce useful embedding spaces. In particular, the authors try out four different embedding methods to generate tasks: ACAI, BiGAN, DeepCluster, and InfoGAN.
CACTU使用k均值聚类将数据点基于显着特征分组为一致且不同的子集。 如果集群可以恢复真实的类条件生成分布的相似性,则基于将这些集群视为类来创建任务应该会导致有用的无监督元学习。 但是,k均值的结果严格取决于定义其目标的度量空间。 因此,CACTU使用SOTA无监督学习方法来生成有用的嵌入空间。 特别是,作者尝试了四种不同的嵌入方法来生成任务:ACAI,BiGAN,DeepCluster和InfoGAN。
-
Adversarially Constrained Autoencoder Interpolation (ACAI) is a convolutional autoencoder architecture whose loss is regularized with a term that encourages meaningful interpolations in the latent space.
对抗约束自动编码器插值(ACAI)是一种卷积自动编码器体系结构,其损耗通过鼓励潜在空间中有意义插值的术语进行了正则化。
-
Bidirectional GAN (BiGAN) is a generative adversarial network where the discriminator produces synthetic images from real embedding and synthetic embedding from real image.
双向GAN (BiGAN)是一种生成对抗网络,其中的鉴别器从真实嵌入生成合成图像,并从真实图像生成合成嵌入。
-
DeepCluster is a clustering technique where: first, the features of a convolutional neural network are clustered. Second, the feature clusters are used as labels to optimize the network weights via backpropagation.
DeepCluster是一种聚类技术,其中:首先,对卷积神经网络的特征进行聚类。 其次,将特征簇用作标签,以通过反向传播优化网络权重。
-
InfoGAN is another generative adversarial network where the input to the generator is decomposed into a latent code incompressible noise.
InfoGAN是另一种对抗性生成网络,其中生成器的输入被分解为潜码不可压缩的噪声。
CACTUs run out-of-the-box unsupervised embedding learning algorithms on D, then map the data {xᵢ} into the embedding space Z, producing {zᵢ}. To build a diverse task set, CACTUs generates P partitions {Pₚ} by running clustering P times, applying random scaling to the dimensions of Z to induce a different metric, represented by a diagonal matrix A, for each run of clustering. With μ_c denoting the learned centroid of cluster C_c, a single run of clustering can be summarized with:
CACTU在D上运行开箱即用的无监督嵌入学习算法,然后将数据{xᵢ}映射到嵌入空间Z中,生成{zᵢ}。 为了构建多样化的任务集,CACTU通过运行P次聚类生成P个分区{Pₚ},对每次聚类运行将随机缩放应用于Z的维度,以得出对角矩阵A表示的不同度量。 使用μ_c表示群集C_c的学习质心,可以用以下命令总结一次群集运行:
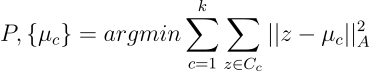
With the partitions being constructed over {zᵢ}, CACTUs finally meta-learn on the images, so that the learning procedure can adapt to each evaluation task from the rawest level of representation. For this meta-learning phase, the authors try out two different methods to learn the representation: MAML and ProtoNets.
通过在{zᵢ}上构建分区,CACTU最终对图像进行元学习,以便学习过程可以从最原始的表示水平适应每个评估任务。 对于这个元学习阶段,作者尝试了两种不同的方法来学习表示形式:MAML和ProtoNets。
-
Model-Agnostic Meta-Learning (MAML) learns the meta-parameters of a neural network so that they can lead to useful generalization in a few gradient steps.
-
Prototypical Networks (ProtoNets) learn a representation where each class can be effectively identified by its prototype — which is the mean of the class’ training examples in the meta-learned space.
原型网络(ProtoNets)学习一种表示形式,可以通过其原型有效地识别每个班级-这是该班级学习实例在元学习空间中的平均值。
Here are the main benefits of CACTUs from the experimental setting conducted in the paper on MNIST, CelebA, Omniglot, and Mini-ImageNet datasets:
这是论文针对MNIST , CelebA , Omniglot和Mini-ImageNet数据集进行的实验设置中的CACTU的主要优点:
- There is a big advantage of meta-learning on tasks derived from embeddings, rather than using only the embeddings for downstream supervised learning of new tasks. 在从嵌入中派生的任务上进行元学习有很大的优势,而不是仅将嵌入用于新任务的下游监督学习。
- CACTUs is sufficient for all four embedding learning methods that generate tasks. CACTU对于生成任务的所有四种嵌入式学习方法都是足够的。
- CACTU learns an effective prior to a variety of task types. This means that it is suitable for tasks with different supervision signals, or tasks that deal with features in different scales. CACTU在学习各种任务之前先学习有效的知识。 这意味着它适用于具有不同监控信号的任务,或处理不同比例特征的任务。
However, the authors noted that with its evaluation-agnostic task generation, CACTUs trades off performance in specific use cases for broad applicability and the ability to train on unlabeled data. An exciting direction for future work is making CACTUs more robust towards highly unstructured and unlabeled datasets.
但是,作者指出,CACTU通过其与评估无关的任务生成,在特定用例中权衡了性能,以获取广泛的适用性以及对未标记数据进行训练的能力。 未来工作的一个令人振奋的方向是使CACTU对高度结构化和未标记的数据集更加强大。
2-UMTRA(2018) (2 — UMTRA (2018))
Khodadadeh, Boloni, and Shah present Unsupervised Meta-Learning with Tasks constructed by Random Sampling and Augmentation (UMTRA), which performs meta-learning of one-shot and few-shot classifiers in an unsupervised manner on an unlabeled dataset. As seen in the diagram below:
Khodadadeh,Boloni和Shah提出了带有随机抽样和增强(UMTRA)构造的任务的无监督元学习,该任务以无监督方式在未标记的数据集上执行单发和少发分类器的元学习。 如下图所示:
- UMTRA starts with a collection of unlabeled data. The objects within this collection have to be drawn from the same distribution as the objects classified in the target task. Furthermore, the unlabeled data must have a set of classes significantly larger than the number of classes of the final classifier. UMTRA开始于未标记数据的收集。 必须从与目标任务中分类的对象相同的分布中提取此集合中的对象。 此外,未标记的数据必须具有比最终分类器的类数大得多的类集。
- Starting from this unlabeled dataset, UMTRA uses statistical diversity properties and domain-specific augmentation to generate the training and validation data for a collection of synthetic tasks. 从这个未标记的数据集开始,UMTRA使用统计多样性属性和特定领域的扩充来生成用于合成任务集合的训练和验证数据。
-
These tasks are then used in the meta-learning process based on a modified classification variant of the Model-Agnostic Meta-Learning (MAML) algorithm.
