联邦学习基础笔记(王树森视频)
王树森视频学习笔记:联邦学习与传统分布式机器学习的区别、联邦学习的研究分析
联邦学习的基础理解
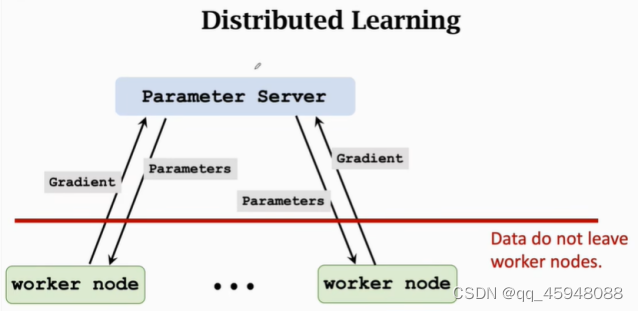
图1 分布式学习
联邦学习和传统分布式机器学习没有本质区别,如图1所示,结构可以分为Worker和Server,计算主要由worker完成,Server端存储模型参数并且更新模型参数,Server端的计算量很小,为了使得模型算法收敛,需要迭代更新参数进行梯度下降,具体迭代过程如下:Serve向worker传递模型参数Paramenters,worker利用本地数据和模型参数计算梯度,然后worker向Server传递梯度Gradient,Server端利用梯度信息更新模型参数。整个迭代过程并没有传输数据
但联邦学习和传统的分布式机器学习还是存在区别的,联邦学习和分布式机器学习的不同之处:
- 用户对自己的设备和数据有绝对的控制权,用户可以随时停止自己的设备参与训练,分布式机器学习Worker会受到Server的控制,Worker接受Server的指令,比如交换数据将数据打散(实现数据独立同分布)
- Worker节点的设备不稳定(所以减小通信次数很重要),计算能力不同,往往是一些手机、iPad或智能家居设备,可能会随时断网或者没有电,传统分布式机器学习参与的Worker结点设备往往是机房内相同的计算机,会24小时开机有专人维护,计算能力还一样。
- 联邦学习通信代价很大(所以减小通信次数很重要),需要进行远距离信息传输,远远大于计算代价,传统分布式机器学习结点是链接起来的,比如网线、高速宽带,传输代价非常小
- 联邦学习数据并非独立同分布,数据的分布可能不均匀,传统分布式机器学习数据时可以进行打散是独立同分布的。
- 联邦学习的节点负载不平衡,数据数量分布不均匀,容以造成计算时间不平衡。
降低联邦学习的通信次数(FedAvg):已经存在很多降低通信次数的算法。理念都是多做计算少做通信,如:worker结点收到参数后利用本地数据计算在本地做很多计算,从而得到比梯度更好的下降方向传给Server(本地计算几轮?),Server利用这个下降方向更快地更新模型参数。如图2所示FedAvg收到模型参数进行本地计算,计算多个epoch得到对模型参数更新并传给Server,Server收到这些更新后的参数来更新SerVer端地模型参数。
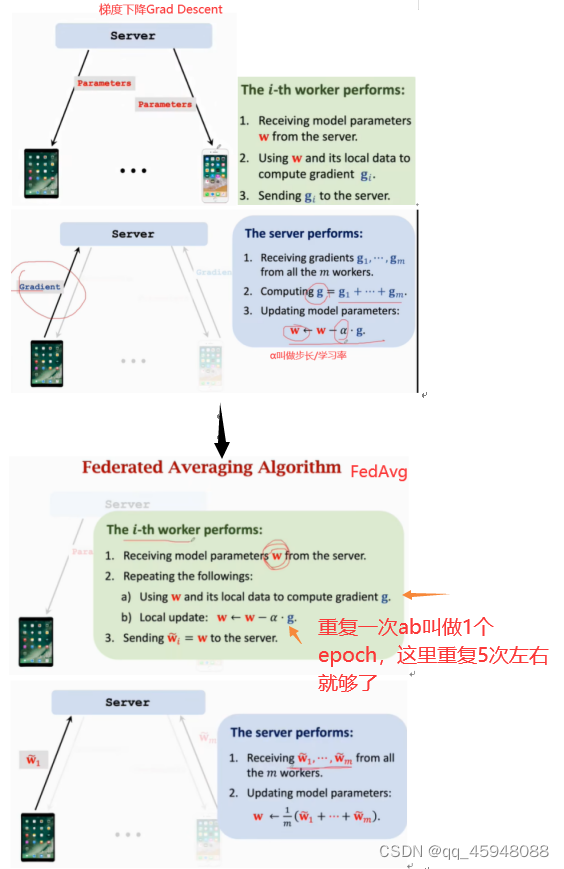
图2 从Grad Descent到FedAvg地改进(FedAvg以牺牲计算量为代价减少通信次数)
(每次把本地数据扫一遍叫做1个epoch,ab步骤1到5个epoch就好了,重复太多也不好)
两种方法对比图:
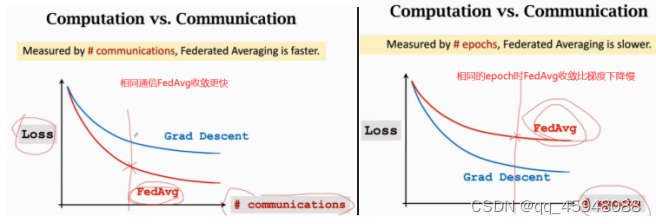
图3 结果对比
联邦学习以牺牲计算量减少通信代价,但联邦学习地主要代价就是通信代价。
联邦学习中的隐私保护:传输的梯度、参数是数据的映射,是数据的一个变换,携带了几乎用户所有的数据信息,用梯度或者参数是可以反推出来数据信息或者属性,所以存在数据隐私安全。通常解决方法是在梯度和参数中添加噪声,但此操作会降低准确度的百分点,收敛速度也会下降,噪声过大过小都不好,所以添加噪声往往不是一种好的方法。所以隐私保护方面比较困难(视频中作者使用随机矩阵变换的方法来研究联邦学习的隐私保护 )。
联邦学习的鲁棒性:让联邦学习可以抵御拜占庭错误(也就是Worker中出现了叛徒,出现异常结点的情况,比如其中一个结点发生故障或者故意修改自己的标签和数据,此时节点传给Server的梯度和参数就是错误或者有害的的信息,会造成Server学习到的模型是错误的或者有害的或者是留有后门的)和恶意的功击,如果数据是独立同分布的,那么这个异常结点可以比较容易的检测出来,但联邦学习的数据往往不是独立同分布的。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)