联邦学习+语义通信文献阅读记录(一)
隐私问题:由于隐私原因,分布式学习必须在不交换原始数据的情况下进行。(联邦迁移学习)无线环境的不确定性:无线系统的随机性(如干扰和衰落)会影响学习性能。架构优化:信息网络的传输架构影响收敛速度。计算资源:分布式学习需要高效的计算方法,但带宽同时有限。网络优化:分布式学习涉及多个代理协同解决复杂的优化问题(空中计算,边缘计算)。
文献1: Distributed Learning in Wireless Networks: Recent Progress and Future Challenges
核心内容
1.介绍了几种新兴的分布式学习范式,涉及到的技术包括联邦学习、联邦蒸馏、分布式推理和多智能体强化学习
2.分析了多个面向无线网络的分布式学习框架,分析动机,分析优化指标
3.介绍未来的研究方向,改进机会
优化方向总结
隐私问题:由于隐私原因,分布式学习必须在不交换原始数据的情况下进行。(联邦迁移学习)
无线环境的不确定性:无线系统的随机性(如干扰和衰落)会影响学习性能。
架构优化:信息网络的传输架构影响收敛速度。
计算资源:分布式学习需要高效的计算方法,但带宽同时有限。
网络优化:分布式学习涉及多个代理协同解决复杂的优化问题(空中计算,边缘计算)。
核心框架FL(FedAvg)
文献2:Towards federated learning at scale: System design
联邦学习算法介绍-FedAvg详细案例-Python代码获取-CSDN博客(包含了差分FedSGD)
迭代核心:

FL 群体由一个唯一的名称指定,每个所研究的学习问题或应用指定一个FL。
FL群体中分多个FL 任务,使用给定的超参数进行训练,在本地设备数据上对训练后的模型进行评估。
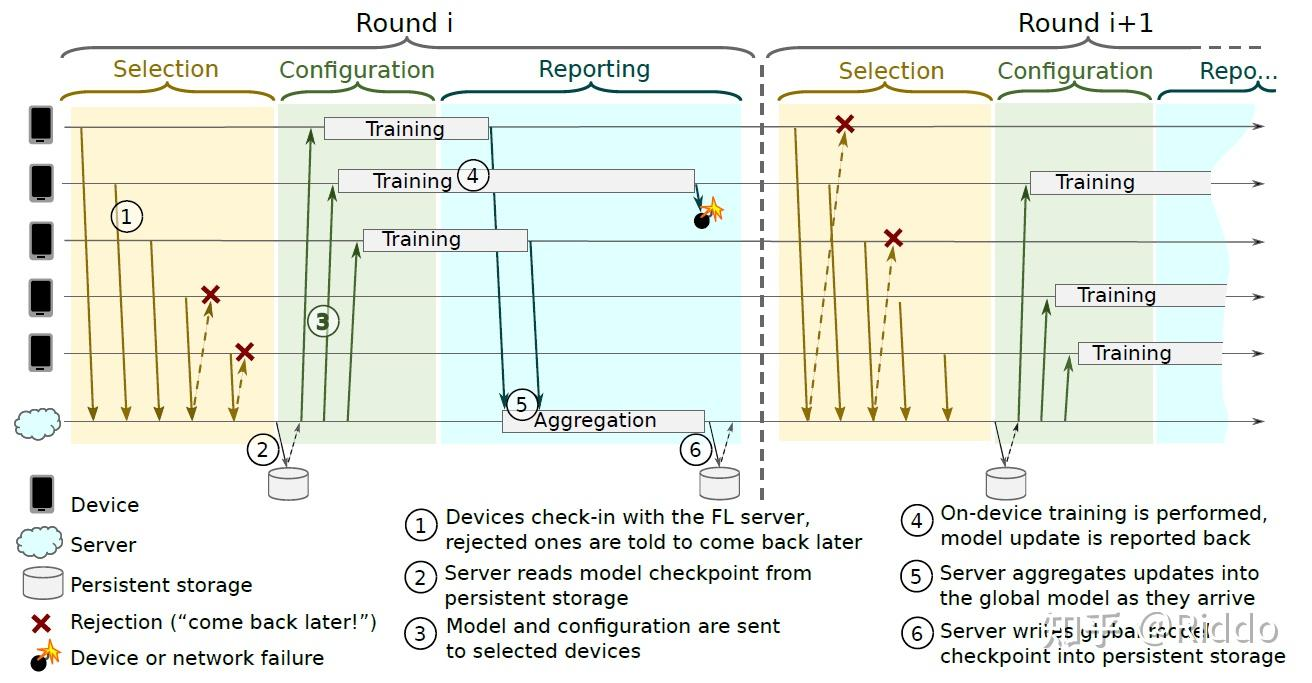
1.Selection
每过一定的间隔时间,满足要求(比如正在充电并连着 WiFi 的手机)的设备就会向服务器注册。服务器就会通过水塘抽样(reservoir sampling)”选择已连接设备的子集来参与这一轮的训练。服务器会向没有选中的设备发送下一次间隔后重连的指令。
2.Configuration
服务器向设备发送 FL plan 以及包括了 全局模型参数以及其它必要的状态量 的 FL checkpoint(essentially the serialized state of a TensorFlow session)。
3.Reporting
在该阶段,服务器等待参与本轮的设备返回更新结果。更新收集完毕,服务器使用 FedAvg 对更新结果进行聚合,并向返回结果的设备发送什么时候再次重连的指令。如果在一定时间内有足够多数量的设备返回更新结果,意味着该轮顺利完成,服务器会更新全局模型,否则该轮则会被丢弃
Pace Steering 是一种调节设备连接模式的流量控制机制。使服务器既能缩小规模以处理小的 FL populations,又能扩大规模以处理非常大的 FL populations。