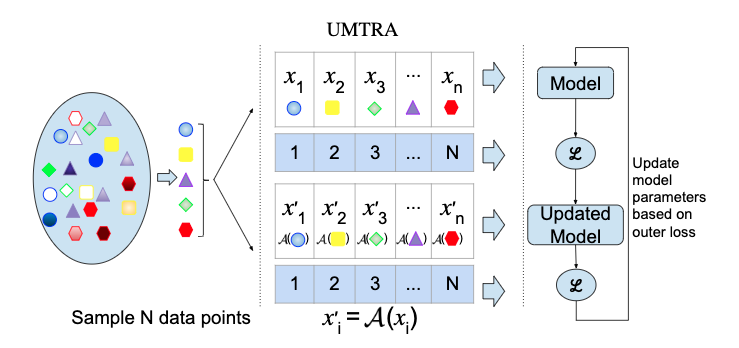
More formally speaking:
更正式地说:
- In supervised meta-learning, we have access to a collection of tasks T₁, …, T, drawn from a specific distribution, with both supervised training and validation data. Each task T has N classes of K training/validation samples. 在有监督的元学习中,我们可以访问从特定分布中提取的任务T₁,…,T的集合,其中包含有监督的训练和验证数据。 每个任务T具有N个类别的K个训练/验证样本。
- In unsupervised meta-learning, we don’t have the collection of tasks T₁, …, T, and their associated labeled training data. Instead, we only have an unlabeled dataset U = { … xᵢ …}, with samples drawn from the same distribution as the target task. Every element of this dataset is associated with a natural class C₁ … Cc. 在无监督的元学习中,我们没有任务T₁,…,T及其相关的带标签的训练数据的集合。 相反,我们只有一个未标记的数据集U = {…xᵢ…},其样本是从与目标任务相同的分布中提取的。 此数据集的每个元素都与自然类C₁... Cc相关联。
To run the UMTRA algorithm, we need to create tasks Tᵢ from the unsupervised data that can serve the same role as the meta-learning tasks in the full MAML algorithm. For such a task, we need to create both the training data D and the validation data D’.
要运行UMTRA算法,我们需要从不受监督的数据中创建任务Tᵢ,这些任务可以起到与完整MAML算法中的元学习任务相同的作用。 为此,我们需要创建训练数据D和验证数据D'。
-
The training data is Dᵢ = {(x₁, 1), …, (x_N, N)} with xᵢ sampled randomly from U.
训练数据为Dᵢ= {(x₁,1),…,(x_N,N)},其中xᵢ是从U随机采样的。
-
The validation data Dᵢ’ = {(x₁’, 1), …, (x_N’, N)} is created by augmenting the sampled used in the training data using an augmentation function xᵢ’ = A(xᵢ).
验证数据Dᵢ'= {(x₁',1),…,(x_N',N)}通过使用扩充函数xᵢ'= A(xᵢ)扩充训练数据中使用的采样来创建。
Experiments on Omniglot and Mini-ImageNet datasets in the paper show that UMTRA outperforms learning-from-scratch approaches and approaches based on unsupervised representation learning. Furthermore, the statistical sampling and augmentation performed by UMTRA can be seen as a cheaper alternative to the dataset-wide clustering performed by CACTUs.
本文对Omniglot和Mini-ImageNet数据集进行的实验表明,UMTRA优于从零开始学习的方法和基于无监督表示学习的方法。 此外,可以将UMTRA执行的统计采样和扩充视为CACTU执行的整个数据集聚类的更便宜的替代方案。
3 —无监督的元强化学习(2018年) (3 — Unsupervised Meta-Reinforcement Learning (2018))
Throughout this series, I haven’t brought up meta reinforcement learning yet, a family of algorithms that can learn to solve new reinforcement learning tasks more quickly through experience on past tasks. They assume the ability to sample from a pre-specified task distribution. They can solve new tasks drawn from this distribution very quickly. However, specifying a task distribution is tedious and requires a significant amount of supervision that may be difficult to provide for sizeable real-world problem settings. Can we automate the process of task design and remove the need for human supervision entirely?
在整个系列中,我还没有提到过元强化学习,这是一种算法系列,可以通过对过去任务的经验学习来更快地解决新的强化学习任务。 他们假定可以从预先指定的任务分发中进行采样。 他们可以非常快速地解决从此分发中提取的新任务。 但是,指定任务分配很繁琐,并且需要大量的监督,而这可能很难提供大量的实际问题设置。 我们是否可以使任务设计过程自动化并完全消除人工监督的需要?
Gupta, Eysenbach, Finn, and Levine apply unsupervised meta-learning to the context of meta reinforcement learning: meta-learning from a task distribution that is acquired automatically, rather than requiring manual design of the meta-training tasks. Given an environment, they want to propose tasks in an unsupervised way and then run meta-reinforcement learning on those tasks. The result is a reinforcement learning algorithm that is tuned for the given environment. Then for that environment, given a reward function from the human, the algorithm can maximize the function with a small amount of experience.
Gupta,Eysenbach,Finn和Levine将无监督的元学习应用于元强化学习的上下文:从自动获取的任务分布中进行元学习,而不需要手动设计元训练任务。 在给定的环境下,他们希望以无人监督的方式提出任务,然后对这些任务进行元强化学习。 结果是针对给定环境调整的强化学习算法。 然后,对于该环境,在给定人类奖励功能的情况下,该算法可以以少量经验最大化该功能。
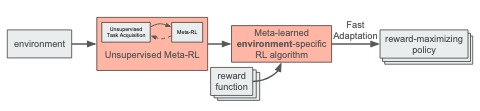
Formally speaking, the meta-training setting is a controlled Markov process (CMP) — a Markov decision process without a reward function: C = (S, A, P, γ, p) — where S is the state space, A is the action space, P is the transition dynamics, γ is the discount factor, and p is the initial state distribution. The CMP produces a Markov decision process M = (S, A, P, γ, p, r) — where r is the reward function.
从形式上来讲,元训练设置是受控的马尔可夫过程(CMP)-没有奖励函数的马尔可夫决策过程:C =(S,A,P,γ,p)-其中S是状态空间,A是状态空间动作空间,P是过渡动力学,γ是折现因子,p是初始状态分布。 CMP产生马尔可夫决策过程M =(S,A,P,γ,p,r)-其中r是奖励函数。
f: D -> π is a learning algorithm that inputs a dataset of experience from the MDP (D) and outputs a policy π. This algorithm is evaluated over several episodes: wherein each episode i, f observes all previous data {T₁, …, Tᵢ₋₁} and outputs a policy to be used in iteration i.
f:D->π是一种学习算法,它输入来自MDP(D)的经验数据集并输出策略π。 该算法在多个情节上进行评估:其中,每个情节i,f观察所有先前的数据{T₁,…,Tᵢ₋₁},并输出要在迭代i中使用的策略。
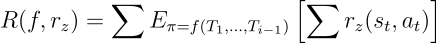
The goal of unsupervised meta-reinforcement learning is to take this CMP and produce an environment-specific learning algorithm f that can quickly learn an optimal policy πᵣ* for any reward function r.
