编译原理课程设计实验 4:语义分析和中间代码生成器-赋值表达式
本文实现了一个递归下降翻译器,用于处理赋值语句的语义分析和中间代码生成。系统包含词法分析、语法分析和语义分析模块,最终生成四元式中间代码。针对测试表达式"a=6/b+5*c-d",程序成功完成了词法分析、语法分析、语义分析、输出处理。
目录
二、Python代码实现语义分析和中间代码生成器-赋值表达式
一、实验要求
根据前面实验内容的Python代码(可以参考我的《编译原理课程设计》专栏,里面有实现词法分析和语法分析的源代码),添加功能实现递归下降翻译器。
注意
数据结构:
四元式:结构体
四元式序列:结构体数组
跳转语句的四元式的第 4 个域需回填。
翻译模式
1. 赋值语句的翻译
说明:
设文法符号为 X,其属性如下:
X.place:存放 X 值的变量的名字;
X.inArray:指向符号表中相应标识符表项的指针,若不使用符号表,则 X.inArray 即为标识符。
函数 emit( ):生成四元式语句;
函数 newtemp( ): 生成一个临时变量的名字,如 t1。
测试:
输入要测试的代码到"test4.txt"文件中:
a=6/b+5*c-d;
输出内容到控制台、"词法分析.txt"文件、"语法分析.txt"文件与"语义分析.txt"文件:
词法分析:
<111, a>
<46, ->
<100, 6>
<44, ->
<111, b>
<41, ->
<100, 5>
<43, ->
<111, c>
<42, ->
<111, d>
<84, ->
语法分析:
1) 按使用产生式过程
(1)stmts ⟶ stmt rest0
(2)stmt ⟶ loc = expr ;
(3)loc ⟶ id resta
(4)resta ⟶ ε
(5)expr ⟶ term rest5
(6)term ⟶ unary rest6
(7)unary ⟶ factor
(8)factor ⟶ num
(9)rest6 ⟶ / unary rest6
(10)unary ⟶ factor
(11)factor ⟶ loc
(12)loc ⟶ id resta
(13)resta ⟶ ε
(14)rest6 ⟶ ε
(15)rest5 ⟶ + term rest5
(16)term ⟶ unary rest6
(17)unary ⟶ factor
(18)factor ⟶ num
(19)rest6 ⟶ * unary rest6
(20)unary ⟶ factor
(21)factor ⟶ loc
(22)loc ⟶ id resta
(23)resta ⟶ ε
(24)rest6 ⟶ ε
(25)rest5 ⟶ - term rest5
(26)term ⟶ unary rest6
(27)unary ⟶ factor
(28)factor ⟶ loc
(29)loc ⟶ id resta
(30)resta ⟶ ε
(31)rest6 ⟶ ε
(32)rest5 ⟶ ε
(33)rest0 ⟶ ℇ
2) 按推导过程
(1) stmts
(2) stmt rest0
(3) loc = expr ; rest0
(4) id resta = expr ; rest0
(5) id = term rest5 ; rest0
(6) id = unary rest6 rest5 ; rest0
(7) id = factor rest6 rest5 ; rest0
(8) id = num rest6 rest5 ; rest0
(9) id = num / unary rest6 rest5 ; rest0
(10) id = num / factor rest6 rest5 ; rest0
(11) id = num / loc rest6 rest5 ; rest0
(12) id = num / id resta rest6 rest5 ; rest0
(13) id = num / id + term rest5 ; rest0
(14) id = num / id + unary rest6 rest5 ; rest0
(15) id = num / id + factor rest6 rest5 ; rest0
(16) id = num / id + num rest6 rest5 ; rest0
(17) id = num / id + num * unary rest6 rest5 ; rest0
(18) id = num / id + num * factor rest6 rest5 ; rest0
(19) id = num / id + num * loc rest6 rest5 ; rest0
(20) id = num / id + num * id resta rest6 rest5 ; rest0
(21) id = num / id + num * id - term rest5 ; rest0
(22) id = num / id + num * id - unary rest6 rest5 ; rest0
(23) id = num / id + num * id - factor rest6 rest5 ; rest0
(24) id = num / id + num * id - loc rest6 rest5 ; rest0
(25) id = num / id + num * id - id resta rest6 rest5 ; rest0
语法分析完成,结果已保存到"语法分析.txt"文件中。
语义分析:
生成的四元式:
0: /, 6, b, t1
1: *, 5, c, t2
2: +, t1, t2, t3
3: -, t3, d, t4
4: =, t4, -, a
文法
语义动作,格式:{语义分析}
stmts⟶stmt
rest0
{rest0.inNextlist=stmt.nextlist}
{stmts.nextlist=rest0.nextlist}
rest0 ⟶m stmt
rest01
{backpatch(rest0.inNextlist, m.quad);
rest01.inNextlist=stmt.nextlist}
{rest0.nextlist=rest01.nextlist}
rest0 ⟶ℇ
{rest0.nextlist=rest0.inNextlist}
stmt⟶loc=expr ;
{if(loc.offset=null)
emit( ‘=,’ expr.place ‘, - ,’ loc.place);
else
emit(‘[]=,’ expr.place ‘, - ,’ loc.place ‘[’ loc.offset ‘]’ );
stmt.nextlist=makelist()}
stmt⟶if(bool) m1 stmt1 n else m2 stmt2 {backpatch(bool.truelist, m1.quad);
backpatch(bool.falselist, m2.quad);
stmt.nextlist=
merge(stmt1.nextlist, n.nextlist, m2.nextlist)}
stmt⟶ while(m1 bool) m2 stmt1
{backpatch(stmt1.nextlist, m1.quad);
backpatch(bool.truelist, m2.quad);
stmt.nextlist=bool.falselist;
emit( ‘j, -, -, ’ m1.quad)}
m⟶ℇ
{m.quad=nextquad}
n⟶ℇ
{n.nextlist=makelist(nextquad);
emit( ‘j, -, -, 0’)}
loc⟶id
resta
{resta.inArray=id.place}
{loc.place=resta.place;
loc.offset=resta.offset}
resta⟶[
elist
]
{elist.inArray=resta.inArray}
{resta.place=newtemp();
emit(‘-,’ elist.arry ‘,’ C ‘,’ resta.place);
resta.offset=newtemp();
emit(‘*, ’ w ‘,’ elist.offset ‘,’ resta.offset);
}
resta⟶ℇ
{resta.place=resta.inArray;
resta.offset=null}
elist ⟶expr
rest1
{rest1.inArray=elist.inArray;
rest1.inNdim=1;
rest1.inPlace=expr.place}
{elist.array=rest1.array;
elist.offset=rest1.offset}
rest1⟶ ,
expr
rest11
{t=newtemp();
m=rest1.inNdim+1;
emit(‘*,’ rest1.inPlace ‘,’ limit(rest1.inarray,m) ‘,’ t);
emit(‘+,’ t ‘,’ expr.place ‘,’ t);
rest11.inArray=rest1.inArray;
rest11.inNdim=m;
rest11.inNplace=t}
{rest1.array=rest11.array;
rest1.offset=rest11.offset}
rest1⟶ℇ
{rest1.array=rest1.inArray;
rest1.offset=rest1.inPlace}
bool ⟶ equality
{bool.truelist=equality.truelist
bool.falselist=equality.falselist }
equality ⟶ rel
rest4
{rest4.inTruelist=rel.truelist
rest4.inFalselist=rel.falselist}
{equality.truelist=rest4.truelist
equality.falselist=rest4.falselist}
rest4 ⟶ == rel rest41
rest4 ⟶ != rel rest41
rest4 ⟶ ℇ
{rest4.truelist=rest4.inTruelist
rest4.falselist=rest4.inFalselist}
rel ⟶ expr
rop_expr
{rop_expr.inPlace=expr.place}
{rel.truelist=rop_expr.truelist
rel.falselist=rop_expr.falselist}
rop_expr ⟶ <expr
{rop_expr.truelist=makelist(nextquad);
rop_expr.falselist=makelist(nextquad+1);
emit(‘j<,’ rop_expr.inPlace ‘,’ expr.place ‘, -’);
emit(‘j, -, -, -’)}
rop_expr ⟶ <=expr
