R语言聚类分析
基本过程-读数据-数据标准化-计算距离-分类library('flexclust') # 导入数据集data(nutrient)# 加载数据row.names(nutrient) <- tolower(row.names(nutrient)) # 把行索引小写head(nutrient)#由于能量变化范围比其他变量更大,缩放数据有利于均衡各变量的影响。nutrient_scaled <
·
基本过程
- 读数据
- 数据标准化
- 计算距离
- 分类
library('flexclust') # 导入数据集
data(nutrient) # 加载数据
row.names(nutrient) <- tolower(row.names(nutrient)) # 把行索引小写
head(nutrient)
#由于能量变化范围比其他变量更大,缩放数据有利于均衡各变量的影响。
nutrient_scaled <- scale(nutrient) # 数据标准化
head(nutrient_scaled)
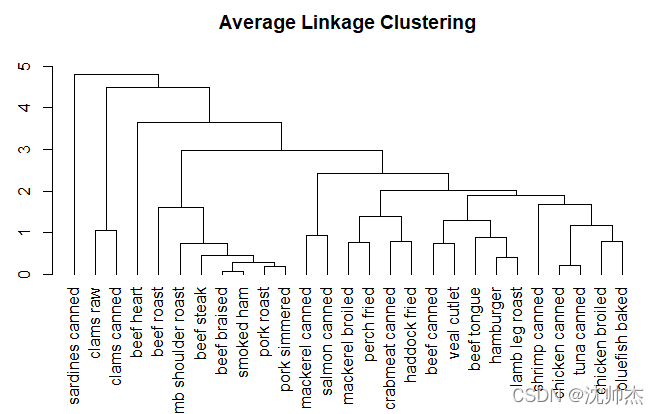
d <- dist(nutrient_scaled) # 计算距离 默认欧式距离
fit_average <- hclust(d, method="average") # 聚类
plot(fit_average, hang = -1, main = "Average Linkage Clustering")
K-means聚类与PAM聚类
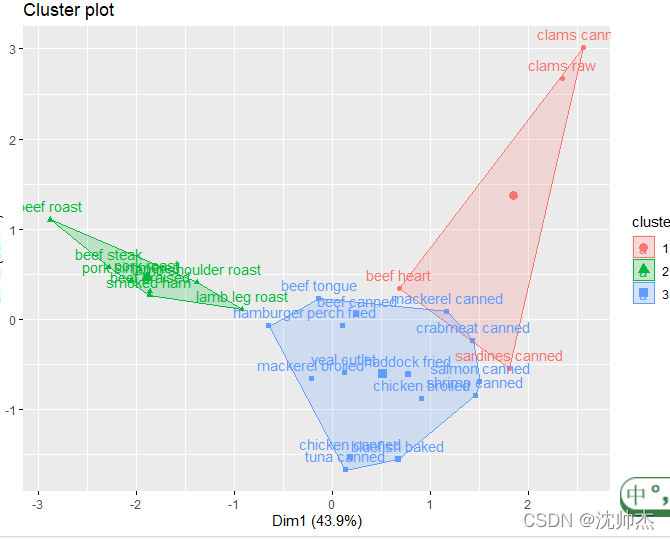
# K-means聚类,做之前用outlet去除异常值
library('flexclust') # 导入数据集
data(nutrient)
row.names(nutrient) <- tolower(row.names(nutrient)) # 把行索引小写
library(factoextra)
nutrient_scaled <- scale(nutrient) # 数据标准化
d <- dist(nutrient_scaled)
fviz_cluster(kmeans(d, 3), nutrient)
# 围绕中心点的划分(PAM)
library('flexclust') # 导入数据集
library(cluster)
data(nutrient)
row.names(nutrient) <- tolower(row.names(nutrient)) # 把行索引小写
nu_pam <- pam(nutrient, 3, metric="euclidean")
fviz_cluster(nu_pam, nutrient)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)