无监督的元强化学习的目标是采用此CMP并生成特定于环境的学习算法f,该算法可以针对任何奖励函数r快速学习最优策略π*。
The key question is how to propose relevant tasks. The paper attempts to make a set of tasks that are more diverse from each other, where the skills within tasks are entirely different from one another. To cluster skills into discrete parts of the policy space, the authors use Diversity Is All You Need, which is a method that learns skills by maximizing an information-theoretic objective using a maximum entropy policy:
关键问题是如何提出相关任务。 本文试图制定一组彼此之间更加多样化的任务,其中任务内的技能彼此完全不同。 要将技能聚集到策略空间的各个不同部分,作者使用了多样性即是您所需要的,该方法通过使用最大熵策略来最大化信息理论目标来学习技能:

- The agent/policy takes as input a discrete skill (z) to produce actions. This skill z is used to generate the states in a given rollout according to a latent-conditioned policy π(a | s, z). 代理人/策略以离散技能(z)作为输入来产生动作。 技能z用于根据潜在条件策略π(a | s,z)生成给定部署中的状态。
- The discriminator network D_{θ} takes as input a state (s) and predicts which skill (z) to be passed into the policy. Diversity Is All You Need enforces a co-operative game where the policy visits which states are discriminable by the discriminator and the discriminator predicts the skill from the state. The objective of both is to maximize the accuracy of the discriminator. 鉴别器网络D_ {θ}将状态(s)作为输入,并预测要传递给策略的技能(z)。 多样性就是您所需要的,它实施了一个合作游戏,其中政策访问了区分者可区分的状态,区分者从状态中预测了技能。 两者的目的都是使鉴别器的准确性最大化。
- Using the discriminator, the authors make the reward function for unsupervised meta-learning to simply be the likelihood of one of the skills given the state: r_z(s, a) = log (D_{θ} (z|s)). 使用区分器,作者使无监督元学习的奖励函数简单地成为以下一种技能在给定状态下的可能性:r_z(s,a)= log(D_ {θ}(z | s))。
- Then, the authors use MAML with this reward r_z to acquire a fast learning algorithm f to learn new tasks quickly for the current reinforcement learning setting. 然后,作者使用具有此奖励r_z的MAML来获取快速学习算法f,以针对当前的强化学习设置快速学习新任务。
In their experiments, the author study three simulated environments of varying difficulty: 2D point navigation, 2D locomotion, and 3D locomotion. The results indicate that unsupervised meta-reinforcement learning effectively acquires accelerated reinforcement learning procedures without manual task design. These procedures exceed the performance of learning from scratch. However, one limitation is that the paper only considers deterministic dynamics and only considers task distributions with optimal posterior sampling. Thus, two exciting directions for future work are experimenting with stochastic dynamics and more realistic task distributions in large-scale datasets and complex tasks.
在他们的实验中,作者研究了三种难度不同的模拟环境:2D点导航,2D运动和3D运动。 结果表明,无监督的元强化学习无需手动任务设计即可有效地获得加速强化学习程序。 这些过程超出了从头学习的性能。 但是,一个局限性是该论文仅考虑确定性动力学,并且仅考虑具有最佳后验采样的任务分布。 因此,未来工作的两个激动人心的方向是尝试在大型数据集和复杂任务中进行随机动力学和更现实的任务分配。
4 —假设,增强和学习(2019年) (4 — Assume, Augment, and Learn (2019))
Antoniou and Storkey propose Assume, Augment, and Learn (AAL) that leverages unsupervised data to generate tasks for few-shot learners. This method is inspired by the ability of humans to find features that can accurately describe a set of randomly clustered data points, even when the clusters are continuously randomly reset. The authors believe that bringing this setting to meta-learning can produce strong representations for the task at hand.
Antoniou和Storkey提出了“假设,增强和学习” (AAL),该方法利用无人监督的数据来为少拍学习者生成任务。 这种方法的灵感来自于人类发现能够准确描述一组随机聚类数据点的特征的能力,即使连续不断地随机重置聚类也是如此。 作者相信,将此设置用于元学习可以为即将完成的任务提供强有力的表示。
The paper uses three separate datasets: a meta-training, a meta-validation, and a meta-test set.
本文使用三个独立的数据集:元训练,元验证和元测试集。
-
The meta-training set does not have any labels and is used to train a few-shot learner using AAL.
元训练集没有任何标签,用于使用AAL训练几率学习者。
-
The meta-validation and meta-test sets have labeled data and are used to evaluate the few-shot tasks. Using a validation set to pick the best-trained model and a test set to produce the final test errors removes any potential unintended over-fitting.
元验证和元测试集已标记数据,用于评估少量任务。 使用验证集选择训练有素的模型,并使用测试集产生最终测试错误,可以消除任何潜在的意外拟合现象。
-
Training meta-learning models requires using a large number of tasks. In particular, AAL relies on the set-to-set few-shot learning scheme in Vinyals et al. — where a task is composed of a support (training) set and a target (validation) set. Both sets have a different number of classes but a similar number of samples per class.
训练元学习模型需要使用大量任务。 特别是,AAL依赖于Vinyals等人的“按组设置的几次射击”学习方案。 —任务由支持(培训)集和目标(验证)集组成。 两组具有不同数量的类别,但每个类别的样本数量相似。
- Put that into the context of a meta-learning setting: Given a task, AAL learns a model that can acquire task-specific knowledge from the support set to perform well in the target set, before throwing away that knowledge. 将其放在元学习设置的上下文中:给定任务,AAL学习一个模型,该模型可以从支持集中获取特定于任务的知识,以在目标集中表现良好,然后再丢弃该知识。

AAL attempts to explore the semantic similarities between data points to learn robust across-task representations that can then be used in a setting where supervised labels are available. It consists of three phases:
AAL尝试探索数据点之间的语义相似性,以学习强大的跨任务表示形式,然后将其用于可使用监督标签的环境中。 它包括三个阶段:
-
First, AAL assumes data labels by randomly assigning labels for a randomly sampled set of data points. This allows the model to acquire fast-knowledge in its parameters that can classify the support set well.
首先,AAL通过为随机采样的数据点集随机分配标签来假定数据标签。 这允许模型获得可以很好地对支持集进行分类的参数的快速知识。
-
Second, AAL augments the number of data points in the support set via data augmentation techniques. This sets the number of classes in the support set to match the number of classes in the target set. Still, the samples in the two sets are different enough to allow the target set to serve as a satisfactory evaluation set.
