pandas 10数据预处理
文章目录3.数据清洗3.1检测与处理缺失值1.缺失值的检测:2.缺失值的统计:3.缺失值的处理<1>.删除缺失值: `dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)`<2>.填充缺失值:<3>.DataFrame中用均值填充:3.2检测与处理重复值<1>.检测<
3.数据清洗
数据一般都是不完整的,有噪声和不一致的。数据清洗来填充缺失的数据值,光滑噪声,识别离群点并纠正数据中的不一致。
3.1检测与处理缺失值
1.缺失值的检测:
Pandas对象的所有描述性统计默认都不包含缺失数据。对于数值数据,Pandas使用浮点值NaN表示缺失数据。
函数 isnull()可以直接判断该列中的哪个数据为NaN。在Pandas中,缺失值表示为NA,意思是不可用。在统计应用中,NA数据可能是不存在的,可能是存在却没有被观察到的数据(比如数据采集过程发送问题)。当清洗数据用于分析时,最好直接对缺失数据进行分析,以判断数据采集问题或者缺失数据可能导致的偏差。Python内置的None值也会被了看成NA处理。
import pandas as pd
import numpy as np
obj = pd.Series(['a','b','c',np.nan,'e'])
print(obj)
obj.isnull()
0 a
1 b
2 c
3 NaN
4 e
dtype: object
0 False
1 False
2 False
3 True
4 False
dtype: bool
#df数据
df = pd.DataFrame(np.arange(12).reshape(3,4), columns=['a','b','c','d'])
df[:1] = np.nan
df[3] = np.nan
print(df)
df.isnull().sum()
a b c d 3
0 NaN NaN NaN NaN NaN
1 4.0 5.0 6.0 7.0 NaN
2 8.0 9.0 10.0 11.0 NaN
a 1
b 1
c 1
d 1
3 3
dtype: int64
#缺失值的统计
obj.isnull().sum()
1
2.缺失值的统计:
isnull().sum(),对于DataFrame数据,是按列计算的,如上;info也可以看缺失值信息。
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 a 2 non-null float64
1 b 2 non-null float64
2 c 2 non-null float64
3 d 2 non-null float64
4 3 0 non-null float64
dtypes: float64(5)
memory usage: 248.0 bytes
3.缺失值的处理
<1>.删除缺失值: dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
| 参数 | 说明 |
|---|---|
| axis | 默认为0,当某行出现缺失值时,将改行丢弃并返回;当值为1时,某列出现缺失值时,丢弃并返回 |
| how | 缺失值个数,默认any表示只要某行或列有缺失值就将之丢弃;为all表示全为缺失值时才丢弃 |
| thresh | 阀值设定,当行列中非缺失值的数量少于给定的值将之丢弃 |
| subset | 部分标签中删除某行列,e.g:suset=['a','b],即丢弃子列a,d中含有缺失值的行 |
| inplace | bool取值,默认为False,为True时对原数据操作,没有返回值 |
通过dropna方法删除有缺失值的行或列并返回;对于Series,返回仅含非空数据和索引值的Series,notnull具有和dropna相同效果。
from numpy import nan as NA
obj = pd.Series([1,3,NA,7,NA,11])
print(obj)
print("series:",obj.dropna())
not_data = obj.notnull()
print("notnull:",not_data)
print(obj[not_data])
0 1.0
1 3.0
2 NaN
3 7.0
4 NaN
5 11.0
dtype: float64
series: 0 1.0
1 3.0
3 7.0
5 11.0
dtype: float64
notnull: 0 True
1 True
2 False
3 True
4 False
5 True
dtype: bool
0 1.0
1 3.0
3 7.0
5 11.0
dtype: float64
对于DataFrame数据,dropna默认丢弃所有含有缺失值的行。
#默认DataFrame的默认dropna方法
df = pd.DataFrame({'a':[1,2,3],
'b':[1,NA,4],
'c':[NA,NA,NA]})
print(df)
print("df:",df.dropna())
a b c
0 1 1.0 NaN
1 2 NaN NaN
2 3 4.0 NaN