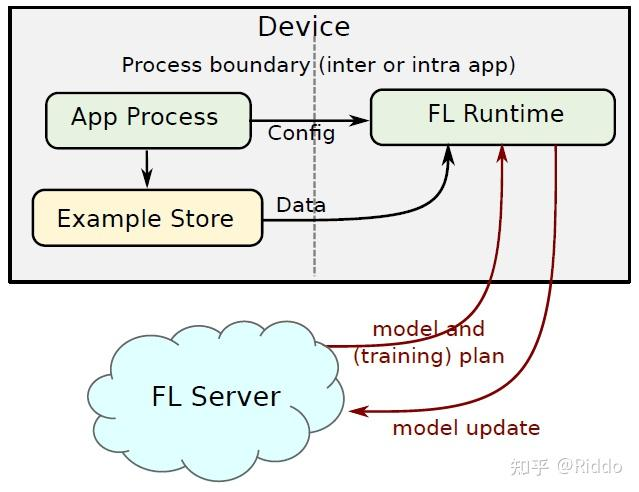
4.Client架构
5.Actor架构
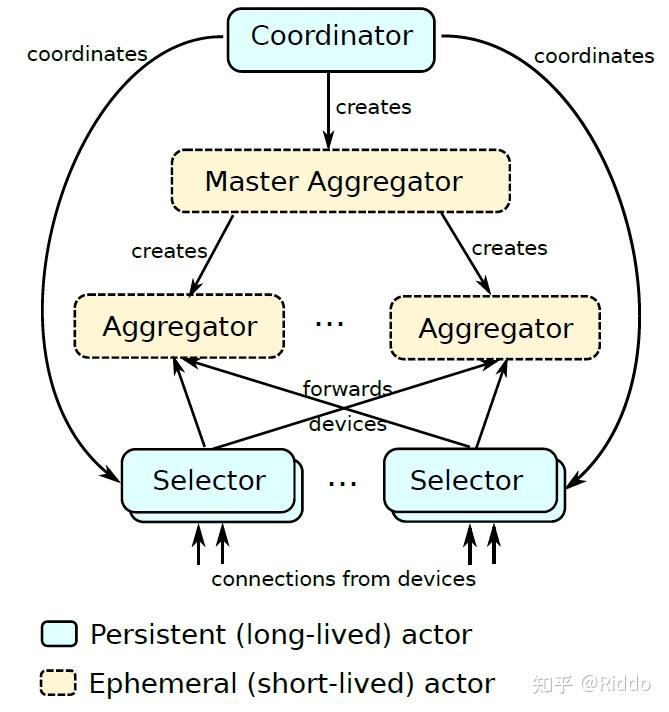
Coordinators :
负责全局同步和同步推进轮次,服务器中有多个 Coordinators,每个 Coordinator 负责一个 FL population 的设备群。Coordinator 将其地址和它所管理的 FL population 注册在一个共享的锁定服务(shared locking service)中,可被 Selectors。Coordinators等触达,接收关于有多少设备连接到每个 Selector 的信息,并指示它们根据预先安排的 FL task,应该接受多少设备参与。并生成 Master Aggregators 来管理每个 FL task的轮次。
Master Aggregators
管理每个 FL task 的轮次。为了随着设备数量和更新大小的扩大而扩大,它们做出动态决定,生成一个或多个 Aggregators,将工作委托给这些 Aggregators。
Selectors
负责接受和转发设备连接。从 Coordinators 那里收到关于每个 FL populations 需要多少设备的信息,它们用这些信息来做出是否接受每个设备的决定。在 Master Aggregators 和一组 Aggregators 产生后,Coordinators 指示 Selectors 将其连接的一部分设备转发到 Aggregators,使得无论有多少设备可用, Coordinators 都能有效地将设备分配给 FL task。
同时可以允许 Selectors 在全球范围内分布(靠近设备),与Coordinators 只有有限的通信。
Pipelining
虽然每一轮的 Selection、Configuration 和 Reporting 阶段是线性顺序的,但 Selection 阶段并不依赖于前一轮的任何输入。因为下一轮的 Selection 阶段与前一轮的 Configuration/Reporting 阶段可以并行运行。因为并行性仅仅是通过 Selectors 连续运行选择过程来实现的。
Failure Modes
在所有的故障情况下,系统都将继续运行,要么完成当前轮次,要么从先前记录的轮次的结果重新开始。在许多情况下,一个 actor 的损失不会阻止轮次的成功。
如果一个 Aggregators 或 Selectors 崩溃了,只有连接到该 actor 的设备会丢失。
如果 Master Aggregators 出现故障,它所管理的 FL task 的当前轮次将失败,但随后将由 Coordinator 重新启动。
如果 Coordinator 死亡,Selectors 将检测到这一点并重生它。
