纵向联邦学习中的逻辑回归方案介绍
纵向联邦学习中的逻辑回归方案1,传统机器学习里的LR计算:y′=σ(wx)y^\prime=σ(wx)y′=σ(wx)。w为模型;目标:输入x得到输出。如何训练w:w:=w−g,其中g=(y′−y)xw:=w-g,其中g=(y^\prime-y)xw:=w−g,其中g=(y′−y)x如何停止:设置迭代次数和loss收敛阈值。2,纵向联邦里的LR联邦学习里首先对标签{0,1}改动为{1,-1}。然后
纵向联邦学习中的逻辑回归方案
1,传统机器学习里的LR
计算:y′=σ(wx)y^\prime=σ(wx)y′=σ(wx)。w为模型;目标:输入x得到输出。
- 如何训练w:w:=w−g,其中g=(y′−y)xw:=w-g,其中g=(y^\prime-y)xw:=w−g,其中g=(y′−y)x
- 如何停止:设置迭代次数和loss收敛阈值。

2,纵向联邦里的LR
联邦学习里首先对标签{0,1}改动为{1,-1}。然后为了支持同态,对损失函数做了改动。
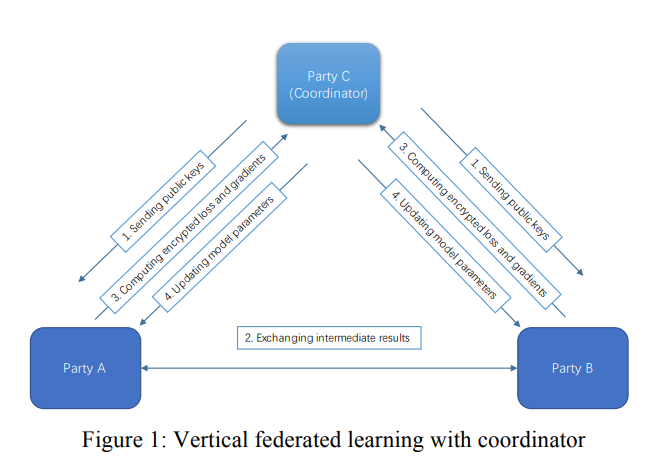
2.1,有第三方:
全局只有一对公私钥。第三方持有私钥,参与方持有公钥。
协作者的角色:负责解密梯度和损失,没啥了。
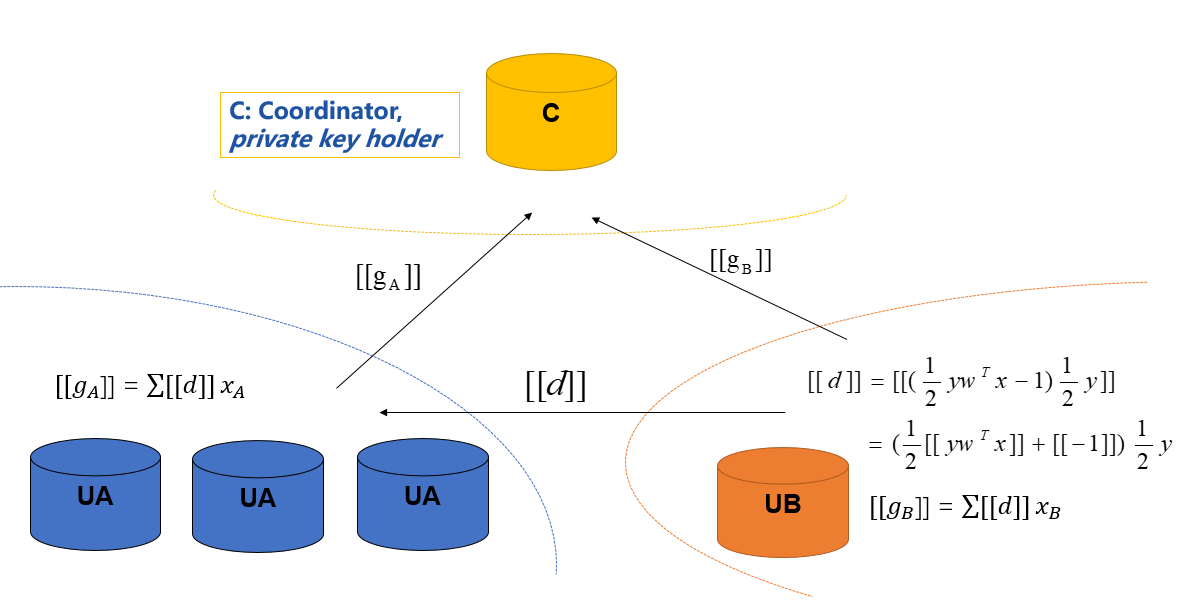
实现细节: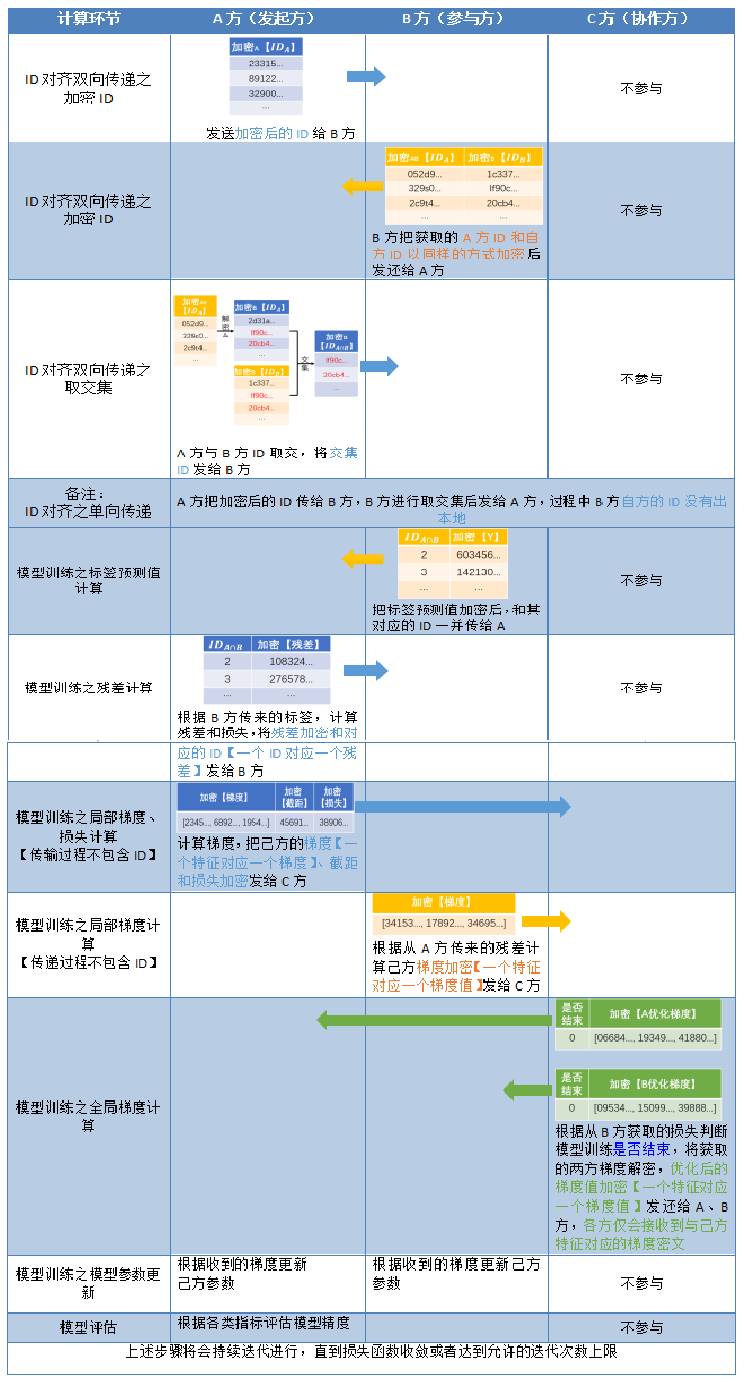
2.2,无第三方
构建一对公私钥
(该方案认为wx默认是安全的,所以没有加密)

