异常检测-高维数据
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档异常检测-高维数据前言一、Feature Baggingbootstrapbaggingfeature bagging二、Isolation Forests实现代码前言在实际场景中,很多数据集都是多维度的。随着维度的增加,数据空间的大小(体积)会以指数级别增长,使数据变得稀疏,这便是维度诅咒的难题。维度诅咒不止给异常检测带来了挑战,对
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
在实际场景中,很多数据集都是多维度的。随着维度的增加,数据空间的大小(体积)会以指数级别增长,使数据变得稀疏,这便是维度诅咒的难题。维度诅咒不止给异常检测带来了挑战,对距离的计算,聚类都带来了难题。例如基于邻近度的方法是在所有维度使用距离函数来定义局部性,但是,在高维空间中,所有点对的距离几乎都是相等的(距离集中),这使得一些基于距离的方法失效。在高维场景下,一个常用的方法是子空间方法。
集成是子空间思想中常用的方法之一,可以有效提高数据挖掘算法精度。集成方法将多个算法或多个基检测器的输出结合起来。其基本思想是一些算法在某些子集上表现很好,一些算法在其他子集上表现很好,然后集成起来使得输出更加鲁棒。集成方法与基于子空间方法有着天然的相似性,子空间与不同的点集相关,而集成方法使用基检测器来探索不同维度的子集,将这些基学习器集合起来。
一、Feature Bagging
Feature Bagging,基本思想与bagging相似,只是对象是feature。
bootstrap
Bagging一词是bootstrap aggregating(自助法聚合)的缩写,是对数据使用自助法构建一组(多个)模型的通用方法。估计统计量或模型参数的抽样分布,一个简单而有效的方法是,从样本本身中有放回地抽取更多的样本,并对每次重抽样重新计算统计量或模型。这一过程被称为自助法。自助法无须假设数据或抽样统计量符合正态分布。
在实践中,完全不必真正地多次复制样本。只需在每次抽取后,将观测值再放回总体中,即有放回地抽样。这一方式有效地创建了一个无限的总体,其中任意一个元素被抽取的概率在各次抽取中保持不变。使用自助法对规模为n的样本做均值重抽样的算法实现如下。
(1)抽取一个样本值,记录后放回总体。
(2)重复n次。
(3)记录n个重抽样的均值。
(4)重复步骤1~3多次,例如r次。
(5)使用r个结果:
a.计算它们的标准偏差(估计抽样均值的标准误差);
b.生成直方图或箱线图;
c.找出置信区间。
我们称r为自助法的迭代次数,r的值可任意指定。迭代的次数越多,对标准误差或置信区间的估计就越准确。上述过程的结果给出了样本统计量或估计模型参数的一个自助集,可以从该自助集查看统计量或参数的变异性。
bagging
自助法也可用于多变量数据。这时该方法使用数据行作为抽样单元,如下图所示,进而可在自助数据上运行模型,估计模型参数的稳定性(或变异性),或是改进模型的预测能力。我们也可以使用分类和回归树(也称决策树)在自助数据上运行多个树模型,并平均多个树给出的预测值(或是使用分类,并选取多数人的投票),这通常要比使用单个树的预测性能更好。这一过程被称为Bagging方法。
feature bagging
feature bagging属于集成方法的一种。集成方法的设计有以下两个主要步骤:
1.选择基检测器。这些基本检测器可以彼此完全不同,或不同的参数设置,或使用不同采样的子数据集。Feature bagging常用lof算法为基算法。下图是feature bagging的通用算法:
2.分数标准化和组合方法:不同检测器可能会在不同的尺度上产生分数。例如,平均k近邻检测器会输出原始距离分数,而LOF算法会输出归一化值。另外,尽管一般情况是输出较大的异常值分数,但有些检测器会输出较小的异常值分数。因此,需要将来自各种检测器的分数转换成可以有意义的组合的归一化值。分数标准化之后,还要选择一个组合函数将不同基本检测器的得分进行组合,最常见的选择包括平均和最大化组合函数
二、Isolation Forests
孤立森林(Isolation Forest)算法是周志华教授等人于2008年提出的异常检测算法,是机器学习中少见的专门针对异常检测设计的算法之一,方法因为该算法时间效率高,能有效处理高维数据和海量数据,无须标注样本,在工业界应用广泛。
孤立森林属于非参数和无监督的算法,既不需要定义数学模型也不需要训练数据有标签。孤立森林查找孤立点的策略非常高效。假设我们用一个随机超平面来切割数据空间,切一次可以生成两个子空间。然后我们继续用随机超平面来切割每个子空间并循环,直到每个子空间只有一个数据点为止。直观上来讲,那些具有高密度的簇需要被切很多次才会将其分离,而那些低密度的点很快就被单独分配到一个子空间了。孤立森林认为这些很快被孤立的点就是异常点。
用四个样本做简单直观的理解,d是最早被孤立出来的,所以d最有可能是异常。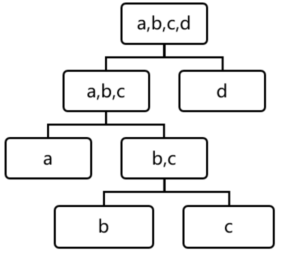
怎么来切这个数据空间是孤立森林的核心思想。因为切割是随机的,为了结果的可靠性,要用集成(ensemble)的方法来得到一个收敛值(蒙特卡洛方法),即反复从头开始切,平均每次切的结果。孤立森林由t棵孤立树组成,每棵树都是一个随机二叉树,也就是说对于树中的每个节点,要么有两个孩子节点,要么一个孩子节点都没有。树的构造方法和随机森林(random forests)中树的构造方法有些类似。流程如下: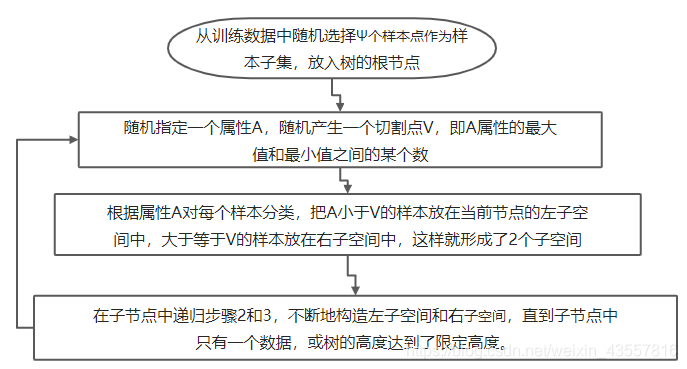
获得t棵树之后,孤立森林的训练就结束,就可以用生成的孤立森林来评估测试数据。
孤立森林检测异常的假设是:异常点一般都是非常稀有的,在树中会很快被划分到叶子节点,因此可以用叶子节点到根节点的路径长度来判断一条记录是否是异常的。和随机森林类似,孤立森林也是采用构造好的所有树的平均结果形成最终结果的。在训练时,每棵树的训练样本是随机抽样的。从孤立森林的树的构造过程看,它不需要知道样本的标签,而是通过阈值来判断样本是否异常。因为异常点的路径比较短,正常点的路径比较长,孤立森林根据路径长度来估计每个样本点的异常程度。
实现代码
代码如下(示例):
model_name = 'FeatureBagging'
model = FeatureBagging(contamination=0.1,
n_estimators = 30,
combination='max',
max_features=0.5)
model.fit(X_train)
y_train_pred = model.labels_
y_train_scores = model.decision_scores_
params = model.get_params()
y_test_pred = model.predict(X_test)
y_test_scores = model.decision_function(X_test)
model_name = 'IForest'
model = IForest()
model.fit(X_train)
y_train_pred = model.labels_
y_train_scores = model.decision_scores_
params = model.get_params()
y_test_pred = model.predict(X_test)
y_test_scores = model.decision_function(X_test) 。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)