df: Empty DataFrame
Columns: [a, b, c]
Index: []
DataFrame的dropna方法带参数案例
df['d']=[1,3,5]#添加一列
df.loc[[0],['c']]=2.2#修改第一行列索引为‘d’的位置的数据
print(df)
df.dropna(axis=1)#返回所有列不为空的数据
a b c d
0 1 1.0 2.2 1
1 2 NaN NaN 3
2 3 4.0 NaN 5
a d
0 1 1
1 2 3
2 3 5
df.dropna(axis=1, how='all')#丢弃全为NA的列
a b c d
0 1 1.0 2.2 1
1 2 NaN NaN 3
2 3 4.0 NaN 5
df.dropna(axis=1,thresh=3)#每列有NA的至少具有3个NA才能存活
a d
0 1 1
1 2 3
2 3 5
<2>.填充缺失值:
pandas.DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None)
| 参数 | 说明 |
|---|---|
| value | 填充缺失值的标量值或字典对象 |
| method | 插值方式 ffill, bfill |
| axis | 代填充的轴,默认axis=0 |
| inplace | 默认返回新对象,为True对现有的进行就地修改。 |
| limit | 对于前向与后向填充可连续填充的最大数量 |
直接删除有缺失值的样本并不是太好的办法,所有可以设定一个值来填充,填充的方法有很多,数值型的则一般采用均值、中位数和众数等描述其集中趋势的统计量来填充;也可以采用拉格朗日或者牛顿中值法来填充。如果为类别型数据,一般选择众数填充。
#df.fillna(0):用0代替缺失值
#df.fillna(字典):实现对不同列填充不同值
#填充缺失值
df = pd.DataFrame(np.random.randn(5,3))
df.loc[:3,1] = NA
df.loc[:2,2] = NA
print(df)
df.fillna({1:0.88,2:0.15})
0 1 2
0 -1.370879 NaN NaN
1 0.519450 NaN NaN
2 0.335377 NaN NaN
3 1.678114 NaN -0.599663
4 -0.079574 0.582303 -1.079082
0 1 2
0 -1.370879 0.880000 0.150000
1 0.519450 0.880000 0.150000
2 0.335377 0.880000 0.150000
3 1.678114 0.880000 -0.599663
4 -0.079574 0.582303 -1.079082
#默认是创造一个副本 inplace=True这个参数设置是在原数据上修改 method='ffill/bfill'
#NA后面的值填充,限制三个
df.fillna(method='bfill',limit=3)
0 1 2
0 -1.370879 NaN -0.599663
1 0.519450 0.582303 -0.599663
2 0.335377 0.582303 -0.599663
3 1.678114 0.582303 -0.599663
4 -0.079574 0.582303 -1.079082
使用fillna可以传入Series的均值:
obj = pd.DataFrame([1.0,NA,3,NA,5])
print(obj)
obj.fillna(obj.mean())
0
0 1.0
1 NaN
2 3.0
3 NaN
4 5.0
0
0 1.0
1 3.0
2 3.0
3 3.0
4 5.0
<3>.DataFrame中用均值填充:
print(df)
df[2] = df[2].fillna(df[2].mean())#相当于修改列索引为2的这一列数据
print(df)
#df.fillna()
0 1 2
0 0.766047 NaN NaN
1 -0.810334 NaN NaN
2 -1.976835 NaN NaN
3 1.024778 NaN -0.022314
4 -1.785787 -0.384149 -1.174783
0 1 2
0 0.766047 NaN -0.598549
1 -0.810334 NaN -0.598549
2 -1.976835 NaN -0.598549
3 1.024778 NaN -0.022314
4 -1.785787 -0.384149 -1.174783
df.fillna?可以查看fillna的参数:
Signature:
df.fillna(
value=None,
method=None,
axis=None,
inplace=False,
limit=None,
downcast=None,
) -> 'Optional[DataFrame]'
Docstring:
Fill NA/NaN values using the specified method.
Parameters
----------
value : scalar, dict, S......