{rop_expr.truelist=makelist(nextquad);
rop_expr.falselist=makelist(nextquad+1);
emit(‘j<=,’ rop_expr.inPlace ‘,’ expr.place ‘, -’);
emit(‘j, -, -, -’)}
rop_expr ⟶ >expr
{rop_expr.truelist=makelist(nextquad);
rop_expr.falselist=makelist(nextquad+1);
emit(‘j>,’ rop_expr.inPlace ‘,’ expr.place ‘, -’);
emit(‘j, -, -, -’)}
rop_expr ⟶ >=expr
{rop_expr.truelist=makelist(nextquad);
rop_expr.falselist=makelist(nextquad+1);
emit(‘j>=,’ rop_expr.inPlace ‘,’ expr.place ‘, -’);
emit(‘j, -, -, -’)}
rop_expr ⟶ ℇ
{rop_expr.truelist=makelist(nextquad);
rop_expr.falselist=makelist(nextquad+1);
emit(‘jnz,’ rop_expr.inPlace ‘, -, -’);
emit(‘j, -, -, -’)}
expr ⟶ term
rest5
{rest5.in=term.place}
{expr.place=rest5.place}
rest5⟶ +term
rest51
{rest51.in=newtemp();
emit(‘+,’ rest5.in ‘,’ term.place ‘,’ rest51.in)}
{rest5.place =rest51 .place}
rest5⟶ -term
rest51
{rest51.in=newtemp();
emit(‘-,’ rest5.in ‘,’ term.place ‘,’ rest51.in)}
{rest5.place =rest51 .place}
rest5⟶ ℇ
{rest5.place = rest5.in}
term⟶ unary
rest6
{rest6.in = unary.place}
{term.place = rest6.place}
rest6⟶ *unary
rest61
{rest61.in=newtemp();
emit(‘*,’ rest6.in ‘,’ unary.place ‘,’ rest61.in)}
{rest6.place = rest61 .place}
rest6⟶ /unary
rest61
{rest61.in=newtemp();
emit(‘/,’ rest6.in ‘,’ unary.place ‘,’ rest61.in)}
{rest6.place = rest61 .place}
rest6⟶ ℇ
{rest6.place = rest6.in}
unary⟶factor
{unary.place = factor.place}
factor⟶ (expr)
{factor.place = expr.place}
factor⟶loc
{if(loc.offset=null)
factor.place = loc.place
else {factor.place=newtemp();
emit(‘=[],’ loc.place ‘[’ loc.offset ‘]’ ‘, -,’ factor.place )}}
factor⟶num
{factor.place = num.value}
二、Python代码实现语义分析和中间代码生成器-赋值表达式
# 种别码映射表
token_map = {
# 运算符
'+': 41, '-': 42, '*': 43, '/': 44, '%': 45, '=': 46,
'>': 47, '>=': 48, '<': 49, '<=': 50, '==': 51, '!=': 52,
'&&': 53, '||': 54, '!': 55, '++': 56, '--': 57,
# 输出和输入符号
'<<': 90, '>>': 91,
# 关键字
'int': 5, 'else': 15, 'if': 17, 'while': 20, 'double': 21,
'string': 22, 'char': 23, 'include': 24, 'using': 25,
'namespace': 26, 'std': 27, 'main': 28, 'return': 29,
'void': 30, 'iostream': 31, 'cin': 32, 'cout': 33, 'endl': 34
}
def Recognizestr(ch):
word = ""
while ch.isalnum() or ch == '_':
word += ch
ch = file.read(1)
# 关键字处理
code = token_map.get(word, None)
if code:
return ch, f'<{code}, ->'
return ch, f'<111, {word}>'
def RecognizeDigit(ch):
data = ""
while ch in {'0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '.'}:
data += ch
ch = file.read(1)
return ch, f'<100, {data}>'
def Recognizeop(ch):
op = ch
peek_ch = file.read(1)
# 处理双字符运算符
double_ops = {
'+': '+', '-': '-', '=': '=', '>': '=',
'<': '=', '!': '=', '&': '&', '|': '|',
}
# 特殊处理 << 和 >>
if op == '<' and peek_ch == '<':
op += peek_ch
ch = file.read(1)
elif op == '>' and peek_ch == '>':
op += peek_ch
ch = file.read(1)
# 处理其他双字符运算符
elif op in double_ops and peek_ch == double_ops[op]:
op += peek_ch
ch = file.read(1)
else:
ch = peek_ch
# 获取种别码
code = token_map.get(op, None)
if code:
return ch, f'<{code}, ->'
return ch, f'<{op}, {op}>'
def Recognizeoth(ch):
# 处理括号和单字符符号
if ch in {'(', ')', '[', ']', '{', '}', ';', ',', '#', '<', '>'}:
code_mapping = {
'(': 81, ')': 82, '[': 88, ']': 89,
'{': 86, '}': 87, ';': 84, ',': 83,
'#': 85, '<': 49, '>': 47, '<<': 90,
'>>': 91
}
code = code_mapping.get(ch, 0)
res = f'<{code}, ->' if code else f'<{ch}, {ch}>'
return file.read(1), res
# 处理逻辑运算符
if ch in {'&', '|'}:
next_ch = file.read(1)
if next_ch == ch:
code = 53 if ch == '&' else 54
return file.read(1), f'<{code}, ->'
return next_ch, '<error>'
return file.read(1), f'<{ch}, {ch}>'
import re
import os
from collections import namedtuple
# 定义Token类
class Token:
def __init__(self, type, value):
self.type = type
self.value = value
def __str__(self):
return f"{self.type}({self.value})"
# 四元式结构
class Quadruple:
def __init__(self, op, arg1, arg2, result):
self.op = op
self.arg1 = arg1
self.arg2 = arg2
self.result = result
def __str__(self):
return f"{self.op}, {self.arg1}, {self.arg2}, {self.result}"
# 属性信息结构
class Attribute:
def __init__(self, place=None, offset=None, array=None):
self.place = place # 存放值的变量名
self.offset = offset # 数组偏移量
self.array = array # 数组基地址
# 用于布尔表达式
self.truelist = [] # 真出口跳转链表
self.falselist = [] # 假出口跳转链表
# 用于控制流
self.nextlist = [] # 下一条语句跳转链表
# 临时变量,用于传递属性
self.inArray = None
self.inOffset = None
self.inPlace = None
self.inNextlist = None
self.inTruelist = None
self.inFalselist = None
self.inNdim = 0
self.quad = 0 # 用于记录当前四元式的位置
# 语义分析器 - 实现语法制导翻译
class SemanticAnalyzer:
def __init__(self):
# 初始化四元式表
self.quad_table = []
# 初始化临时变量计数器
self.temp_count = 0
def emit(self, op, arg1, arg2, result):
"""生成四元式并添加到四元式表"""
quad = Quadruple(op, arg1, arg2, result)
self.quad_table.append(quad)
return len(self.quad_table) - 1 # 返回四元式索引
def newtemp(self):
"""生成新的临时变量名"""
self.temp_count += 1
return f"t{self.temp_count}"
