Zookeeper——数据结构与数据存储原理
摘要ZooKeeper 作为一个分布式协调服务,给出了在分布式环境下一致性问题的工业解决方案,目前流行的很多开源框架技术背后都有 ZooKeeper 的身影。那么 ZooKeeper 是如何做到这一点的,在平时开发中我们应该如何使用 ZooKeeper?要想了解这些问题,我们先要对 ZooKeeper 的基础知识进行全面的掌握。ZooKeeper 基础知识基本分为三大模块:数据模型ACL 权限控制
摘要
本博文将详细介绍Zookeeper的数据结构和数据存储相关的原理。ZooKeeper的基础知识基本分为三大模块:数据模型、ACL 权限控制、Watch 监控。其中,数据模型是最重要的,很多ZooKeeper 中典型的应用场景都是利用这些基础模块实现的。比如我们可以利用数据模型中的临时节点和 Watch 监控机制来实现一个发布订阅的功能。
一、zookeeper的数据模型
计算机最根本的作用其实就是处理和存储数据,作为一款分布式一致性框架,ZooKeeper 也是如此。数据模型就是 ZooKeeper 用来存储和处理数据的一种逻辑结构。就像我们用 MySQL 数据库一样,要想处理复杂业务。前提是先学会如何往里边新增数据。ZooKeeper 数据模型最根本的功能就像一个数据库。
配置文件
tickTime=2000
dataDir=/var/lib/zookeeper
clientPort=2181
服务启动
bin/zkServer.sh start
使用客户端连接服务器
bin/zkCli.sh -server 127.0.0.1:2181
这样单机版的开发环境就已经构建完成了,接下来我们通过 ZooKeeper 提供的 create 命令来创建几个节点,分别是:“/locks”“/servers”“/works”:
create /locks
create /servers
create /works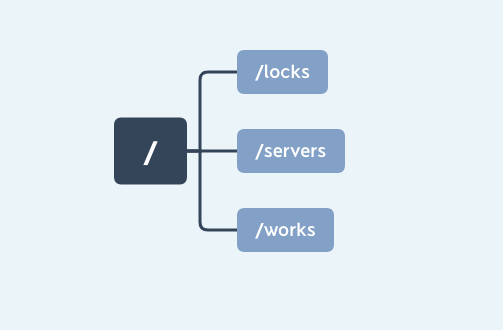
ZooKeeper 中的数据模型是一种树形结构,非常像电脑中的文件系统,有一个根文件夹,下面还有很多子文件夹。ZooKeeper 的数据模型也具有一个固定的根节点(/),我们可以在根节点下创建子节点,并在子节点下继续创建下一级节点。ZooKeeper 树中的每一层级用斜杠(/)分隔开,且只能用绝对路径(如“get /work/task1”)的方式查询 ZooKeeper 节点,而不能使用相对路径。具体的结构你可以看看下面这张图
二、znode节点类型与特性
知道了 ZooKeeper 的数据模型是一种树形结构,就像在 MySQL 中数据是存在于数据表中,ZooKeeper 中的数据是由多个数据节点最终构成的一个层级的树状结构,和我们在创建 MySOL 数据表时会定义不同类型的数据列字段,ZooKeeper 中的数据节点也分为持久节点、临时节点和有序节点三种类型:
2.1 持久节点
我们第一个介绍的是持久节点,这种节点也是在 ZooKeeper 最为常用的,几乎所有业务场景中都会包含持久节点的创建。之所以叫作持久节点是因为一旦将节点创建为持久节点,该数据节点会一直存储在 ZooKeeper 服务器上,即使创建该节点的客户端与服务端的会话关闭了,该节点依然不会被删除。如果我们想删除持久节点,就要显式调用 delete 函数进行删除操作。
2.2 临时节点
接下来我们来介绍临时节点。从名称上我们可以看出该节点的一个最重要的特性就是临时性。所谓临时性是指,如果将节点创建为临时节点,那么该节点数据不会一直存储在 ZooKeeper 服务器上。当创建该临时节点的客户端会话因超时或发生异常而关闭时,该节点也相应在 ZooKeeper 服务器上被删除。同样,我们可以像删除持久节点一样主动删除临时节点。
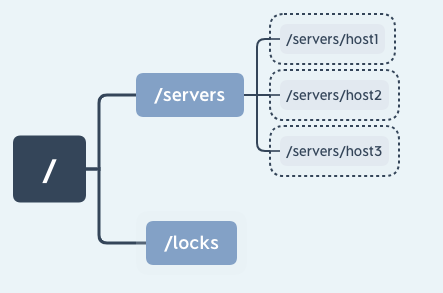
在平时的开发中,我们可以利用临时节点的这一特性来做服务器集群内机器运行情况的统计,将集群设置为“/servers”节点,并为集群下的每台服务器创建一个临时节点“/servers/host”,当服务器下线时该节点自动被删除,最后统计临时节点个数就可以知道集群中的运行情况。如下图所示:
2.3 有序节点
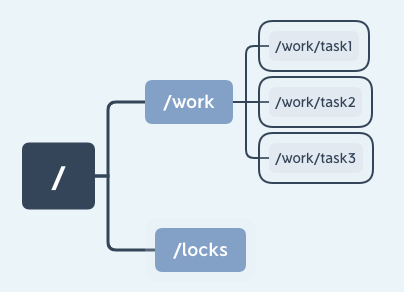
最后我们再说一下有序节点,其实有序节点并不算是一种单独种类的节点,而是在之前提到的持久节点和临时节点特性的基础上,增加了一个节点有序的性质。所谓节点有序是说在我们创建有序节点的时候,ZooKeeper 服务器会自动使用一个单调递增的数字作为后缀,追加到我们创建节点的后边。例如一个客户端创建了一个路径为 works/task- 的有序节点,那么 ZooKeeper 将会生成一个序号并追加到该节点的路径后,最后该节点的路径为 works/task-1。通过这种方式我们可以直观的查看到节点的创建顺序。
到目前为止我们知道在 ZooKeeper 服务器上存储数据的基本信息,知道了 ZooKeeper 中的数据节点种类有持久节点和临时节点等。上述这几种数据节点虽然类型不同,但 ZooKeeper 中的每个节点都维护有这些内容:一个二进制数组(byte data[]),用来存储节点的数据、ACL 访问控制信息、子节点数据(因为临时节点不允许有子节点,所以其子节点字段为 null),除此之外每个数据节点还有一个记录自身状态信息的字段 stat。
三、znode节点的状态结构
每个节点都有属于自己的状态信息,这就很像我们每个人的身份信息一样,我们打开之前的客户端,执行 stat /zk_test,可以看到控制台输出了一些信息,这些就是节点状态信息。
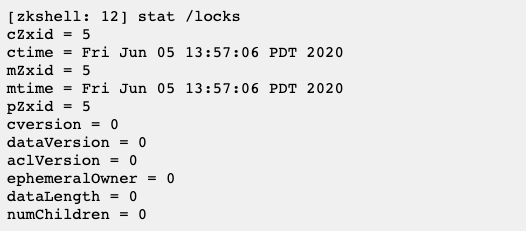
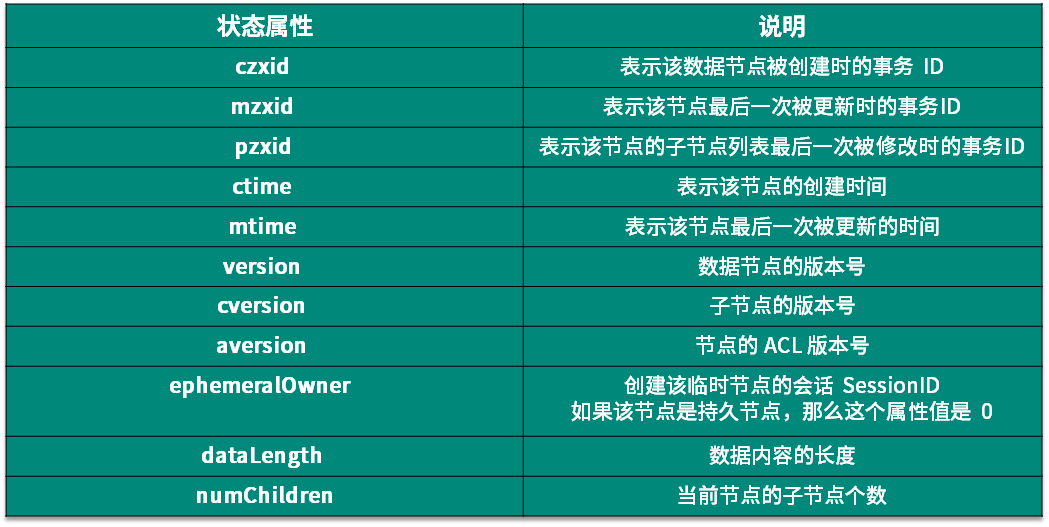