第二,在经由数据增量技术支持数据点集合AAL增强件的数量。 这将设置支持集中的类数以匹配目标集中的类数。 尽管如此,两组中的样本差异很大,足以使目标组成为令人满意的评估组。
-
Third, AAL learns the tasks via any existing few-shot meta-learning technique, as long as the method can be trained using the set-to-set few-shot learning framework. In the paper, the authors experiment with Model Agnostic Meta-Learning and Prototypical Networks.
第三,AAL可以通过任何现有的少量快照元学习技术来学习任务,只要该方法可以使用按组设置的少量快照学习框架进行训练即可。 在本文中,作者使用模型不可知元学习和原型网络进行实验。
Experiments on Omniglot and Mini-ImageNet datasets in the paper verify that AAL generalizes well to real-labeled inference tasks. However, its performance heavily depends on the data augmentation strategies employed. Thus, a future direction would be to automate the search for an optimal data augmentation function to produce fully unsupervised systems with a strong performance.
本文中对Omniglot和Mini-ImageNet数据集进行的实验证明,AAL可以很好地概括实际标记的推理任务。 但是,其性能在很大程度上取决于所采用的数据扩充策略。 因此,未来的方向将是自动搜索最佳数据增强功能,以产生性能强大的完全不受监督的系统。
The papers discussed above all have a common attribute: the meta-objective of the outer loop is unsupervised, and therefore the learner itself is learned without any labels available. As I researched the meta-learning literature, I found another variant of meta-learning that involves unsupervised learning.
上面讨论的所有论文都有一个共同的属性:外循环的元目标是不受监督的,因此学习者本身是在没有任何可用标签的情况下学习的。 在研究元学习文献时,我发现了元学习的另一种形式,涉及无监督学习。
In this second variant, meta-learning is used as a means to learn an unsupervised inner loop task. The outer objective in this case can be anything from supervised, unsupervised, or reinforcement-based. This variant can be referred to as Meta-Learning Unsupervised Learning.
在第二种变体中,元学习被用作学习无监督内循环任务的一种手段。 在这种情况下,外部目标可以是有监督,无监督或基于增强的任何内容。 这种变体可以称为元学习无监督学习。
5 —无监督更新规则(2018年) (5 — Unsupervised Update Rules (2018))
Metz, Maheswaranathan, Cheung, and Sohl-Dickstein present the first meta-learning approach that tackles unsupervised representation learning, where the inner loop consists of unsupervised learning. The paper proposes to meta-learn an unsupervised update rule by meta-training on a meta-objective that directly optimizes the utility of the unsupervised representation. Unlike hand-designed unsupervised learning rules, this meta-objective directly targets the usefulness of a representation generated from unlabeled data for later supervised tasks. This approach contrasts with transfer learning, where a neural network is instead trained on a similar dataset, and then fine-tuned or post-processed on the target dataset.
Metz,Maheswaranathan,Cheung和Sohl-Dickstein提出了第一个解决无监督表示学习的元学习方法,这种方法的内在循环由无监督学习组成。 本文提出了通过对元目标进行元训练来元学习非监督更新规则,该元目标直接优化了非监督表示的效用。 与手工设计的无监督学习规则不同,此元目标直接针对从无标签数据生成的表示形式的有效性,以用于以后的监督任务。 这种方法与转移学习相反,转移学习是在类似的数据集上训练神经网络,然后在目标数据集上进行微调或后处理。
Furthermore, this is the first representation meta-learning approach to generalize across input data modalities and datasets, the first to generalize across permutation of the input dimensions, and the first to generalize across neural network architectures.
此外,这是第一个跨输入数据模态和数据集进行概括的表示元学习方法,第一个跨输入维度的排列进行归类的方法,以及第一个跨神经网络体系结构进行归纳的方法。
The diagram below provides a schematic illustration of the model:
下图提供了该模型的示意图:
-
The left-hand side shows how to meta-learn an unsupervised learning algorithm. The inner loop computation consists of iteratively applying the UnsupervisedUpdate to a base model. During meta-training, the UnsupervisedUpdate (parametrized by θ) is itself updated by gradient descent on the MetaObjective.
左侧显示了如何元学习无监督学习算法。 内循环计算包括将UnsupervisedUpdate迭代地应用于基本模型。 在元训练期间,UnsupervisedUpdate(由θ参数化)本身通过MetaObjective上的梯度下降进行更新。
-
The right-hand side goes deeper into the based model and UnsupervisedUpdate. Unlabeled input data (x) is passed through the base model, which is parameterized by W and colored green. The goal of the UnsupervisedUpdate is to modify W to achieve a top layer representation x^L, which performs well at few-shot learning. To train the base model, information is propagated backward by the UnsupervisedUpdate analogous to back-prop (colored blue).
右侧更深入地介绍了基础模型和UnsupervisedUpdate。 未标记的输入数据(x)通过基本模型传递,该基本模型由W参数化并显示为绿色。 UnsupervisedUpdate的目标是修改W以获得顶层表示x ^ L,该表示在几次学习中表现良好。 为了训练基本模型,信息通过UnsupervisedUpdate向后传播,类似于反向传播(蓝色)。
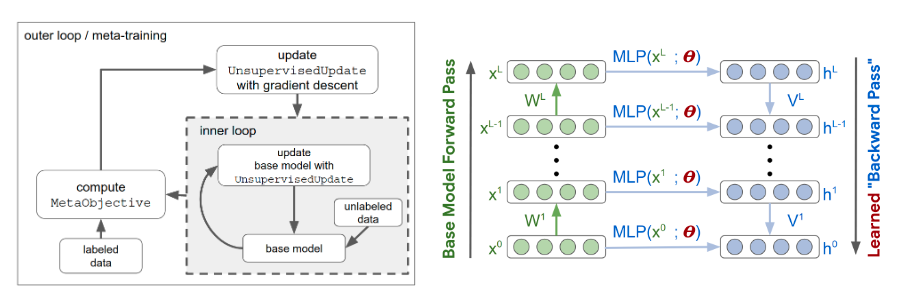
Let’s take a look at the design of the model deeper.
让我们更深入地研究模型的设计。
-
The base model is a standard fully-connected Multi-Layer Perceptron coupled with batch normalization layers and the ReLU activation unit.
基本模型是标准的全连接多层感知器,并具有批处理归一化层和ReLU激活单元。
-
The learned update rule is unique to each neuron layer so that the weight updates are a function of pre- and post-synaptic neurons in the base model and can be defined for any base model architecture. This design enables the update rule to generalize across architectures with different widths, depths, and network topologies.