def nextquad(self):
"""返回下一个四元式的索引"""
return len(self.quad_table)
def makelist(self, i):
"""创建只包含i的链表"""
return [i] if i is not None else []
def merge(self, list1, list2):
"""合并两个链表"""
if list1 is None:
list1 = []
if list2 is None:
list2 = []
return list1 + list2
def backpatch(self, address_list, quad_index):
"""回填操作 - 将address_list中的所有地址回填为quad_index"""
for i in address_list:
if i < len(self.quad_table):
self.quad_table[i].result = str(quad_index)
def print_quadruples(self, output_file=None):
"""打印四元式表"""
output = []
for i, quad in enumerate(self.quad_table):
quad_str = f"{i}: {quad.op},\t{quad.arg1},\t{quad.arg2},\t{quad.result}"
output.append(quad_str)
print(quad_str)
if output_file:
try:
with open(output_file, 'w', encoding='utf-8') as f:
for line in output:
f.write(line + '\n')
except Exception as e:
print(f"保存四元式到文件时出错: {e}")
# 实际的语法和语义分析器
class CompleteSyntaxSemanticAnalyzer:
def __init__(self):
# 用于记录产生式步骤和推导步骤
self.production_steps = []
self.derivation_steps = []
self.step_count = 0
# 当前处理的tokens
self.tokens = []
self.current_token = None
self.token_index = 0
# 当前推导的句型
self.current_sentential = ["stmts"]
# 语义分析器
self.semantic = SemanticAnalyzer()
def add_production(self, production):
"""添加一条使用的产生式"""
self.step_count += 1
self.production_steps.append(production)
def add_derivation(self, sentential_form):
"""添加一个推导步骤"""
self.derivation_steps.append(" ".join(sentential_form))
def tokenize(self, text):
"""词法分析,将输入文本转换为token序列"""
tokens = []
# 定义token模式
patterns = [
(r'[ \t\n\r]+', None), # 忽略所有空白字符
(r'//.*', None), # 忽略注释
(r'while', 'WHILE'),
(r'if', 'IF'),
(r'else', 'ELSE'),
(r'[a-zA-Z_][a-zA-Z0-9_]*', 'ID'),
(r'[0-9]+', 'NUM'),
(r'\(', 'LPAREN'),
(r'\)', 'RPAREN'),
(r'\[', 'LBRACK'),
(r'\]', 'RBRACK'),
(r';', 'SEMICOLON'),
(r',', 'COMMA'),
(r'=', 'ASSIGN'),
(r'\+', 'PLUS'),
(r'-', 'MINUS'),
(r'\*', 'MUL'),
(r'/', 'DIV'),
(r'<', 'LT'),
(r'<=', 'LE'),
(r'>', 'GT'),
(r'>=', 'GE'),
(r'==', 'EQ'),
(r'!=', 'NE'),
(r'&&', 'AND'),
(r'\|\|', 'OR')
]
# 手动匹配每种模式
pos = 0
line = 1
column = 1
while pos < len(text):
match = None
# 尝试匹配每种模式
for pattern, token_type in patterns:
regex = re.compile(pattern)
m = regex.match(text, pos)
if m:
match = m
if token_type: # 如果不是要跳过的模式
value = m.group(0)
tokens.append(Token(token_type, value))
# 更新位置信息
matched_text = m.group(0)
newlines = matched_text.count('\n')
if newlines > 0:
line += newlines
column = len(matched_text) - matched_text.rindex('\n')
else:
column += len(matched_text)
pos = m.end()
break
if not match:
# 如果没有匹配到任何模式,报告错误并跳过当前字符
print(f"无法识别的字符: '{text[pos]}' 在行 {line} 列 {column}")
pos += 1
column += 1
return tokens
def get_token(self):
"""获取当前token"""
if self.token_index < len(self.tokens):
self.current_token = self.tokens[self.token_index]
self.token_index += 1
return self.current_token
else:
self.current_token = None
return None
def peek_token(self):
"""查看下一个token但不消耗它"""
if self.token_index < len(self.tokens):
return self.tokens[self.token_index]
return None
def match(self, expected_type):
"""匹配当前token类型"""
if self.current_token and self.current_token.type == expected_type:
token = self.current_token
self.get_token()
return token
else:
expected = expected_type
found = self.current_token.type if self.current_token else "EOF"
raise SyntaxError(f"语法错误: 期望 {expected},但得到 {found}")
def parse(self, text):
"""解析输入文本"""
try:
self.tokens = self.tokenize(text)
if not self.tokens:
print("警告: 没有识别到任何token,输入可能为空或仅包含空白字符")
return False
self.token_index = 0
self.get_token() # 初始化第一个token
self.production_steps = []
self.derivation_steps = []
self.step_count = 0
self.semantic = SemanticAnalyzer()
# 初始推导步骤
self.current_sentential = ["stmts"]
self.add_derivation(self.current_sentential)
stmts_attr = self.parse_stmts()
return True
except SyntaxError as e:
print(f"语法分析错误: {e}")
return False
except Exception as e:
print(f"解析过程中出现未知错误: {e}")
import traceback
traceback.print_exc()
return False
# 以下是语义分析器的解析函数,每个函数返回对应非终结符的属性
def parse_stmts(self):
"""解析stmts"""
# stmts ⟶ stmt rest0
self.add_production("stmts ⟶ stmt rest0")
# 更新推导
self.update_derivation("stmts", ["stmt", "rest0"])
# 语义动作
stmt_attr = self.parse_stmt()
rest0_attr = Attribute()
rest0_attr.inNextlist = stmt_attr.nextlist
rest0_attr = self.parse_rest0(rest0_attr)
# 为stmts创建属性
stmts_attr = Attribute()
stmts_attr.nextlist = rest0_attr.nextlist
return stmts_attr
def parse_rest0(self, inherited_attr):
"""解析rest0"""
rest0_attr = Attribute()
if self.current_token and self.current_token.type in ['ID', 'IF', 'WHILE']:
# rest0 ⟶ m stmt rest01
self.add_production("rest0 ⟶ m stmt rest01")
# 更新推导
self.update_derivation("rest0", ["m", "stmt", "rest01"])
# 语义动作
m_attr = self.parse_m()
self.semantic.backpatch(inherited_attr.inNextlist, m_attr.quad)
stmt_attr = self.parse_stmt()
rest01_attr = Attribute()
rest01_attr.inNextlist = stmt_attr.nextlist