3.2检测与处理重复值
一般,数据中存在重复样本时,只保留一份就可以了,其余的都可以删除掉。
<1>.检测
DataFrame中使用duplicated方法判断各行是否有重复数据。该方法返回一个布尔类型的Series,反映每一行是否与之前的行重复。
# duplicated()
df = pd.DataFrame({'k1':['one','two'] * 3 + ['two'], 'k2':[1,1,2,3,1,4,4], 'k3':[1,1,5,2,1,4,4]})
print(df)
df.duplicated()
k1 k2 k3
0 one 1 1
1 two 1 1
2 one 2 5
3 two 3 2
4 one 1 1
5 two 4 4
6 two 4 4
0 False
1 False
2 False
3 False
4 True
5 False
6 True
dtype: bool
<2>.处理:
Pandas通过drop_duplicates删除重复的行,语法格式:pandas.DataFrame(Series).drop_duplicates(self, subset=None, keep='first', inplace=False)
去重时,当且仅当subset参数中的特征重复时,才会执行去重操作,可以选择保留那一个或者不保留。
| 参数 | 说明 |
|---|---|
| subset | 接收string或者sequence,表示进行去重的列,默认全部 |
| keep | 接收待定‘String’,表示重复时保留第几个数据,first第一个,last最后一个;False只要有重复都不保留,默认first |
| inplace | 接收布尔型数据,表示是否在原数据上操作 |
## drop_duplicates()
df.drop_duplicates()#每行各个字段都相同时去重
k1 k2 k3
0 one 1 1
1 two 1 1
2 one 2 5
3 two 3 2
5 two 4 4
df.drop_duplicates(['k2','k3'])#指定部分列相同时去重 keep默认保留数据是第一个出现的记录
k1 k2 k3
0 one 1 1
2 one 2 5
3 two 3 2
5 two 4 4
df.drop_duplicates(['k2','k3'], keep='last')
k1 k2 k3
2 one 2 5
3 two 3 2
4 one 1 1
6 two 4 4
3.3检测与处理异常值
异常值是指数据中存在的个别数值明显偏离其余数据的值.。在数据统计方法中一般采用散点图、箱型图和正态分布法则检测异常值。
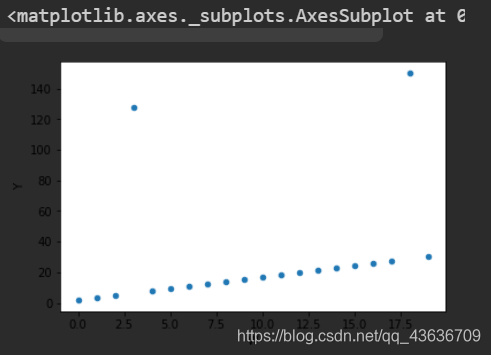
<1>.散点图
#异常数据的检测与处理
##散点图检测
import matplotlib.pyplot as plt
%matplotlib inline
df = pd.DataFrame(np.arange(20), columns=['W'])
df['Y'] = df['W']*1.5+2
print(df)
df.iloc[3,1] = 128
df.iloc[18,1] = 200
print(df)
df.plot(kind='scatter', x='W', y='Y')
W Y
0 0 2.0
1 1 3.5
2 2 5.0
3 3 6.5
4 4 8.0
5 5 9.5
6 6 11.0
7 7 12.5
8 8 14.0
9 9 15.5
10 10 17.0
11 11 18.5
12 12 20.0
13 13 21.5
14 14 23.0
15 15 24.5
16 16 26.0
17 17 27.5
18 18 29.0
19 19 30.5
W Y
0 0 2.0
1 1 3.5
2 2 5.0
3 3 128.0
4 4 8.0
5 5 9.5
6 6 11.0
7 7 12.5
8 8 14.0
9 9 15.5
10 10 17.0
11 11 18.5
12 12 20.0
13 13 21.5
14 14 23.0
15 15 24.5
16 16 26.0
17 17 27.5
18 18 200.0
19 19 30.5
<AxesSubplot:xlabel='W', ylabel='Y'>
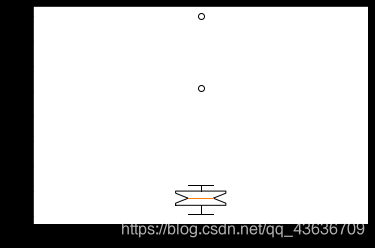
<2>.箱型图
箱型图使用数据中的五个统计量(最小值、下四分位数、中位数、上四分位数和最大值)来描述信息。粗略的可以看出数据是否具有对称性、分布的离散程度等信息。