影响收敛的因素
FL 的收敛时间取决于三个因素:a) ML 参数传递延迟 TT;b) 每个设备训练其本地 ML 模型所需的时间 TT;c) 学习步数 NT。在此,我们需要注意 TC 和 NT 的相关性。特别是,在每个学习步骤中增加更新本地 ML 模型的 SGD 步骤数(例如增加 TC),可以减少 FL 收敛所需的学习步骤 NT。
无线信道中的影响指标(资源分配)
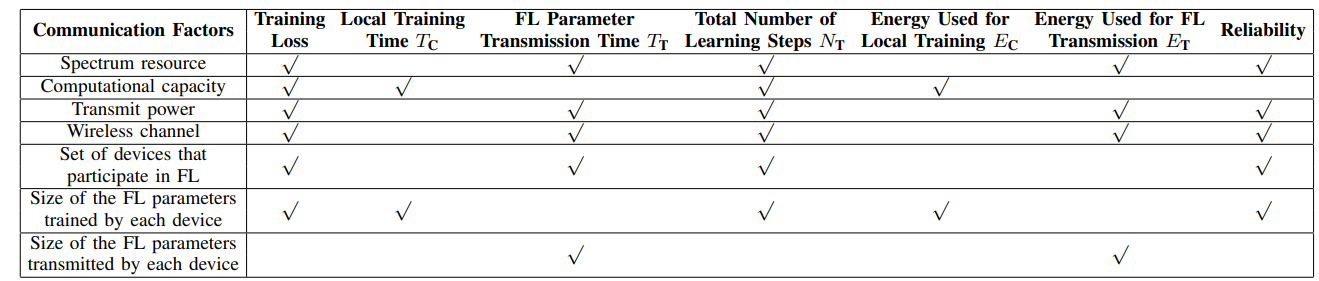
频谱、发射功率、计算能力等无线资源共同决定了FL训练损耗、收敛时间、能耗和可靠性。由于无线网络资源有限,需要优化资源配置,使无线网络能够高效地完成学习训练过程。
FL 训练过程是分布式和迭代的,但量化每个模型更新如何影响整个训练过程具有挑战性。此外,由于每个设备仅与 PS 交换其梯度向量,因此 PS 没有关于设备本地数据集的任何信息,并且不能使用样本分布或数据样本的值来决定资源分配将如何影响 FL 收敛。
[50]–[52]的作者研究了局部ML模型更新和全局ML模型聚合之间的权衡,以最小化局部ML模型训练和传输的总能耗或FL训练损失。
[53]–[56]的作者研究了使用梯度统计来优化在每个训练轮中参与FL的设备集。作者在[57]中假设只有当SINR低于目标阈值时,PS才能解码设备传输的本地FL模型,并分析了用户调度如何影响FL收敛。
优化训练方法(局部基站交换)
在[3]中,考虑了一种分层网络架构,结果表明,如果借助小型基站进行局部训练,则可以加速全球收敛,而小型基站只是偶尔与宏基站进行通信以获得全球共识。本地学习不仅加快了学习过程,还降低了短距离传输带来的通信能耗,并通过跨多个小基站的频率复用提高了通信效率,实现了并行的本地学习过程。
在S. P. Karimireddy, Q. Rebjock, S. Stich, and M. Jaggi, “Error feedback fixes SignSGD and other gradient compression schemes,” in Proc. International Conference on Machine Learning, Long Beach, CA, USA, Jun. 2019.中提出了一种基于错误反馈的SignSGD更新方法,以提高收敛性和泛化性。
在. S. H. Abad, E. Ozfatura, D. Gündüz, and O. Ercetin, “Hierarchical federated learning across heterogeneous cellular networks,” in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, May 2020.中,提出了分层学习,将设备分组为集群,每个集群内的设备借助小基站或集群头进行局部学习,同时在宏基站训练全局模型。