rest01_attr = self.parse_rest0(rest01_attr)
# 为rest0创建属性
rest0_attr.nextlist = rest01_attr.nextlist
else:
# rest0 ⟶ ε
self.add_production("rest0 ⟶ ℇ")
# 更新推导
self.update_derivation("rest0", [])
# 语义动作
rest0_attr.nextlist = inherited_attr.inNextlist
return rest0_attr
def parse_m(self):
"""解析m - 标记当前位置用于回填"""
# m ⟶ ε
# 语义动作
m_attr = Attribute()
m_attr.quad = self.semantic.nextquad()
return m_attr
def parse_n(self):
"""解析n - 生成无条件跳转四元式"""
# n ⟶ ε
# 语义动作
n_attr = Attribute()
n_attr.nextlist = self.semantic.makelist(self.semantic.nextquad())
self.semantic.emit("j", "-", "-", "0") # 0会在回填时被替换
return n_attr
def parse_stmt(self):
"""解析stmt"""
stmt_attr = Attribute()
if self.current_token is None:
raise SyntaxError("语法错误: 意外的文件结束,期望一个语句")
if self.current_token.type == 'WHILE':
# stmt ⟶ while(m1 bool) m2 stmt1
self.add_production("stmt ⟶ while(m1 bool) m2 stmt1")
# 更新推导
self.update_derivation("stmt", ["while(m1", "bool)", "m2", "stmt1"])
# 语义动作
self.match('WHILE')
self.match('LPAREN')
m1_attr = self.parse_m()
bool_attr = self.parse_bool()
self.match('RPAREN')
m2_attr = self.parse_m()
stmt1_attr = self.parse_stmt()
# 语义动作
self.semantic.backpatch(stmt1_attr.nextlist, m1_attr.quad)
self.semantic.backpatch(bool_attr.truelist, m2_attr.quad)
stmt_attr.nextlist = bool_attr.falselist
self.semantic.emit("j", "-", "-", str(m1_attr.quad))
elif self.current_token.type == 'IF':
# stmt ⟶ if(bool) m1 stmt1 n else m2 stmt2
self.add_production("stmt ⟶ if(bool) m1 stmt1 n else m2 stmt2")
# 更新推导
self.update_derivation("stmt", ["if(bool)", "m1", "stmt1", "n", "else", "m2", "stmt2"])
# 语义动作
self.match('IF')
self.match('LPAREN')
bool_attr = self.parse_bool()
self.match('RPAREN')
m1_attr = self.parse_m()
stmt1_attr = self.parse_stmt()
n_attr = self.parse_n()
self.match('ELSE')
m2_attr = self.parse_m()
stmt2_attr = self.parse_stmt()
# 语义动作
self.semantic.backpatch(bool_attr.truelist, m1_attr.quad)
self.semantic.backpatch(bool_attr.falselist, m2_attr.quad)
stmt_attr.nextlist = self.semantic.merge(
self.semantic.merge(stmt1_attr.nextlist, n_attr.nextlist),
stmt2_attr.nextlist
)
elif self.current_token.type == 'ID':
# stmt ⟶ loc = expr ;
self.add_production("stmt ⟶ loc = expr ;")
# 更新推导
self.update_derivation("stmt", ["loc", "=", "expr", ";"])
# 语义动作
loc_attr = self.parse_loc()
self.match('ASSIGN')
expr_attr = self.parse_expr()
self.match('SEMICOLON')
# 语义动作 - 生成赋值四元式
if loc_attr.offset is None:
self.semantic.emit("=", expr_attr.place, "-", loc_attr.place)
else:
self.semantic.emit("[]=", expr_attr.place, "-", f"{loc_attr.place}[{loc_attr.offset}]")
stmt_attr.nextlist = self.semantic.makelist(None) # 空链表
else:
raise SyntaxError(f"语法错误: 无效的语句开始: {self.current_token.type}")
return stmt_attr
def parse_loc(self):
"""解析loc"""
# loc ⟶ id resta
self.add_production("loc ⟶ id resta")
# 更新推导
self.update_derivation("loc", ["id", "resta"])
# 语义动作
id_token = self.match('ID')
resta_attr = Attribute()
resta_attr.inArray = id_token.value
resta_attr = self.parse_resta(resta_attr)
# 为loc创建属性
loc_attr = Attribute()
loc_attr.place = resta_attr.place
loc_attr.offset = resta_attr.offset
return loc_attr
def parse_resta(self, inherited_attr):
"""解析resta"""
resta_attr = Attribute()
if self.current_token and self.current_token.type == 'LBRACK':
# resta ⟶ [elist]
self.add_production("resta ⟶ [ elist ]")
# 更新推导
self.update_derivation("resta", ["[", "elist", "]"])
# 语义动作
self.match('LBRACK')
elist_attr = Attribute()
elist_attr.inArray = inherited_attr.inArray
elist_attr = self.parse_elist(elist_attr)
self.match('RBRACK')
# 语义动作 - 计算偏移
resta_attr.place = self.semantic.newtemp()
self.semantic.emit("-", elist_attr.array, "C", resta_attr.place) # C是某个常量,这里简化处理
resta_attr.offset = self.semantic.newtemp()
self.semantic.emit("*", "w", elist_attr.offset, resta_attr.offset) # w是单元素大小
else:
# resta ⟶ ε
self.add_production("resta ⟶ ε")
# 更新推导
self.update_derivation("resta", [])
# 语义动作
resta_attr.place = inherited_attr.inArray
resta_attr.offset = None
return resta_attr
def parse_elist(self, inherited_attr):
"""解析elist"""
# elist ⟶ expr rest1
self.add_production("elist ⟶ expr rest1")
# 更新推导
self.update_derivation("elist", ["expr", "rest1"])
# 语义动作
expr_attr = self.parse_expr()
rest1_attr = Attribute()
rest1_attr.inArray = inherited_attr.inArray
rest1_attr.inNdim = 1
rest1_attr.inPlace = expr_attr.place
rest1_attr = self.parse_rest1(rest1_attr)
# 为elist创建属性
elist_attr = Attribute()
elist_attr.array = rest1_attr.array
elist_attr.offset = rest1_attr.offset
return elist_attr
def parse_rest1(self, inherited_attr):
"""解析rest1"""
rest1_attr = Attribute()
if self.current_token and self.current_token.type == 'COMMA':
# rest1 ⟶ , expr rest1
self.add_production("rest1 ⟶ , expr rest1")
# 更新推导
self.update_derivation("rest1", [",", "expr", "rest1"])
# 语义动作 - 这里简化处理多维数组
self.match('COMMA')
expr_attr = self.parse_expr()