学习到的更新规则对于每个神经元层都是唯一的,因此权重更新是基础模型中突触前和突触后神经元的函数,并且可以为任何基础模型体系结构定义。 这种设计使更新规则可以在具有不同宽度,深度和网络拓扑的体系结构之间进行概括。
-
The meta-objective determines the quality of the unsupervised representations. It is based on fitting a linear regression to labeled examples with a small number of data points.
元目标确定了无监督表示的质量。 它 基于将线性回归拟合到带有少量数据点的标记示例。
Based on the experiments on various datasets such as CIFAR 10, MNIST, Fashion MNIST, and IMDB, the performance of this method either matched or exceeded existing unsupervised learning on few-shot image classification and text classification tasks. With no explicitly defined objective, this work is a proof of an algorithm design principle that replaces manual fine-tuning with architectures designed for learning and learned from data via meta-learning.
基于对各种数据集(例如CIFAR 10 , MNIST , Fashion MNIST和IMDB )的实验,该方法的性能匹配或超过了现有的无人值守的少镜头图像分类和文本分类任务学习。 在没有明确定义目标的情况下,这项工作证明了一种算法设计原理,该原理用旨在通过元学习从数据中学习和学习的体系结构取代了手动微调。
6 —用于半监督学习的元学习(2018年) (6 — Meta-Learning For Semi-Supervised Learning (2018))
Ren, Triantafillou, Ravi, Snell, Swersky, Tenenbaum, Larochelle, and Zemel aim to generalize a few-shot learning setup for semi-supervised classification in two ways:
Ren,Triantafillou,Ravi,Snell,Swersky,Tenenbaum,Larochelle和Zemel旨在通过两种方式概括用于半监督分类的几次镜头学习设置:
- They consider a scenario where the new classes are learned in the presence of additional unlabeled data. 他们考虑了在存在其他未标记数据的情况下学习新类的情况。
-
They also consider the situation where the new classes to be learned are not viewed in isolation. Instead, many of the unlabeled examples are from different classes; the presence of such distractor classes introduces an additional and more realistic level of difficulty to the few-shot problem.
他们还考虑了要孤立学习新课程的情况。 相反,许多未标记的示例来自不同的类别。 这样的干扰因素类别的存在给少拍问题带来了额外的,更现实的难度。
The figure below shows a visualization of training and test episodes in the semi-supervised setting:
下图显示了在半监督环境中训练和测试情节的可视化:
- The training set is a tuple of labeled and unlabeled examples: (S, R). 训练集是带有标签和未标签示例的元组:(S,R)。
- The labeled examples are called the support set S that contains a list of tuples of inputs and targets. 标记的示例称为支持集S,其中包含输入和目标的元组列表。
- The unlabeled examples are called the unlabeled set R that contains only the inputs: R = {x₁, x₂, …, x_m}. 未标记的示例称为未标记的集合R,它仅包含输入:R = {x 1,x 2,…,x_m}。
- The models are trained to perform well when predicting the labels for the examples in the episode’s query set Q. 当预测情节的查询集Q中的示例标签时,对模型进行训练以使其表现良好。
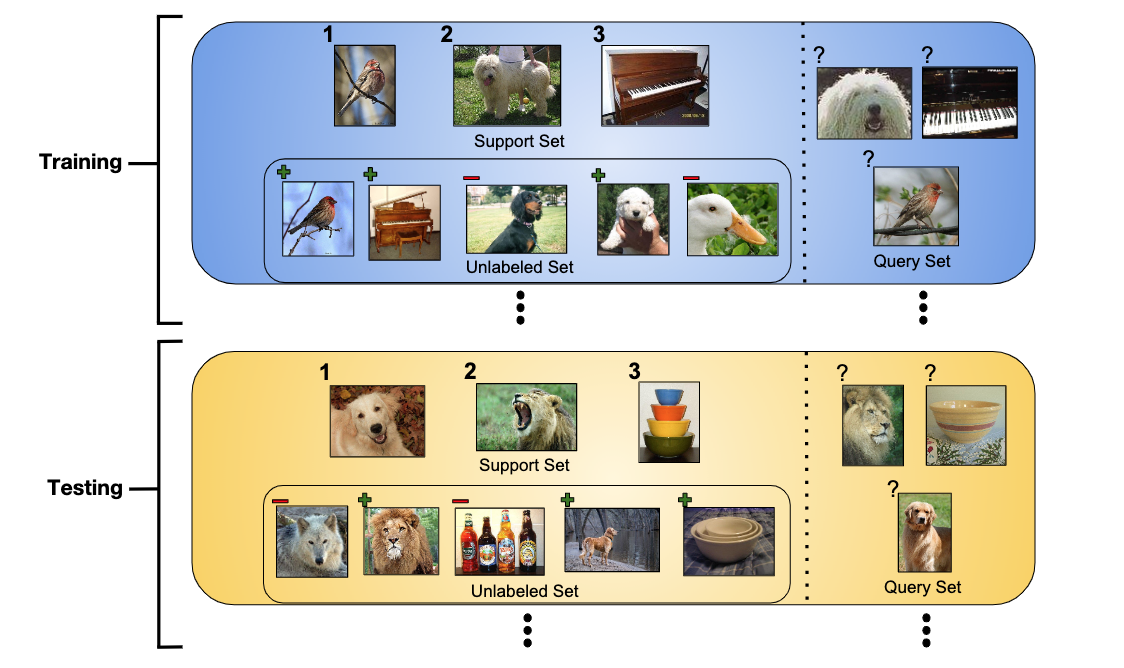
This paper proposes three novel extensions of Prototypical Networks, a SOTA approach to few-shot learning, to the semi-supervised setting. More precisely, Prototypical Nets learn an embedding function h(x), parameterized as a neural network, that maps examples into space where examples from the same class are close and those from different classes are far.
本文提出了原型网络的三个新颖的扩展,这是一种针对少数镜头学习的SOTA方法,可以将其扩展到半监督环境。 更准确地说,原型网络学习了一个嵌入函数h(x),该函数被参数化为神经网络,该函数将示例映射到空间中,其中来自同一类别的样本接近而来自不同类别的样本则远离。
To compute the prototype p_c of each class c, Prototypical Nets average the embedded examples per-class:
为了计算每个类c的原型p_c,原型网平均每个类的嵌入式示例:
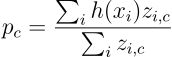
These prototypes define a predictor for the class of any query example x*, which assigns a probability over any class c based on the distance between x* and each prototype, as follows:
这些原型为任何查询示例x *的类定义了一个预测变量,它根据x *与每个原型之间的距离为任何类c分配概率,如下所示:
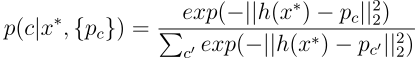
The loss function used to update Prototypical Networks for a given training episode is simply the average negative log-probability of the correct class assignments, for all query examples:
对于所有查询示例,用于为给定训练情节更新原型网络的损失函数只是正确班级分配的平均负对数概率:
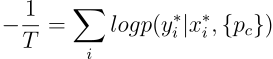
Training includes minimizing the average loss, iterating over training episodes, and performing a gradient descent update.