出处:Parallel Distributed Logistic Regression for Vertical Federated Learning without Third-Party Coordinator
构建两对公私钥
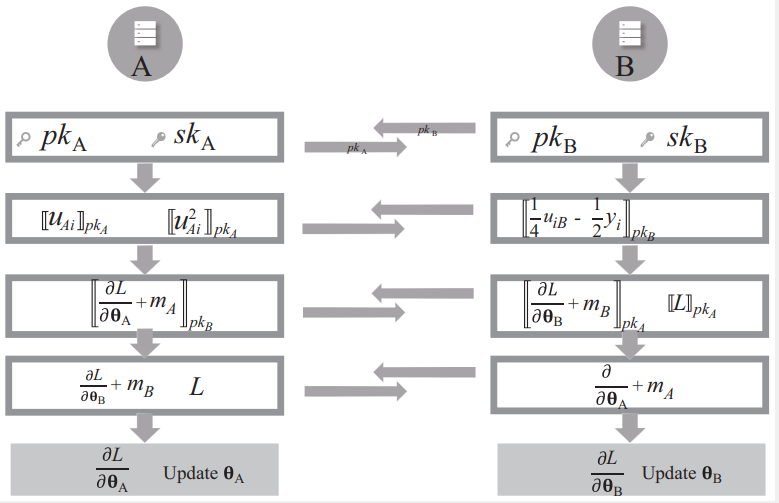
具体细节:
标签持有方A和参与方B各自生成公私钥。
符号定义:u=wx,其中w表示模型参数;x表示特征数据;y表示标签数据;【*】表示同态加密后的数据。
计算公式定义:
双方的损失函数:Loss=log2−12ywx+18(wx2)Loss=log2-\frac{1}{2}ywx+\frac{1}{8}({wx}^2)Loss=log2−21ywx+81(wx2)
模型迭代公式:w:=w−α1m14(wx−2y)xw:=w-\alpha\frac{1}{m}\frac{1}{4}(wx-2y)xw:=w−αm141(wx−2y)x,其中梯度∇L=14(wx−2y)x=dx=g\nabla L=\frac{1}{4}(wx-2y)x=dx=g∇L=41(wx−2y)x=dx=g
训练一轮的具体执行过程:
(和上一方案初始时随机化参与方wx相比,该方案初始直接没用数据方的wx)
其实ub=wbxb可以直接明文发送过去,我们认为它是安全的。
- A和B交换公钥;
- A计算并发送[uA]pkA,[uA2]pkA[u_A]pk_A,[u_A^2]pk_A[uA]pkA,[uA2]pkA;B计算并发送[14uB−12y]pkB[\frac{1}{4}u_B-\frac{1}{2}y]pk_B[41uB−21y]pkB;