# 递归处理rest1
# ...
else:
# rest1 ⟶ ε
self.add_production("rest1 ⟶ ε")
# 更新推导
self.update_derivation("rest1", [])
# 语义动作
rest1_attr.array = inherited_attr.inArray
rest1_attr.offset = inherited_attr.inPlace
return rest1_attr
def parse_bool(self):
"""解析bool"""
# bool ⟶ equality
self.add_production("bool ⟶ equality")
# 更新推导
self.update_derivation("bool", ["equality"])
# 语义动作
equality_attr = self.parse_equality()
# 为bool创建属性
bool_attr = Attribute()
bool_attr.truelist = equality_attr.truelist
bool_attr.falselist = equality_attr.falselist
return bool_attr
def parse_equality(self):
"""解析equality"""
# equality ⟶ rel rest4
self.add_production("equality ⟶ rel rest4")
# 更新推导
self.update_derivation("equality", ["rel", "rest4"])
# 语义动作
rel_attr = self.parse_rel()
rest4_attr = Attribute()
rest4_attr.inTruelist = rel_attr.truelist
rest4_attr.inFalselist = rel_attr.falselist
rest4_attr = self.parse_rest4(rest4_attr)
# 为equality创建属性
equality_attr = Attribute()
equality_attr.truelist = rest4_attr.truelist
equality_attr.falselist = rest4_attr.falselist
return equality_attr
def parse_rest4(self, inherited_attr):
"""解析rest4"""
rest4_attr = Attribute()
if self.current_token and self.current_token.type == 'EQ':
# rest4 ⟶ == rel rest41
self.add_production("rest4 ⟶ == rel rest41")
# 更新推导
self.update_derivation("rest4", ["==", "rel", "rest41"])
# 语义动作 - 这里简化处理
self.match('EQ')
self.parse_rel()
# 处理rest41...
elif self.current_token and self.current_token.type == 'NE':
# rest4 ⟶ != rel rest41
self.add_production("rest4 ⟶ != rel rest41")
# 更新推导
self.update_derivation("rest4", ["!=", "rel", "rest41"])
# 语义动作 - 这里简化处理
self.match('NE')
self.parse_rel()
# 处理rest41...
else:
# rest4 ⟶ ε
self.add_production("rest4 ⟶ ε")
# 更新推导
self.update_derivation("rest4", [])
# 语义动作
rest4_attr.truelist = inherited_attr.inTruelist
rest4_attr.falselist = inherited_attr.inFalselist
return rest4_attr
def parse_rel(self):
"""解析rel"""
# rel ⟶ expr rop_expr
self.add_production("rel ⟶ expr rop_expr")
# 更新推导
self.update_derivation("rel", ["expr", "rop_expr"])
# 语义动作
expr_attr = self.parse_expr()
rop_expr_attr = Attribute()
rop_expr_attr.inPlace = expr_attr.place
rop_expr_attr = self.parse_rop_expr(rop_expr_attr)
# 为rel创建属性
rel_attr = Attribute()
rel_attr.truelist = rop_expr_attr.truelist
rel_attr.falselist = rop_expr_attr.falselist
return rel_attr
def parse_rop_expr(self, inherited_attr):
"""解析rop_expr"""
rop_expr_attr = Attribute()
if self.current_token and self.current_token.type == 'LT':
# rop_expr ⟶ < expr
self.add_production("rop_expr ⟶ < expr")
# 更新推导
self.update_derivation("rop_expr", ["<", "expr"])
# 语义动作
self.match('LT')
expr_attr = self.parse_expr()
# 生成条件跳转四元式
rop_expr_attr.truelist = self.semantic.makelist(self.semantic.nextquad())
rop_expr_attr.falselist = self.semantic.makelist(self.semantic.nextquad() + 1)
self.semantic.emit("j<", inherited_attr.inPlace, expr_attr.place, "-")
self.semantic.emit("j", "-", "-", "-")
elif self.current_token and self.current_token.type == 'GT':
# rop_expr ⟶ > expr
self.add_production("rop_expr ⟶ > expr")
# 更新推导
self.update_derivation("rop_expr", [">", "expr"])
# 语义动作
self.match('GT')
expr_attr = self.parse_expr()
# 生成条件跳转四元式
rop_expr_attr.truelist = self.semantic.makelist(self.semantic.nextquad())
rop_expr_attr.falselist = self.semantic.makelist(self.semantic.nextquad() + 1)
self.semantic.emit("j>", inherited_attr.inPlace, expr_attr.place, "-")
self.semantic.emit("j", "-", "-", "-")
elif self.current_token and self.current_token.type == 'LE':
# rop_expr ⟶ <= expr
self.add_production("rop_expr ⟶ <= expr")
# 更新推导
self.update_derivation("rop_expr", ["<=", "expr"])
# 语义动作
self.match('LE')
expr_attr = self.parse_expr()
# 生成条件跳转四元式
rop_expr_attr.truelist = self.semantic.makelist(self.semantic.nextquad())
