使用RAG技术构建企业级文档问答系统:检索优化Step-Back Prompting
跟CoT要解决的问题类似,本质上都是In-Context Learning,区别在于CoT是让LLM将求解步骤分开,不要一次输出所有结果,但对于一些复杂的数理问题,如果不知道要用什么理论、公式去解决,即使一步步求解也依然无法获得正确的答案,这就是Take a Step Back这篇论文提出的动机,它通过Prompt让LLM“退后一步”,不要直接尝试解决问题,而是思考解决这个问题更高层次、更抽象的问
1 概述
Step-Back Prompting是Google DeepMind团队在论文Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models中提出的一种Prompt技术。
跟CoT要解决的问题类似,本质上都是In-Context Learning,区别在于CoT是让LLM将求解步骤分开,不要一次输出所有结果,但对于一些复杂的数理问题,如果不知道要用什么理论、公式去解决,即使一步步求解也依然无法获得正确的答案,这就是Take a Step Back这篇论文提出的动机,它通过Prompt让LLM“退后一步”,不要直接尝试解决问题,而是思考解决这个问题更高层次、更抽象的问题是什么。
例如论文中所举的例子:“理想气体的压强P,如果温度增加2倍,体积增加8倍会发生什么变化?”,即使使用CoT,LLM也依然无法回答正确,但使用Step-Back Prompting,让LLM先回忆出来理想气体公式,然后让LLM应用这个公式,问题得到顺利解决。又比如“埃斯特拉·利奥波德在1954年8月至1954年11月期间就读于哪所学校?”,这种问题在RAG中直接检索的话,很可能无法检索到正确的知识片段,但如果换成一个更抽象的问题:“埃斯特拉·利奥波德的教育历史是什么”则很有可能检索到正确片段从而正确回答问题。
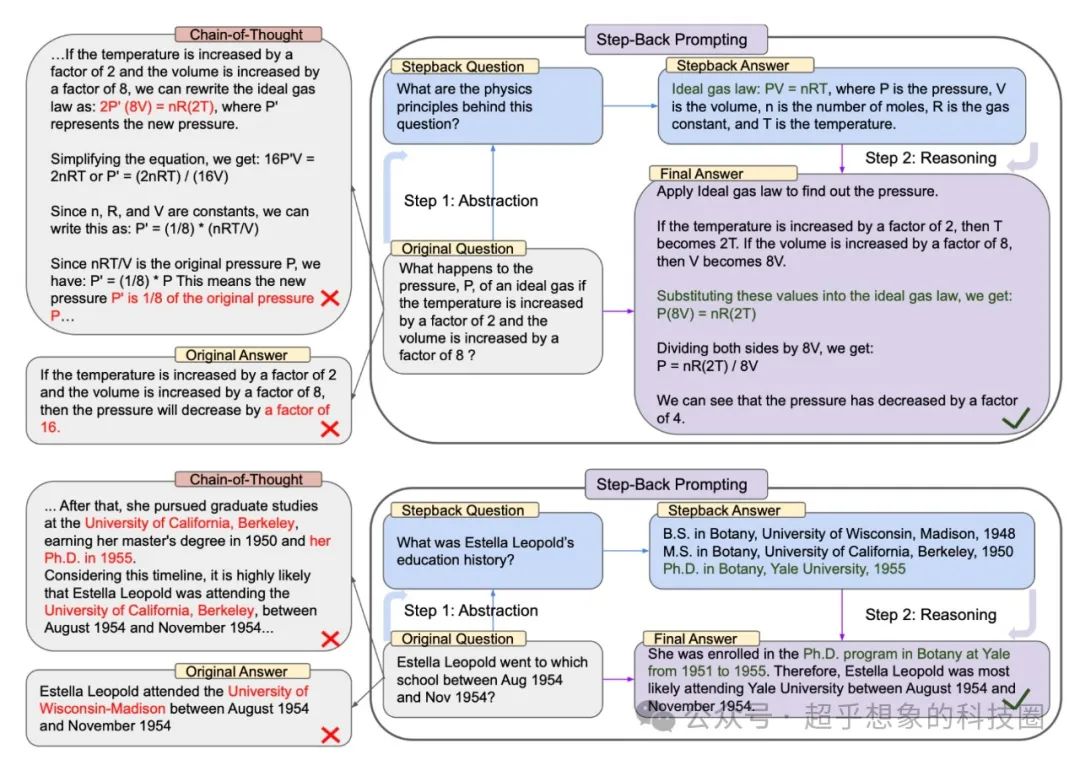
作者在SituatedQA这样的文档问答QA数据集上也进行了测试,效果领先于未使用Step-Back Prompting的同类模型。
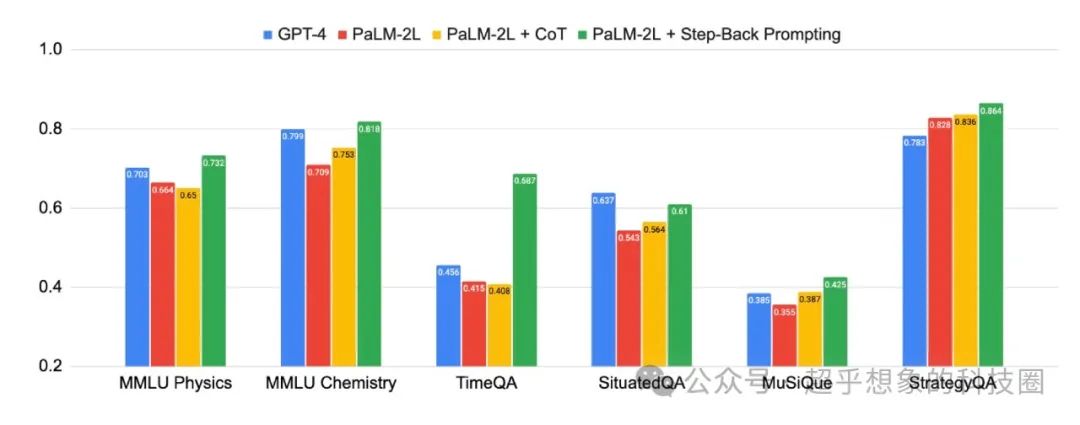
2 效果对比
虽然从理论上讲,Step-Back Prompting有其合理性,但在不同场景中效果可能未必有论文中那么好,下面是在本系列文章所构建的测试集中测试的结果,基本上是各种方法中最差的,当然这也并不能说明这个方法无效,只能说明在当前场景下它不是一个有效的优化方法。
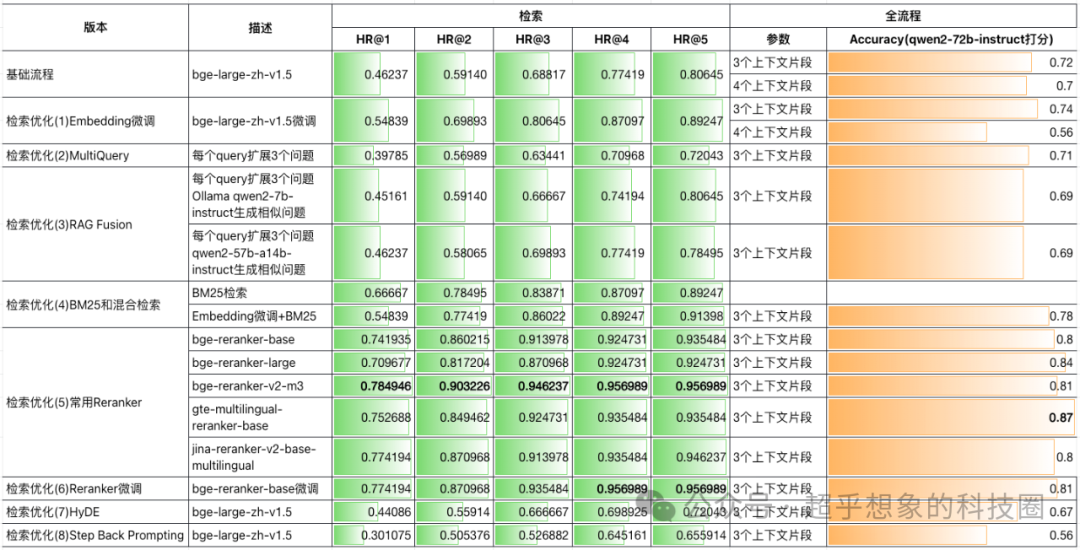
3 核心代码
完整代码已开源,地址在:https://github.com/Steven-Luo/MasteringRAG/blob/main/retrieval/08_step_back_prompting.ipynb
下面核心讲解借助Step Back Prompting进行检索的chain,大致可以分为三个部分:Prompt构建、生成更抽象的问题、检索。
用于生成更抽象问题的Prompt构建:
from langchain.prompts import FewShotChatMessagePromptTemplate, ChatPromptTemplate
examples = \[
{
"input": "美联储预计下半年利率会下调多少?",
"output": "美联储下半年的利率政策会如何制定",
},
{
"input": "如何评估一家公司股票的内在价值?",