该框架在S. Hosseinalipour, S. S. Azam, C. G. Brinton, N. Michelusi, V. Aggarwal, D. J. Love, and H. Dai, “Multi-stage hybrid federated learning over large-scale D2D-enabled fog networks,” arXiv preprint arXiv:2007.09511, 2020.中得到了扩展,该框架为多层学习网络设计了一种训练方法。
[59]和[60]中提出了一种梯度聚合方法,减少必须将本地ML参数传输到PS的设备数量,减少FL通信开销。
[61]为FL引入了一个非参数广义贝叶斯推理框架,以减少FL需要收敛的学习步骤数量。
[62]提出了一种后本地SGD更新方法,该方法使每个设备能够在最初的多个学习步骤中更新一次其ML参数
优化模型参数
[63]中的工作设计了一种并行重启的SGD方法,使用该方法,每个设备将在每个特定的学习步骤中平均其ML模型,并执行本地SGD以在其他学习步骤中更新其ML模型。
[20]、[64] 和 [65] 中使用去中心化平均方法来更新每个设备的局部 ML 模型。特别是,使用分散式平均方法,每个设备只需要将其本地ML参数传输到其相邻设备。每个设备都可以使用其相邻设备的 ML 参数来估计全局 ML 模型。
分散平均方法可以减少FL参数传输的通信开销。每个设备只需要连接到其相邻设备,能量和无线资源有限而无法连接到PS的设备可以与相邻设备关联,从而参与FL训练。可以包括更多的无线设备参与到FL训练中。同时器件可以形成不同的网络拓扑结构,进一步改善无线传输不完善导致的FL参数传输时间和ML模型不准确性。最后,由于每个设备仅与其相邻设备共享其 ML 参数,并且 PS 无法知道所有设备的 ML 参数,因此可以改善针对 PS 的隐私(假设相邻设备值得信赖)。
边缘中的知识蒸馏(KD)及编码优化
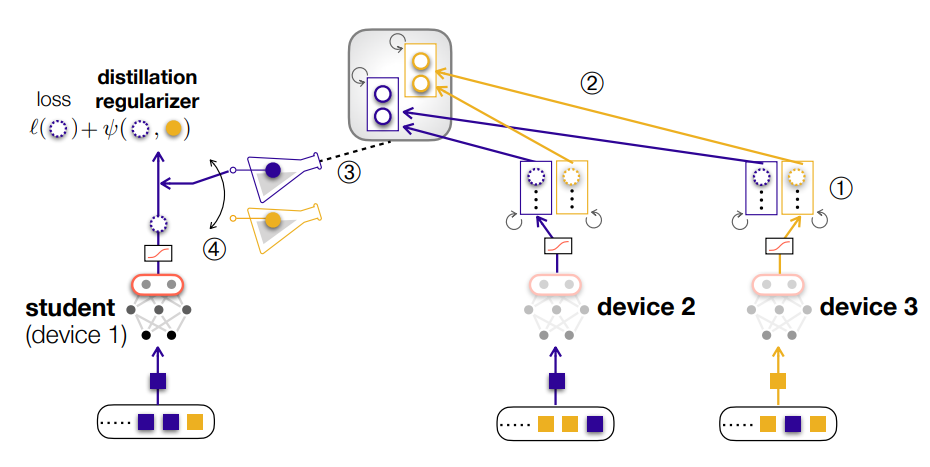
深度神经网络模型参数的数量成本高昂,阻碍了频繁的通信,尤其是在有限的无线资源下。或者,联合蒸馏 (FD) 仅交换维度远小于模型大小的模型输出(例如,MNIST 数据集中的 10 个类)。例如,在分类任务中,每个设备运行本地迭代,同时存储每个类的平均模型输出(即 logit)。然后,定期将这些本地平均输出上传到 PS,聚合和平均每个类设备的本地平均输出。随后,每个设备都会下载生成的全局平均输出。最后,为了将下载的全局知识传输到本地模型中,每个设备都运行具有自己的损失函数的局部迭代,此外还有一个正则化器来测量其自身的训练样本的预测输出与给定样本类别的全局平均输出之间的差距。这种正则化方法称为知识蒸馏(KD)。
一种基于数据的完全驱动的DNN方案,称为DeepJSCC。