rop_expr_attr.falselist = self.semantic.makelist(self.semantic.nextquad() + 1)
self.semantic.emit("j<=", inherited_attr.inPlace, expr_attr.place, "-")
self.semantic.emit("j", "-", "-", "-")
elif self.current_token and self.current_token.type == 'GE':
# rop_expr ⟶ >= expr
self.add_production("rop_expr ⟶ >= expr")
# 更新推导
self.update_derivation("rop_expr", [">=", "expr"])
# 语义动作
self.match('GE')
expr_attr = self.parse_expr()
# 生成条件跳转四元式
rop_expr_attr.truelist = self.semantic.makelist(self.semantic.nextquad())
rop_expr_attr.falselist = self.semantic.makelist(self.semantic.nextquad() + 1)
self.semantic.emit("j>=", inherited_attr.inPlace, expr_attr.place, "-")
self.semantic.emit("j", "-", "-", "-")
else:
# rop_expr ⟶ ε
self.add_production("rop_expr ⟶ ε")
# 更新推导
self.update_derivation("rop_expr", [])
# 语义动作 - 在这里创建一个默认的条件测试
rop_expr_attr.truelist = self.semantic.makelist(self.semantic.nextquad())
rop_expr_attr.falselist = self.semantic.makelist(self.semantic.nextquad() + 1)
# 默认条件:非0为真
self.semantic.emit("j!=", inherited_attr.inPlace, "0", "-")
self.semantic.emit("j", "-", "-", "-")
return rop_expr_attr
def parse_expr(self):
"""解析expr"""
# expr ⟶ term rest5
self.add_production("expr ⟶ term rest5")
# 更新推导
self.update_derivation("expr", ["term", "rest5"])
# 语义动作
term_attr = self.parse_term()
rest5_attr = Attribute()
rest5_attr.inPlace = term_attr.place
rest5_attr = self.parse_rest5(rest5_attr)
# 为expr创建属性
expr_attr = Attribute()
expr_attr.place = rest5_attr.place
return expr_attr
def parse_rest5(self, inherited_attr):
"""解析rest5"""
rest5_attr = Attribute()
if self.current_token and self.current_token.type == 'PLUS':
# rest5 ⟶ + term rest51
self.add_production("rest5 ⟶ + term rest5")
# 更新推导
self.update_derivation("rest5", ["+", "term", "rest5"])
# 语义动作
self.match('PLUS')
term_attr = self.parse_term()
# 生成加法四元式
rest51_attr = Attribute()
rest51_attr.inPlace = self.semantic.newtemp()
self.semantic.emit("+", inherited_attr.inPlace, term_attr.place, rest51_attr.inPlace)
rest51_attr = self.parse_rest5(rest51_attr)
# 为rest5创建属性
rest5_attr.place = rest51_attr.place
elif self.current_token and self.current_token.type == 'MINUS':
# rest5 ⟶ - term rest51
self.add_production("rest5 ⟶ - term rest5")
# 更新推导
self.update_derivation("rest5", ["-", "term", "rest5"])
# 语义动作
self.match('MINUS')
term_attr = self.parse_term()
# 生成减法四元式
rest51_attr = Attribute()
rest51_attr.inPlace = self.semantic.newtemp()
self.semantic.emit("-", inherited_attr.inPlace, term_attr.place, rest51_attr.inPlace)
rest51_attr = self.parse_rest5(rest51_attr)
# 为rest5创建属性
rest5_attr.place = rest51_attr.place
else:
# rest5 ⟶ ε
self.add_production("rest5 ⟶ ε")
# 更新推导
self.update_derivation("rest5", [])
# 语义动作
rest5_attr.place = inherited_attr.inPlace
return rest5_attr
def parse_term(self):
"""解析term"""
# term ⟶ unary rest6
self.add_production("term ⟶ unary rest6")
# 更新推导
self.update_derivation("term", ["unary", "rest6"])
# 语义动作
unary_attr = self.parse_unary()
rest6_attr = Attribute()
rest6_attr.inPlace = unary_attr.place
rest6_attr = self.parse_rest6(rest6_attr)
# 为term创建属性
term_attr = Attribute()
term_attr.place = rest6_attr.place
return term_attr
def parse_rest6(self, inherited_attr):
"""解析rest6"""
rest6_attr = Attribute()
if self.current_token and self.current_token.type == 'MUL':
# rest6 ⟶ * unary rest61
self.add_production("rest6 ⟶ * unary rest6")
# 更新推导
self.update_derivation("rest6", ["*", "unary", "rest6"])
# 语义动作
self.match('MUL')
unary_attr = self.parse_unary()
# 生成乘法四元式
rest61_attr = Attribute()
rest61_attr.inPlace = self.semantic.newtemp()
self.semantic.emit("*", inherited_attr.inPlace, unary_attr.place, rest61_attr.inPlace)
rest61_attr = self.parse_rest6(rest61_attr)