import matplotlib.pyplot as plt
plt.boxplot(df['Y'].values, notch=True)
22
{'whiskers': [<matplotlib.lines.Line2D at 0x2374b71b670>,
<matplotlib.lines.Line2D at 0x2374b71b940>],
'caps': [<matplotlib.lines.Line2D at 0x2374b71bcd0>,
<matplotlib.lines.Line2D at 0x2374b7270a0>],
'boxes': [<matplotlib.lines.Line2D at 0x2374b71b250>],
'medians': [<matplotlib.lines.Line2D at 0x2374b727430>],
'fliers': [<matplotlib.lines.Line2D at 0x2374b7277c0>],
'means': []}

<3>.3σ原则:
若数据服从正态分布,在该原则下,异常值被定义为一组测定值中与平均值的偏差超过3倍标准差的值,因为在正态分布假设下,距离平均值出现的概率小于0.003.由小概率事件可以认为超过该原则之外的值为异常数据。
def outRange(S):
blidx = (S.mean() - 3 * S.std() > S)|(S.mean() + 3 * S.std() < S)
idx = np.arange(S.shape[0])[blidx]
outRange = S.iloc[idx]
return outRange
outier = outRange(df['Y'])
outier
18 200.0
Name: Y, dtype: float64
3.4数据转换
1.数据值替换
将查询到的数据替换为指定数据。在Pandas中通过replace进行数据值的替换。
import pandas as pd
data = {'姓名':['李红','小明','马芳','国志'],'性别':['0','1','0','1'],
'籍贯':['北京','甘肃',' ','上海']}
df = pd.DataFrame(data)
df['籍贯'].replace(' ','不详', inplace=True)
print(df)
df.replace(['不详','甘肃'], ['兰州', '兰州'], inplace=True)
print(df)
》》》》》:
姓名 性别 籍贯
0 李红 0 北京
1 小明 1 甘肃
2 马芳 0 不详
3 国志 1 上海
姓名 性别 籍贯
0 李红 0 北京
1 小明 1 兰州
2 马芳 0 兰州
3 国志 1 上海
也可以同时对不同值进行多值替换,参数的传入方式可以是列表,也可以是字典类型。传入的列表中,第一个列表为被替换的值,铁人个列表是对应替换的值。
2.使用函数或映射进行数据转换
可以自定义函数然后用map映射来实现。
#使用map方法映射数据
df['成绩'] = [58, 86, 91, 78]
print(df)
def grade(x):
if x > 90:
return '优'
elif 70 <= x < 90:
return '良'
elif 60 <= x < 70:
return '中'
else:
return '差'
df['等级'] = df['成绩'].map(grade)
print(df)
》》》》》:
姓名 性别 籍贯 成绩
0 李红 0 北京 58
1 小明 1 兰州 86
2 马芳 0 兰州 91
3 国志 1 上海 78
姓名 性别 籍贯 成绩 等级
0 李红 0 北京 58 差
1 小明 1 兰州 86 良
2 马芳 0 兰州 91 优
3 国志 1 上海 78 良
4.数据标准化
不同特征之间往往具有不同的量纲,由此造成数值之间的差异。为了消除特征之间量纲和取值范围的差异可能会造成影响,需要对数据进行标准化处理。
4.1离差标准化数据
离差标准化是对原始数据做的一种线性变换, 将原始数据的数值映射到[0, 1]区间。
4.2标准差标准化数据
标准差标准化又称为零均值标准化或 z分数标准化, 是当前使用最广泛的数据标准化方法。经过该方法的处理的数据均值为0,标准差为1 。
#对数据的离差标准化
def MinMaxScale(data):
data = (data - data.min()) / (data.max() - data.min())