"output": "什么方法可以用来评估资产的真实价值?",
}
\]
\# 转换为消息
example\_prompt = ChatPromptTemplate.from\_messages(
\[
('human', '{input}'),
('ai', '{output}')
\]
)
few\_shot\_prompt = FewShotChatMessagePromptTemplate(
example\_prompt=example\_prompt,
examples=examples
)
prompt = ChatPromptTemplate.from\_messages(\[
(
'system',
"""你是金融领域的专家。你的任务是把一个问题改写成一个更一般或更抽象的问题,但注意仅问题改写得更一般即可,如果问题有主体,问题的主体要保持不变。如果你不确定如何改写,请保持原问题不变。直接输出改写后的问题即可,不需要包含“改写之后的问题”之类的描述性内容。这里有几个例子:"""
),
few\_shot\_prompt,
('user', '{question}')
\])
生成更抽象问题的Chain:
step\_back\_query\_gen = (
prompt
| llm
| (lambda ai\_msg: ai\_msg.content)
| (lambda x: x.replace('AI:', '').replace('ai:', '').strip() if x.lower().startswith('ai:') else x)
)
试用一下:
step\_back\_query\_gen.invoke({'question': '美国单一家庭房贷整体拖欠率在2023年二季度达到多少?'})
结果:
什么是影响个人贷款违约率的主要因素?
完整的检索chain:
from langchain.embeddings import HuggingFaceBgeEmbeddings
from langchain\_community.vectorstores import Chroma
model\_path = 'BAAI/bge-large-zh-v1.5'
embeddings = HuggingFaceBgeEmbeddings(
model\_name=model\_path,
model\_kwargs={'device': device},
encode\_kwargs={'normalize\_embeddings': True},
query\_instruction='为这个句子生成表示以用于检索相关文章:'
)
vector\_db = Chroma.from\_documents(
splitted\_docs,
embedding=embeddings,
persist\_directory=persist\_directory
)
retrieve\_chain = (
step\_back\_query\_gen
| (lambda x: vector\_db.similarity\_search(x, k=top\_k))
)
\# 使用
retrieve\_chain.invoke('美国单一家庭房贷整体拖欠率在2023年二季度达到多少?')
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 25
25 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)