# 为rest6创建属性
rest6_attr.place = rest61_attr.place
elif self.current_token and self.current_token.type == 'DIV':
# rest6 ⟶ / unary rest61
self.add_production("rest6 ⟶ / unary rest6")
# 更新推导
self.update_derivation("rest6", ["/", "unary", "rest6"])
# 语义动作
self.match('DIV')
unary_attr = self.parse_unary()
# 生成除法四元式
rest61_attr = Attribute()
rest61_attr.inPlace = self.semantic.newtemp()
self.semantic.emit("/", inherited_attr.inPlace, unary_attr.place, rest61_attr.inPlace)
rest61_attr = self.parse_rest6(rest61_attr)
# 为rest6创建属性
rest6_attr.place = rest61_attr.place
else:
# rest6 ⟶ ε
self.add_production("rest6 ⟶ ε")
# 更新推导
self.update_derivation("rest6", [])
# 语义动作
rest6_attr.place = inherited_attr.inPlace
return rest6_attr
def parse_unary(self):
"""解析unary"""
# unary ⟶ factor
self.add_production("unary ⟶ factor")
# 更新推导
self.update_derivation("unary", ["factor"])
# 语义动作
factor_attr = self.parse_factor()
# 为unary创建属性
unary_attr = Attribute()
unary_attr.place = factor_attr.place
return unary_attr
def parse_factor(self):
"""解析factor"""
factor_attr = Attribute()
if not self.current_token:
raise SyntaxError("语法错误: 意外的文件结束,期望一个因子")
if self.current_token.type == 'NUM':
# factor ⟶ num
self.add_production("factor ⟶ num")
# 更新推导
self.update_derivation("factor", ["num"])
# 语义动作
num_token = self.match('NUM')
factor_attr.place = num_token.value
elif self.current_token.type == 'LPAREN':
# factor ⟶ ( expr )
self.add_production("factor ⟶ ( expr )")
# 更新推导
self.update_derivation("factor", ["(", "expr", ")"])
# 语义动作
self.match('LPAREN')
expr_attr = self.parse_expr()
self.match('RPAREN')
factor_attr.place = expr_attr.place
elif self.current_token.type == 'ID':
# factor ⟶ loc
self.add_production("factor ⟶ loc")
# 更新推导
self.update_derivation("factor", ["loc"])
# 语义动作
loc_attr = self.parse_loc()
if loc_attr.offset is None:
factor_attr.place = loc_attr.place
else:
factor_attr.place = self.semantic.newtemp()
# 生成数组元素访问四元式
self.semantic.emit("=[]", f"{loc_attr.place}[{loc_attr.offset}]", "-", factor_attr.place)
else:
raise SyntaxError(f"语法错误: 无效的因子: {self.current_token.type}")
return factor_attr
def update_derivation(self, non_terminal, replacement):
"""更新当前推导句型,用replacement替换第一个出现的non_terminal"""
# 找到第一个出现的非终结符并替换
for i, symbol in enumerate(self.current_sentential):
if symbol == non_terminal:
# 替换non_terminal为replacement
new_sentential = self.current_sentential[:i] + replacement + self.current_sentential[i + 1:]
self.current_sentential = new_sentential
# 添加到推导步骤
if replacement: # 如果不是空生成式
self.add_derivation(self.current_sentential)
return True
return False
def print_result(self):
"""打印分析结果"""
print("\n1) 按使用产生式过程")
for i, step in enumerate(self.production_steps, 1):
print(f"({i}){step}")
print("\n2) 按推导过程")
for i, step in enumerate(self.derivation_steps, 1):
print(f"({i}) {step}")
def save_result(self, file_name):
"""保存分析结果到文件"""
try:
with open(file_name, 'w', encoding='utf-8') as f:
f.write("1) 按使用产生式过程\n")
for i, step in enumerate(self.production_steps, 1):
f.write(f"({i}){step}\n")
f.write("\n2) 按推导过程\n")
for i, step in enumerate(self.derivation_steps, 1):
f.write(f"({i}) {step}\n")
return True
except Exception as e:
print(f"保存文件时出错: {e}")
return False
def translate_example(self, code):
"""翻译示例代码 a=6/b+5*c-d;"""
print("\n翻译示例代码: " + code)
# 清空语义分析器
self.semantic = SemanticAnalyzer()
# 手动生成四元式
t1 = self.semantic.newtemp()
self.semantic.emit("/", "6", "b", t1)
t2 = self.semantic.newtemp()
self.semantic.emit("*", "5", "c", t2)
t3 = self.semantic.newtemp()
self.semantic.emit("+", t1, t2, t3)
t4 = self.semantic.newtemp()
self.semantic.emit("-", t3, "d", t4)
self.semantic.emit("=", t4, "-", "a")
# 输出四元式
print("\n生成的四元式:")
self.semantic.print_quadruples("语义分析.txt")
# 确保test4.txt文件存在
if not os.path.exists("test4.txt"):