训练包括使平均损失最小化,遍历训练情节以及执行梯度下降更新。
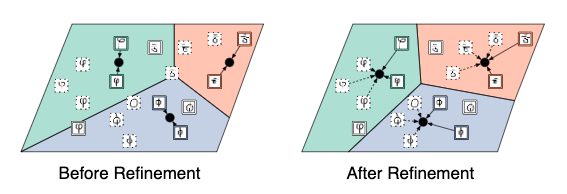
In the original formulation, Prototypical Networks (seen in the left side of the figure below) do not specify a way to leverage the unlabeled set R. The extensions start from the basic definition of prototypes and provide a procedure to produce refined prototypes (seen in the right side of the figure below) using the unlabeled examples in R.
在原始表述中,原型网络(如下图左侧所示)未指定利用未标记集合R的方法。扩展从原型的基本定义开始,并提供了生成精制原型的过程(参见下图的右侧)使用R中未标记的示例。
After the refined prototypes are generated, each query example is classified into one of the N classes based on the proximity of its embedded position with corresponding refined prototypes. During training, the authors optimize the average negative log-probability of the correct classification.
生成精炼原型后,根据每个查询示例的嵌入位置与相应精炼原型的接近程度,将其分类为N个类之一。 在训练过程中,作者优化了正确分类的平均负对数概率。
The first extension was borrowed from the inference performed by soft k-means.
第一个扩展是从软k均值的推论中借用的。
- The regular Prototypical Network’s prototypes p_c are used as the cluster locations. 常规原型网络的原型p_c用作群集位置。
- Then, the unlabeled examples get a partial assignment to each cluster based on their Euclidean distance to the cluster locations. 然后,未标记的示例会根据它们到簇位置的欧几里得距离,对每个簇进行部分分配。
- Finally, refined prototypes are obtained by incorporating these unlabeled examples. 最后,通过合并这些未标记的示例获得精制的原型。
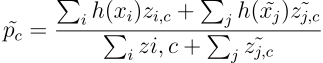
The partial assignment is defined as follows:
部分分配的定义如下:
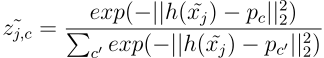
The extension above assumes that each unlabeled example belongs to either one of the N classes in the episode. However, it would be more general not to make that assumption and have a model robust to the existence of examples from other classes, termed distractor classes.
上面的扩展假定每个未标记的示例都属于情节中的N个类别之一。 但是,更普遍的做法是不做这种假设,并建立一个模型来抵抗来自其他类别(称为干扰项类别)的示例的存在。
The second extension added cluster to the assignment, whose purpose is to capture the distractors, thus preventing them from polluting the clusters of the classes of interest:
第二个扩展将集群添加到分配中,其目的是捕获干扰项,从而防止它们污染关注类的集群:

The third extension incorporated a soft-masking mechanism on the contributions of unlabeled examples. The idea is to make the unlabeled examples that are closer to a prototype to be masked less than those that are farther:
第三扩展在未标记的示例中加入了软掩蔽机制。 这样做的目的是使距离原型更近的未标记示例要比距离更远的那些蒙版更少:
- First, normalized distances d_{j,c} are computed between examples xⱼ and prototypes p_c. 首先,在实例x 1和原型p_c之间计算归一化的距离d_ {j,c}。
- Then, soft thresholds β_c and slopes γ_c are predicted for each prototype by feeding a small neural network various statistics of the normalized distances for the prototype. 然后,通过为小型神经网络提供原型的标准化距离的各种统计数据,为每个原型预测软阈值β_c和斜率γ_c。
- Finally, soft masks m_{j, c} for the contribution of each example to each prototype are computed by comparing to the threshold the normalized distances. 最后,通过将归一化距离与阈值进行比较,计算出每个示例对每个原型的贡献的软掩模m_ {j,c}。
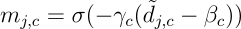
The refined prototypes are obtained as follows:
精制的原型如下所示:
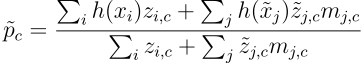
From the experiments conducted on Omniglot, miniImageNet, and tieredImageNet, these extensions of Prototypical Networks showed consistent improvements under semi-supervised settings compared to their baselines. For future work, the authors want to incorporate fast weights into their framework so that examples can have different embedding representations given the contents in the episode.
通过在Omniglot , miniImageNet和tieredImageNet上进行的实验,原型网络的这些扩展显示出与它们的基准相比,在半监督设置下具有一致的改进。 对于以后的工作,作者希望将快速权重纳入其框架,以便给定情节中的内容,示例可以具有不同的嵌入表示。
7 —元集群(2019年) (7 — Meta-Clustering (2019))
Jiang and Verma propose a simple yet highly effective meta-learning model to solve for clustering tasks. The model, called Meta-Clustering, finds the cluster structure directly without having to choose a specific cluster loss for each new clustering problem. There are two key challenges in training such a model for clustering:
Jiang和Verma提出了一个简单而高效的元学习模型来解决聚类任务。 该模型称为Meta-Clustering ,可以直接找到集群结构,而不必为每个新的集群问题选择特定的集群损失。 训练这种集群模型存在两个主要挑战:
- Since clustering is fundamentally an unsupervised task, true cluster identities for each training task don’t exist. 由于聚类从根本上说是一项无监督的任务,因此不存在每个训练任务的真实聚类标识。
- The cluster label for each new data point depends upon the labels assigned to other data points in the same clustering task. 每个新数据点的群集标签取决于在同一群集任务中分配给其他数据点的标签。
To address these issues, the authors:
为了解决这些问题,作者:
- Train their algorithm on simple synthetically generated datasets or other real-world labeled datasets with similar characteristics to generalize to real previously unseen datasets. 在简单的合成生成的数据集或其他具有类似特征的现实世界中标记的数据集上训练他们的算法,以推广到以前从未见过的真实数据集。
- Use a recurrent network (LSTMs) and train it sequentially to assign clustering labels effectively based on previously seen data points. 使用递归网络(LSTM)并对其进行顺序训练,以根据先前看到的数据点有效地分配聚类标签。
The problem is formally defined as follows: A meta-clustering model M maps data points to cluster labels. The model is trained to adapt to a set of clustering tasks {Tᵢ}. At the end of meta-training, M would produce clustering labels for new test tasks T_test.