return data
#对数据的标准差标准化
def StandardScale(data):
data = (data - data.mean()) / data.std()
return data
5.数据转化
数据分析的预处理处了数据清洗,数据合并和标准化之外,还有就是数据变换的过程,如类别型数据变换和连续性数据的离散化。
5.1类别型数据的哑变量处理
哑变量又称为虚拟变量,是用以反映质的属性的一个人工变量,是量化了的质变量,通常取值为0或1。用pandas中的get_dummies函数进行类别型特征数据的哑变量处理。
#数据的哑变量处理
df = pd.DataFrame([
['green', 'M', 10.1, 'class1'],
['red', 'L', 13.5, 'class2'],
['blue', 'XL', 15.3, 'class1']])
df.columns = ['color', 'size', 'prize', 'class label']
print(df)
pd.get_dummies(df)
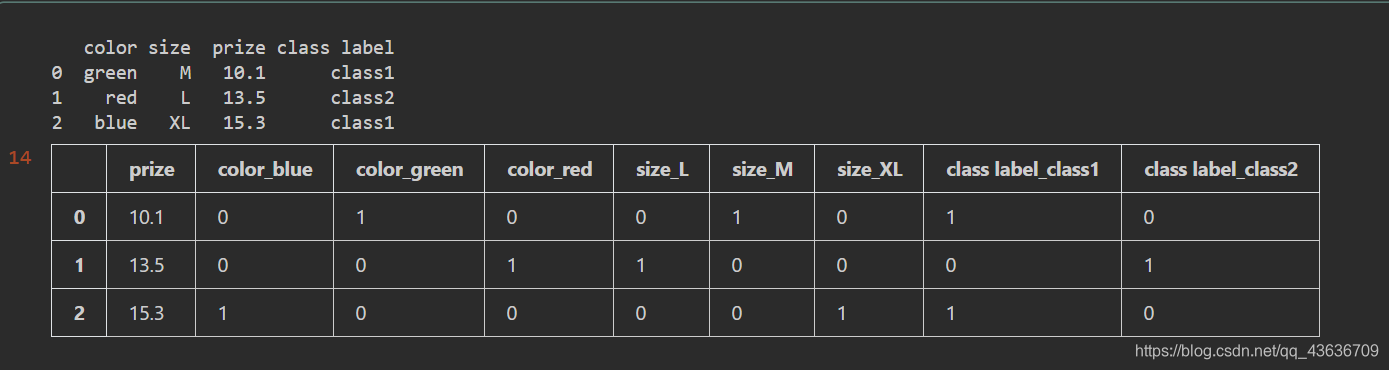
对于类别型特征,若取值有m个,则经过哑变量处理之后就变成了m个二元互斥特征,每次只有一个激活,使得数据变得稀疏。
5.2连续型变量的离散化
数据分析与统计的预处理阶段,经常会碰到年龄、消费等连续型数值,而很多模型算法,尤其是分类算法,都要求数据是离散的,因此要将数值进行离散化分段统计以提高数据区分度。
常用的离散化方法:等宽法、等频法、聚类分析法,这些方法在数据分析与挖掘模块都会有很详细的介绍和案例。
1.等宽法
将数据的值域划分成具有相同宽度的区间,区间个数由数据本身的特点决定或由用户指定。Pandas提供的cut函数,可以进行连续型数据的等宽离散化。cut函数的基本语法格式为:
pandas.cut(x, bins, right = True, labels = None, retbins = False, precision = 3)
# 参数说明:
x:接收array或者Series一维的待离散化数据
bins:接收int,list,tuple,array;int表示离散化后的类别数目,序列类型则表示进行切分的区间,每两个数的间隔为一个区间。
right:接收boolean,表示右侧是否闭合,默认True
labels:接收list,array,表示离散化后各个类别的名称,默认空
retbins:接收boolean,表示是否返回区间标签,默认false
precision:接收int,表示标签的精度,默认3
#cut函数等宽法
import numpy as np
np.random.seed(666)
score_list = np.random.randint(25, 100, size = 10)
print('原始数据:\n',score_list)
bins = [0, 59, 70, 80, 100]
score_cut = pd.cut(score_list, bins)
print(pd.value_counts(score_cut))
》》》》:
原始数据:
[27 70 55 87 95 98 55 61 86 76]
(80, 100] 4
(0, 59] 3
(59, 70] 2
(70, 80] 1
dtype: int64
使用等宽法离散化队数据分布具有较高的要求,若数据分布不均匀,那么各个类的数目也会表的不均匀。
2.等频法
可以借助cut函数定义相同数量的记录放进每个区间。
def SameRateCut(data,k):
k = 2
w = data.quantile(np.arange(0,1+1.0/k,1.0/k))
data = pd.cut(data,w)
return data
result = SameRateCut(pd.Series(score_list),3)
result.value_counts()
》》》》》:
(73.0, 98.0] 5
(27.0, 73.0] 4
dtype: int64
相较于等宽法,等频法避免了类分布不均匀的问题,但也有可能将数值非常接近的两个值分到不同的区间以满足每个区间对不同数据个数的要求。
3.聚类分析法
一维聚类的方法,包括两步,首先将连续性数据用聚类算法进行聚类,然后处理聚类得到的簇,为合并到一个簇的连续性数据做同一标记。聚类分析的离散化需要用户指定簇的个数来决定产生的区间数。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)