# 创建测试文件
with open("test4.txt", "w", encoding="utf-8") as f:
f.write("a=6/b+5*c-d;")
print("已创建测试文件test4.txt")
# 读取测试文件
try:
with open("test4.txt", "r", encoding="utf-8") as file, open('词法分析.txt', 'w') as out_f:
print('词法分析:')
content = file.read()
file.seek(0) # 重置文件指针到开始位置
ch = file.read(1)
while ch:
if ch.isspace():
ch = file.read(1)
continue
res = ""
if ch.isalpha() or ch == '_':
ch, res = Recognizestr(ch)
elif ch.isdigit():
ch, res = RecognizeDigit(ch)
elif ch in {'+', '-', '*', '/', '%', '=', '>', '<', '!'}:
ch, res = Recognizeop(ch)
else:
ch, res = Recognizeoth(ch)
# 统一输出
print(res)
out_f.write(res + '\n')
print('语法分析:')
# 重置读取文件到开始的位置
file.seek(0)
code = file.read()
if not code.strip():
print("警告: test4.txt文件为空或只包含空白字符")
except Exception as e:
print(f"读取文件时出错: {e}")
code = "a=6/b+5*c-d;" # 默认测试用例
# 创建分析器并解析代码
analyzer = CompleteSyntaxSemanticAnalyzer()
success = analyzer.parse(code)
if success:
# 输出分析结果
analyzer.print_result()
if analyzer.save_result("语法分析.txt"):
print('\n语法分析完成,结果已保存到"语法分析.txt"文件中。')
else:
print("\n语法分析完成,但保存文件时出错。")
else:
print("\n语法分析失败。")
print('语义分析:')
print("\n生成的四元式:")
analyzer.semantic.print_quadruples("语义分析.txt")
运行该代码前,先导入"test4.txt"文件,输入到该文件中的内容如下:
a=6/b+5*c-d;![]()
程序运行结果如下:
词法分析:
<111, a>
<46, ->
<100, 6>
<44, ->
<111, b>
<41, ->
<100, 5>
<43, ->
<111, c>
<42, ->
<111, d>
<84, ->
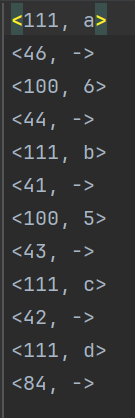
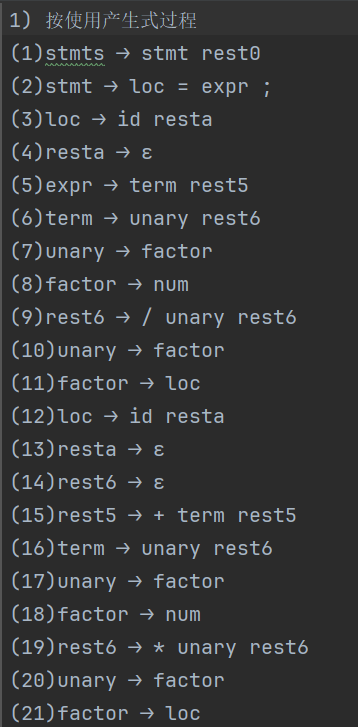
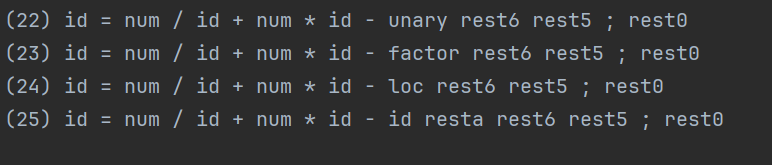
语法分析:
1) 按使用产生式过程
(1)stmts ⟶ stmt rest0
(2)stmt ⟶ loc = expr ;
(3)loc ⟶ id resta
(4)resta ⟶ ε
(5)expr ⟶ term rest5
(6)term ⟶ unary rest6
(7)unary ⟶ factor
(8)factor ⟶ num
(9)rest6 ⟶ / unary rest6
(10)unary ⟶ factor
(11)factor ⟶ loc
(12)loc ⟶ id resta
(13)resta ⟶ ε
(14)rest6 ⟶ ε
(15)rest5 ⟶ + term rest5
(16)term ⟶ unary rest6
(17)unary ⟶ factor
(18)factor ⟶ num
(19)rest6 ⟶ * unary rest6
(20)unary ⟶ factor
(21)factor ⟶ loc
(22)loc ⟶ id resta
(23)resta ⟶ ε
(24)rest6 ⟶ ε
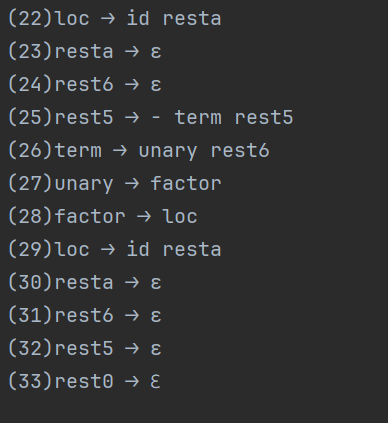
(25)rest5 ⟶ - term rest5
(26)term ⟶ unary rest6
(27)unary ⟶ factor
(28)factor ⟶ loc
(29)loc ⟶ id resta
(30)resta ⟶ ε
(31)rest6 ⟶ ε
(32)rest5 ⟶ ε
(33)rest0 ⟶ ℇ
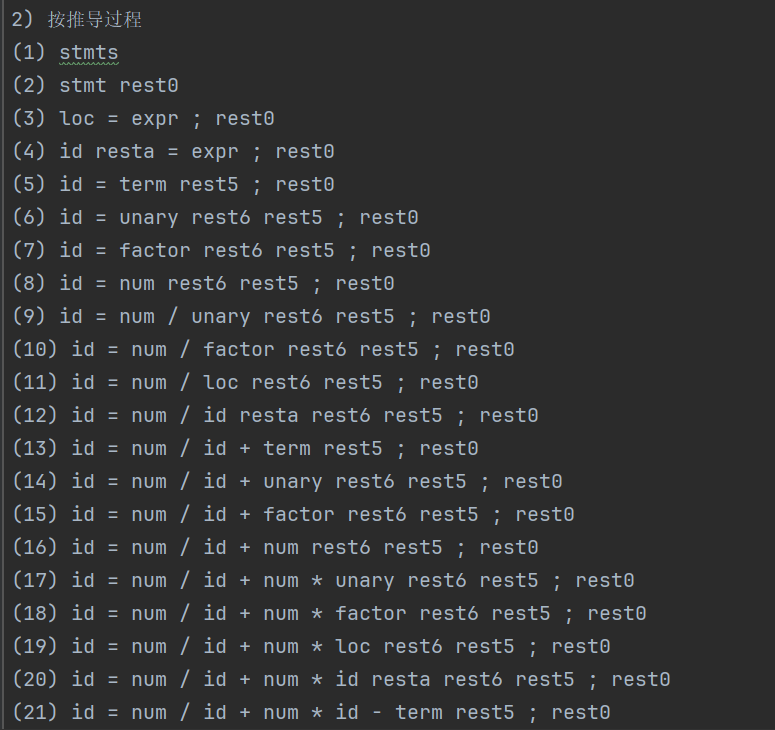
2) 按推导过程
(1) stmts
(2) stmt rest0
(3) loc = expr ; rest0
(4) id resta = expr ; rest0
(5) id = term rest5 ; rest0
(6) id = unary rest6 rest5 ; rest0
(7) id = factor rest6 rest5 ; rest0
(8) id = num rest6 rest5 ; rest0
(9) id = num / unary rest6 rest5 ; rest0
(10) id = num / factor rest6 rest5 ; rest0
(11) id = num / loc rest6 rest5 ; rest0
(12) id = num / id resta rest6 rest5 ; rest0
(13) id = num / id + term rest5 ; rest0
(14) id = num / id + unary rest6 rest5 ; rest0
(15) id = num / id + factor rest6 rest5 ; rest0
(16) id = num / id + num rest6 rest5 ; rest0
(17) id = num / id + num * unary rest6 rest5 ; rest0
(18) id = num / id + num * factor rest6 rest5 ; rest0
(19) id = num / id + num * loc rest6 rest5 ; rest0
(20) id = num / id + num * id resta rest6 rest5 ; rest0
(21) id = num / id + num * id - term rest5 ; rest0
(22) id = num / id + num * id - unary rest6 rest5 ; rest0
(23) id = num / id + num * id - factor rest6 rest5 ; rest0
(24) id = num / id + num * id - loc rest6 rest5 ; rest0
(25) id = num / id + num * id - id resta rest6 rest5 ; rest0
语法分析完成,结果已保存到"语法分析.txt"文件中。
语义分析:
生成的四元式:
0: /, 6, b, t1
1: *, 5, c, t2
2: +, t1, t2, t3
3: -, t3, d, t4
4: =, t4, -, a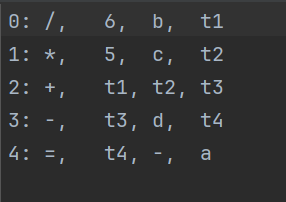
三、总结
本文实现了一个递归下降翻译器,用于处理赋值语句的语义分析和中间代码生成。系统包含词法分析、语法分析和语义分析模块,最终生成四元式中间代码。针对测试表达式"a=6/b+5*c-d",程序成功完成了以下工作:
1.词法分析:正确识别标识符、数字和运算符。
2.语法分析:详细记录了产生式使用和推导过程。
3.语义分析:生成5个四元式,包括除法、乘法、加法、减法运算和最终赋值。
4.输出处理:将结果保存到"词法分析.txt"、"语法分析.txt"和"语义分析.txt"三个文件中。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)