Bourtsoulatze, D. Kurka, and D. Gündüz, “Deep joint sourcechannel coding for wireless image transmission,” IEEE Transactions on Cognitive Communications and Networking, vol. 5, no. 3, Sep. 2019.
D. B. Kurka and D. Gündüz, “DeepJSCC-f: Deep joint source-channel coding of images with feedback,” IEEE Journal on Selected Areas in Information Theory, vol. 1, no. 1, pp. 178–193, May 2020.
D. B. Kurka and D. Gündüz, “Bandwidth-agile image transmission with deep joint source-channel coding,” arXiv preprint arXiv:2009.12480, 2020.
改进版的FL框架
1.FMTL
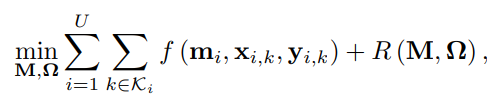
function R (·) is a regularizer. To solve problem (2), one can use separate problem (2) into several subproblems so as to enable devices to solve problem (2) in a distributed manner.
设备在收敛时可能具有不同的 ML 模型。对于非 IID 数据或不同的学习任务,具有不同 ML 模型的设备可以实现训练损失总和的减小
2.MAML
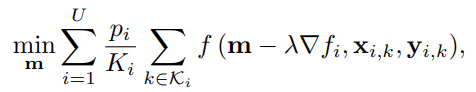
基于 MAML 的 FL 旨在为所有设备找到一个通用的 ML 模型。然后,设备可以使用自己的数据,通过几步梯度下降来更新它们的共同 ML 模型。从而找到个性化的 ML 模型。
备忘1:关注文献
Google所设计的FL:K. Bonawitz, H. Eichner, W. Grieskamp, D. Huba, A. Ingerman, V. Ivanov, C. M. Kiddon, J. Konecny, S. Mazzocchi, B. McMahan, T. V. Overveldt, D. Petrou, D. Ramage, and J. Roselander, “Towards federated learning at scale: System design,” in Proc. Systems and Machine Learning Conference, Stanford, CA, USA, Feb. 2019.