每一个节点都有一个自己的状态属性,记录了节点本身的一些信息,这些属性包括的内容我列在了下面这个表格里:
四、znode节点的版本
这里我们重点讲解一下版本相关的属性,在ZooKeeper中为数据节点引入了版本的概念,每个数据节点有 3 种类型的版本信息,对数据节点的任何更新操作都会引起版本号的变化。ZooKeeper 的版本信息表示的是对节点数据内容、子节点信息或者是 ACL 信息的修改次数。
4.1 使用 ZooKeeper 实现锁
学习了 ZooKeeper 的数据模型和数据节点的相关知识,下面我们通过实际的应用进一步加深理解。设想这样一个情景:一个购物网站,某个商品库存只剩一件,客户 A 搜索到这件商品并准备下单,但在这期间客户 B 也查询到了该件商品并提交了购买,于此同时,客户 A 也下单购买了此商品,这样就出现了只有一件库存的商品实际上卖出了两件的情况。为了解决这个问题,我们可以在客户 A 对商品进行操作的时候对这件商品进行锁定从而避免这种超卖的情况发生。
4.1.1 悲观锁的原理
悲观锁 悲观锁认为进程对临界区的竞争总是会出现,为了保证进程在操作数据时,该条数据不被其他进程修改。数据会一直处于被锁定的状态。
我们假设一个具有 n 个进程的应用,同时访问临界区资源,我们通过进程创建 ZooKeeper 节点 /locks 的方式获取锁。线程 a 通过成功创建 ZooKeeper 节点“/locks”的方式获取锁后继续执行,如下图所示:
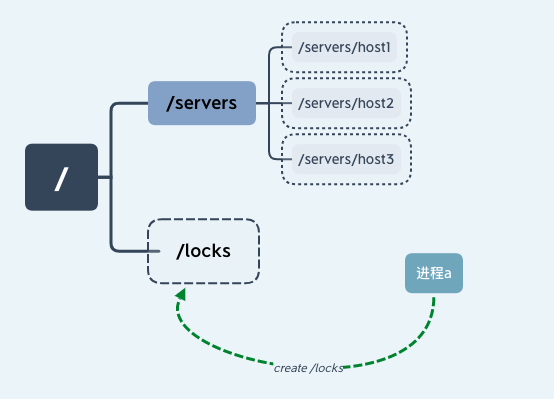
这时进程 b 也要访问临界区资源,于是进程 b 也尝试创建“/locks”节点来获取锁,因为之前进程 a 已经创建该节点,所以进程 b 创建节点失败无法获得锁。
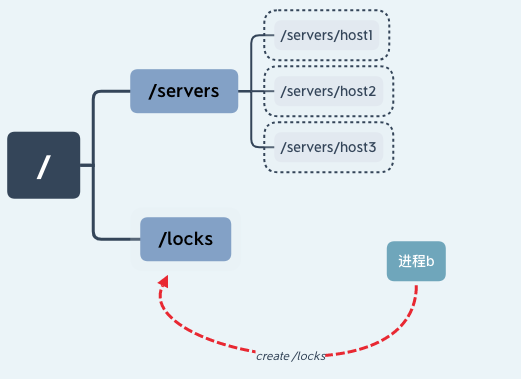
这样就实现了一个简单的悲观锁,不过这也有一个隐含的问题,就是当进程 a 因为异常中断导致 /locks 节点始终存在,其他线程因为无法再次创建节点而无法获取锁,这就产生了一个死锁问题。针对这种情况我们可以通过将节点设置为临时节点的方式避免。并通过在服务器端添加监听事件来通知其他进程重新获取锁。
4.1.2 乐观锁的原理
乐观锁认为,进程对临界区资源的竞争不会总是出现,所以相对悲观锁而言。加锁方式没有那么激烈,不会全程的锁定资源,而是在数据进行提交更新的时候,对数据的冲突与否进行检测,如果发现冲突了,则拒绝操作。
**乐观锁基本可以分为读取、校验、写入三个步骤。**CAS(Compare-And-Swap),即比较并替换,就是一个乐观锁的实现。CAS 有 3 个操作数,内存值 V,旧的预期值 A,要修改的新值 B。当且仅当预期值 A 和内存值 V 相同时,将内存值 V 修改为 B,否则什么都不做。