问题的形式如下:元集群模型M将数据点映射到集群标签。 训练模型以适应一组聚类任务{Tᵢ}。 在元训练结束时,M将为新的测试任务T_test生成聚类标签。
- Each training task Tᵢ consists of a set of data points X_i and their associated cluster labels L_i. 每个训练任务T 1包括一组数据点X_i及其关联的簇标签L_i。
- X_i and L_i are partitioned into subsets based on cluster identities. X_i和L_i基于群集标识被划分为子集。
- The structure of the test task T_test is different from training and consists of only a set of data points X_test. 测试任务T_test的结构与训练不同,仅包含一组数据点X_test。
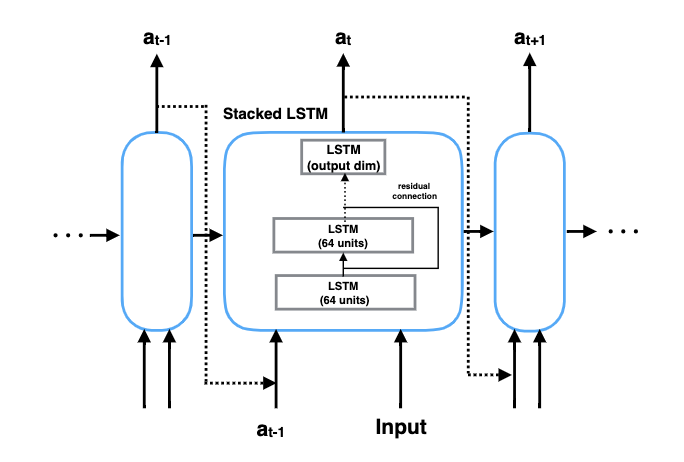
As seen above, Meta-Clustering uses a Long-Short Term Memory (LSTM) network to capture long-range dependencies between cluster identity for a current data point and the identities assigned to its neighbors.
如上所述,Meta-Clustering使用长短期内存(LSTM)网络来捕获当前数据点的群集标识和分配给其相邻节点的标识之间的长期依赖关系。
- At each time step t, the LSTM module takes in a data point x and a score vector a_{t-1} from previous time step t — 1 and outputs a new score a_t for the current time step. The score vector encodes the quality of the predicted label assigned to the data point x. 在每个时间步t处,LSTM模块都从前一个时间步t_1中获取一个数据点x和一个得分向量a_ {t-1},并为当前时间步输出一个新的得分a_t。 得分矢量对分配给数据点x的预测标签的质量进行编码。
- The network includes 4 LSTMs layers stacked on top of each other. The first three layers all have 64 units with residual connections, while the last layer can have the number of hidden units as either the number of clusters or the max number of possible clusters. 该网络包括相互堆叠的4个LSTM层。 前三层均具有64个带有剩余连接的单元,而最后一层可以具有隐藏单元数,即群集数或最大可能群集数。
Meta-Clustering optimizes for a loss function that combines classification loss (L_classify) and local loss (L_local):
元聚类针对组合分类损失(L_classify)和局部损失(L_local)的损失函数进行优化:
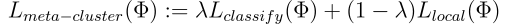
Φ refers to the architecture’s parameters, and λ refers to a hyper-parameter that controls the trade-off between the two losses.
Φ是架构的参数,而λ是控制两个损耗之间权衡的超参数。
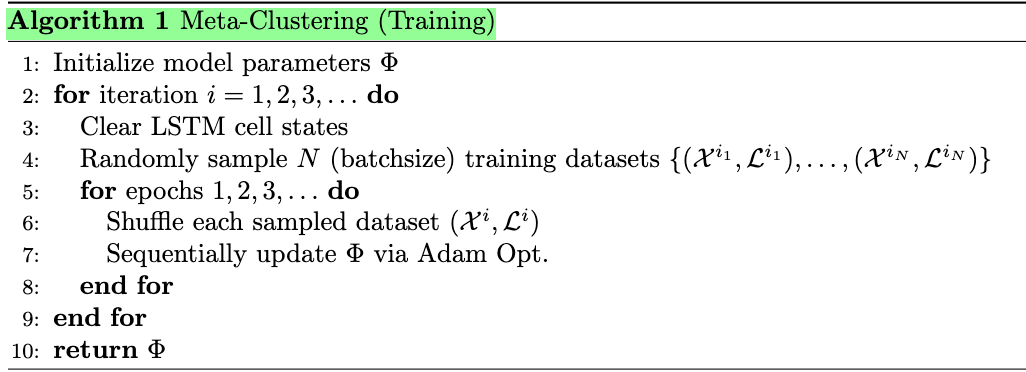
During each iteration in training, Meta-Clustering samples a batch of training data from the given pool of training tasks and feeds them into the LSTM network sequentially. The LSTM cell states are kept across epochs, enabling the LSTM network to remember the previously seen data points.
在训练的每个迭代期间,Meta-Clustering从给定的训练任务池中采样一批训练数据,并将它们顺序地馈入LSTM网络。 LSTM单元状态在各个时期之间保持不变,从而使LSTM网络能够记住以前看到的数据点。

During testing, the LSTM network takes into each test task as inputs and returns the clustering as outputs. The data points in each dataset are shuffle across iterations to prevent potential prediction errors introduced by specific sequence orders.
在测试期间,LSTM网络将每个测试任务作为输入,并将聚类作为输出返回。 每个数据集中的数据点在整个迭代过程中都会混排,以防止特定序列顺序引入潜在的预测错误。
From experiments on various synthetic and real-world data, Meta-Clustering achieves better clustering results than by using prevalent pre-existing linear and non-linear benchmark cluster losses. Additionally, Meta-Clustering can transfer its clustering ability to unseen datasets when trained on labeled real datasets of different distributions. Finally, Meta-Clustering is capable of approximating the right number of clusters in simple tasks and reducing the need to pre-specify the number of clusters.
通过对各种合成数据和现实世界数据进行的实验,与使用普遍存在的线性和非线性基准群集损失相比,元群集获得了更好的群集结果。 此外,当在不同分布的带标签的真实数据集上进行训练时,Meta-Clustering可以将其聚类能力转移到看不见的数据集。 最后,Meta-Clustering能够在简单的任务中近似估计正确的群集数量,并减少预先指定群集数量的需求。
8 —自我批评与适应(2020) (8 — Self-Critique and Adapt (2020))
Antoniou and Storkey (the same authors of AAL) came up with Self-Critique and Adapt (SCA for short) that frames the problem of learning a loss-function using the set-to-set few-shot learning framework.