在[8]-[12]中,对 FL 在通信网络 中的应用进行了全面的调查。
[13]-[17]介绍了 如何利用通信技术提高在无线网络上实现的 FL 算法的性 能。
19]和[20]介绍了基于 FL 的新型分布式 学习算法,并讨论了实现其解决方案的几个开放研究方向
在[21]、[22]中, 对 FL 的安全和隐私挑战进行了 调查。
在[23]中,介绍了如何使用通信技术来提高收 敛速度并实现精确的训练和推理。
在 [24] 中,介绍 了 FL 和联合蒸馏技术,以实现高效的通信学习。在 [25] 中解释了强化学习在解决无线通信问题中的应用。
在[26] 中,介绍了联合边缘学习、分布式推理和分布式学习。
多代理框架:L. Busoniu, R. Babuska, and B. De Schutter, “A comprehensive survey of multiagent reinforcement learning,” IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), vol. 38, no. 2, pp. 156–172, Feb. 2008.
ByteLake和联想[69]展示了FL物联网行业应用,使5G网络中的物联网设备能够相互学习,并可以在物联网设备上利用本地ML模型。M. Rojek and R. Daigle, “AI FL for IoT,” Presentation at MWC 2019 https://www.slideshare.net/byteLAKE/ bytelake-and-lenovo-presenting-federated-learning-at-mwc-2019, 2019, Accessed: 2021-01-17.
爱立信[72]的作者在许多用例上对其进行了测试,将模型从传统的集中式机器学习迁移到联邦学习,使用原始模型的准确性作为基线。他们的研究表明,由于需要共享的数据量急剧下降,使用简单的神经网络会导致网络利用率显着降低。K. Vandikas, S. Ickin, G. Dixit, M. Buisman, and J. Åkeson, “Privacy-aware machine learning with low network footprint,” Ericsson Technology Review article https://www.ericsson.com/en/ericsson-technologyreview/archive/ 2019/privacy-aware-machine-learning, 2019, Accessed: 2021-01-17