- A计算并发送[∇LA+mA]pkB[\nabla L_A+m_A]pk_B[∇LA+mA]pkB;B计算并发送[∇LB+mB]pkA[\nabla L_B+m_B]pk_A[∇LB+mB]pkA,以及损失[L]pkA[L]pk_A[L]pkA;
- AB各自解密对方的梯度;然后减去各自的掩码,即可获得更新后的梯度、模型。
(注意,此时梯度已经解密,各方能够拿到自己的明文梯度。此时需要对明文梯度进行安全性分析。)
重复此过程,直到达到最大迭代次数或者模型收敛。
预测的具体执行过程:
1,模型掌握在A,B双方,比如这里假设模型询问者为A:
A将数据分为XA,XA′X^A,X^{A\prime}XA,XA′,A计算waxAw_ax^AwaxA;B计算wb[xA′]w_b[x^{A\prime}]wb[xA′]并返回;
A解密,并计算u=ua+ubu=u_a+u_bu=ua+ub;输出结果11+e−u\frac{1}{1+e^-u}1+e−u1。
2,模型掌握在A,B双方,询问者为第三方C:
- C将数据分为两份,并加密发送给A,B双方;
- A,B双方分别计算wa[xa]c、wb[xb]cw_a[x^a]_c、w_b[x^b]_cwa[xa]c、wb[xb]c并返回给C;
- C解密得到u=ua+ubu=u_a+u_bu=ua+ub;输出结果11+e−u\frac{1}{1+e^-u}1+e−u1。
3,推导细节
更多推导细节,参见手稿:


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)