Antoniou和Storkey (AAL的相同作者)提出了“自我批评和适应” ( Self-Critique and Adapt,简称SCA)的框架,该框架提出了使用按组设置的几次射击学习框架来学习损失函数的问题。
- SCA enables meta-learning-based few-shot systems to learn not only from the support-set input-output pairs but also from the target-set inputs, by learning a label-free loss function, parameterized as a neural network. 通过学习无标签损失函数(通过参数化为神经网络),SCA使基于元学习的短镜头系统不仅可以从支持集输入输出对中学习,而且还可以从目标集输入中学习。
- Doing so grants the models the ability to learn from the target-set input data points, by merely computing a loss, conditioned on base-model predictions of the target set. 这样做使模型能够通过仅计算损失(以目标集的基础模型预测为条件)来从目标集输入数据点学习。
- The label-free loss can be used to compute gradients for the model, and the gradients can then be used to update the base-model at inference time, to improve generalization performance. 无标签损失可用于计算模型的梯度,然后可将梯度用于在推理时更新基本模型,以提高泛化性能。
- Furthermore, SCA is model-agnostic and can be applied on top of any end-to-end differentiable, gradient-based, meta-learning method that uses the inner-loop optimization process to acquire task-specific information. 此外,SCA与模型无关,可以应用在任何使用内环优化过程来获取特定于任务的信息的端到端可微分的基于梯度的元学习方法之上。
A unique proposition of SCA is that it follows a transductive learning approach, which benefits from unsupervised information from the test example points and specification by knowing where we need to focus on model capability.
SCA的独特主张是它采用了一种转导式学习方法,该方法通过了解我们需要关注模型功能的位置而受益于来自测试示例点和规范的无监督信息。

As displayed in the figure above:
如上图所示:
- SCA takes a base-model, updates it for the support-set with an existing gradient-based meta-learning method, and then infers predictions for the target-set. SCA采用一个基本模型,使用现有的基于梯度的元学习方法为支持集更新它,然后推断目标集的预测。
-
Once the predictions have been inferred, they are concatenated along with other based-model related information and are then passed to a learnable critic loss network. This critic network computes and returns a loss for the target-set.
推断出预测之后,会将它们与其他与基于模型的信息相关联,然后传递到可学习的评论家损失网络。 该批评者网络计算并返回目标集的损失。
- The base-model is then updated with SGD for this critic loss. 然后针对此批评家损失,使用SGD更新基本模型。
This inner-loop optimization produces a predictive model specific to the support and target-set information. The quality of the inner loop learned predictive model is evaluated using ground truth labels from the training tasks. The outer loop then optimizes the initial parameters and the critic loss to maximize the quality of the inner loop predictions.
这种内循环优化可生成特定于支持和目标集信息的预测模型。 使用训练任务中的地面真相标签评估内环学习预测模型的质量。 然后,外循环优化初始参数和注释丢失,以最大化内循环预测的质量。

The SCA algorithm is demonstrated to the left in the paper. The base model of choice is MAML++, which is parametrized as f(θ). The critic loss network is parameterized as C(W). The goal is to learn acceptable parameters θ and W such that f can achieve good generalization performance on the target set T after being optimized for the loss on the support set S.
本文左侧展示了SCA算法。 选择的基本模型是MAML ++ ,其参数化为f(θ)。 The critic loss network is parameterized as C(W). The goal is to learn acceptable parameters θ and W such that f can achieve good generalization performance on the target set T after being optimized for the loss on the support set S.
From experiments on the miniImageNet and Caltech-UCSD Birds 200 datasets, the authors found that the critic network can improve well-established gradient-based meta-learning baselines. Some of the most useful conditional information for the critic model were the base model’s predictions, a relational task embedding, and a relational support-target-set network.
From experiments on the miniImageNet and Caltech-UCSD Birds 200 datasets, the authors found that the critic network can improve well-established gradient-based meta-learning baselines. Some of the most useful conditional information for the critic model were the base model's predictions, a relational task embedding, and a relational support-target-set network.
结论 (Conclusion)
In this post, I have discussed the motivation for unsupervised meta-learning and the six papers that incorporate this learning paradigm into their meta-learning workflow. In particular, these papers can be classified into two camps:
In this post, I have discussed the motivation for unsupervised meta-learning and the six papers that incorporate this learning paradigm into their meta-learning workflow. In particular, these papers can be classified into two camps:
-
CACTUs, UMTRA, AAL, and Unsupervised Meta-RL belong to the broad Unsupervised Meta-Learning camp. This camp aims to relax the conventional assumption of an annotated set of source tasks for meta-training, while still producing a good downstream performance of supervised few-shot learning. Typically, these synthetic source tasks are constructed without supervision via clustering (CACTUs) or class-preserving data augmentation (UMTRA and AAL).
CACTUs, UMTRA, AAL, and Unsupervised Meta-RL belong to the broad Unsupervised Meta-Learning camp. This camp aims to relax the conventional assumption of an annotated set of source tasks for meta-training, while still producing a good downstream performance of supervised few-shot learning. Typically, these synthetic source tasks are constructed without supervision via clustering (CACTUs) or class-preserving data augmentation (UMTRA and AAL).
-
Unsupervised Update Rules, Meta-Semi-Supervised Learning, Meta-Clustering, and SCA belong to the Meta-Learning Unsupervised Learning camp. This camp aims to use meta-learning to train unsupervised learning algorithms (Unsupervised Update Rules and Meta-Clustering) or loss functions (SCA) that work well for downstream supervised learning tasks. This helps deal with the ill-defined-ness of the unsupervised learning problem by transforming it into a problem with a clear meta supervised objective.
Unsupervised Update Rules, Meta-Semi-Supervised Learning, Meta-Clustering, and SCA belong to the Meta-Learning Unsupervised Learning camp. This camp aims to use meta-learning to train unsupervised learning algorithms (Unsupervised Update Rules and Meta-Clustering) or loss functions (SCA) that work well for downstream supervised learning tasks. This helps deal with the ill-defined-ness of the unsupervised learning problem by transforming it into a problem with a clear meta supervised objective.
Stay tuned for part 4 of this series, where I’ll cover Active Learning!
Stay tuned for part 4 of this series, where I'll cover Active Learning!
If you would like to follow my work on Recommendation Systems, Deep Learning, MLOps, and Data Journalism, you can follow my Medium and GitHub, as well as other projects at https://jameskle.com/. You can also tweet at me on Twitter, email me directly, or find me on LinkedIn. Or join my mailing list to receive my latest thoughts right at your inbox!
If you would like to follow my work on Recommendation Systems, Deep Learning, MLOps, and Data Journalism, you can follow my Medium and GitHub , as well as other projects at https://jameskle.com/ . You can also tweet at me on Twitter , email me directly , or find me on LinkedIn . Or join my mailing lis t to receive my latest thoughts right at your inbox!






 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)