例如在边缘设备上训练 FL 模型的计算资源分配、FL 用户的选择、 联邦学习实现的能效、联邦学习参数传输的频谱资源分配、通信高效学习方案的设计。尽管如此,电信行业最近开始在工业上应用分布式机器学习,以在使用机器学习进行网络优化、时间序列预测[70]、预测性维护和体验质量(QoE)建模[71]、[72]时提高隐私。
文献3:HFEL: Joint Edge Association and Resource Allocation for Cost-Efficient Hierarchical Federated Edge Learning
核心内容
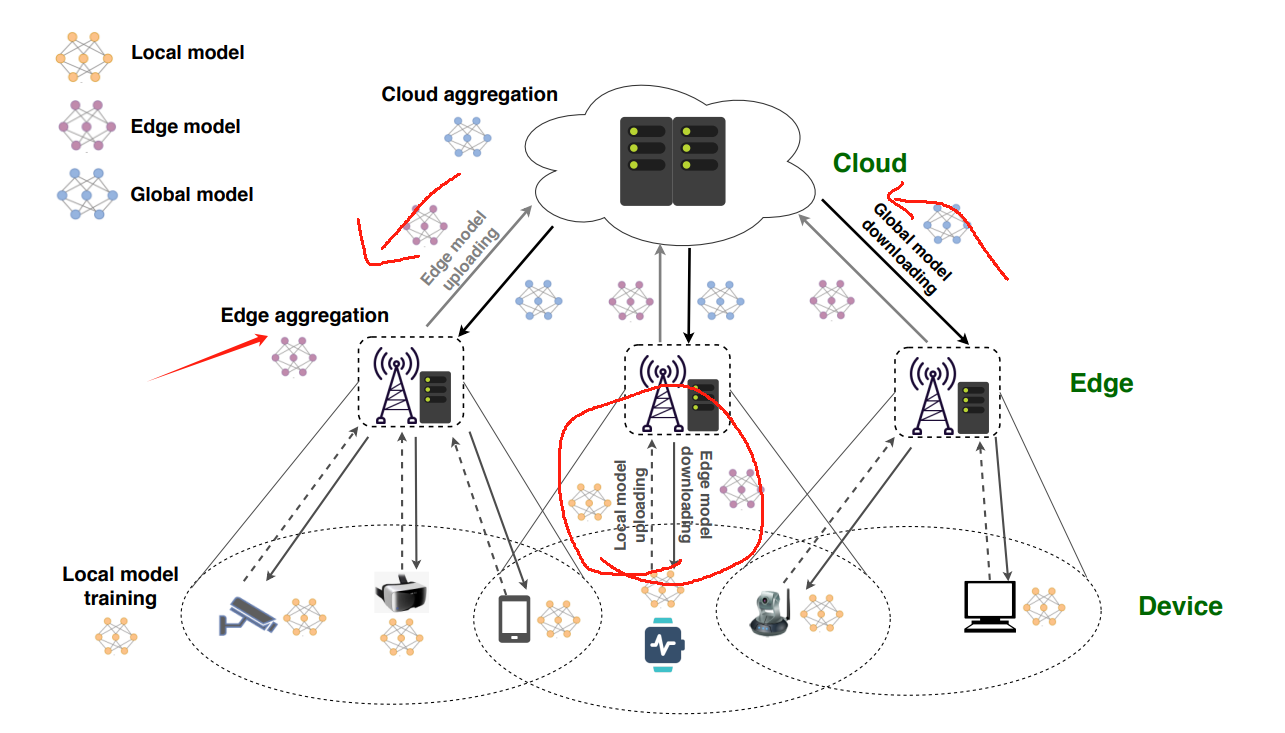
将原始优化问题分解为两个子问题:1)资源分配问题;2)边缘关联问题
被调度上传本地模型到同一个边缘服务器,求解一个最优策略,即每个设备贡献的计算能力和每个设备从边缘服务器分配到的带宽资源。
对于边缘关联,我们可以根据训练组内资源分配的最优策略,通过降低成本的迭代,为每个边缘服务器找出 一组可行的设备(即训练组)。边缘关联过程的迭代最终会收敛到一个稳定的系统点
边缘聚合
包括局部模型计算、局部模型传输和边缘模型聚合三个步骤。
本地模型首先由移动设备训练,然后传输到其关联的边缘服务器进行边缘聚合,通过求解机器学习模型参数 ω,使用损失函数 fn(xj , yj , ω) 表征输出值 yj。
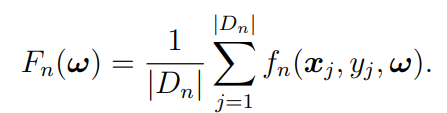
结束条件是到达迭代精度,并同步平均时延与功率系数
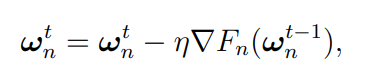
第2步。本地模型传输。完成 L(θ) 局部迭代后,每个设备 n 会将其本地模型参数传输到选定的边缘服务器
第 3 步。边缘模型聚合。在此步骤中,每个边缘服务器 i 从其连接的设备 Si 接收更新的模型参数,然后将它们平均为
Dsi是聚合集,迭代次数即聚合的次数只和精确度有关
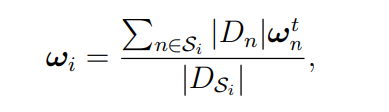
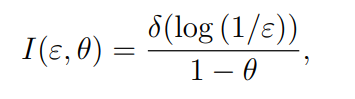
优化问题是保证时延和能量的最小化,精度由迭代保证吧?
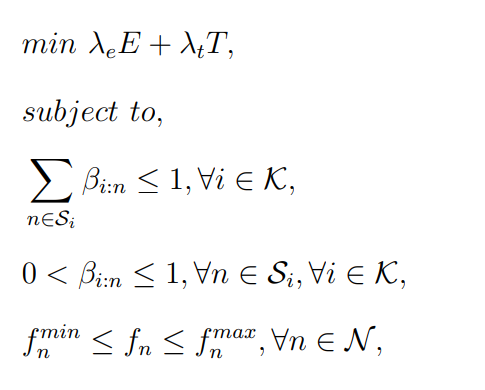
单边缘服务器的资源最小化

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 31
31 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)