在 ZooKeeper 中的 version属性就是用来实现乐观锁机制中的“校验”的,ZooKeeper 每个节点都有数据版本的概念,在调用更新操作的时候,假如有一个客户端试图进行更新操作,它会携带上次获取到的 version 值进行更新。而如果在这段时间内,ZooKeeper 服务器上该节点的数值恰好已经被其他客户端更新了,那么其数据版本一定也会发生变化,因此肯定与客户端携带的 version 无法匹配,便无法成功更新,因此可以有效地避免一些分布式更新的并发问题。
在 ZooKeeper 的底层实现中,当服务端处理 setDataRequest 请求时,首先会调用 checkAndIncVersion 方法进行数据版本校验。ZooKeeper 会从 setDataRequest 请求中获取当前请求的版本 version,同时通过 getRecordForPath 方法获取服务器数据记录 nodeRecord, 从中得到当前服务器上的版本信息 currentversion。如果 version 为 -1,表示该请求操作不使用乐观锁,可以忽略版本对比;如果 version 不是 -1,那么就对比 version 和 currentversion,如果相等,则进行更新操作,否则就会抛出 BadVersionException 异常中断操作。

为什么 ZooKeeper不能采用相对路径查找节点呢?
这是因为 ZooKeeper 大多是应用场景是定位数据模型上的节点,并在相关节点上进行操作。像这种查找与给定值相等的记录问题最适合用散列来解决。因此 ZooKeeper 在底层实现的时候,使用了一个 hashtable,即 hashtableConcurrentHashMap<String, DataNode> nodes ,用节点的完整路径来作为 key 存储节点数据。这样就大大提高了 ZooKeeper 的性能。
五、ZooKeeper 数据存储底层实现
5.1 数据日志
在 ZooKeeper 服务运行的过程中,数据日志是用来记录 ZooKeeper 服务运行状态的数据文件。通过这个文件我们不但能统计 ZooKeeper 服务的运行情况,更可以在 ZooKeeper 服务发生异常的情况下,根据日志文件记录的内容来进行分析,定位问题产生的原因并找到解决异常错误的方法。
如何找到日志文件呢?在 ZooKeeper 的 zoo.cfg 配置文件中的 dataLogDir 属性字段,所指定的文件地址就是当前 ZooKeeper 服务的日志文件的存储地址。
5.1.1 搜集日志
ZooKeeper 是如何搜集程序的运行信息的。在统计操作情况的日志信息中,ZooKeeper 通过第三方开源日志服务框架 SLF4J 来实现的。
SLF4J是一个采用门面设计模式(Facade) 的日志框架。如下图所示,门面模式也叫作外观模式,采用这种设计模式的主要作用是,对外隐藏系统内部的复杂性,并向外部调用的客户端或程序提供统一的接口。门面模式通常以接口的方式实现,可以被程序中的方法引用。
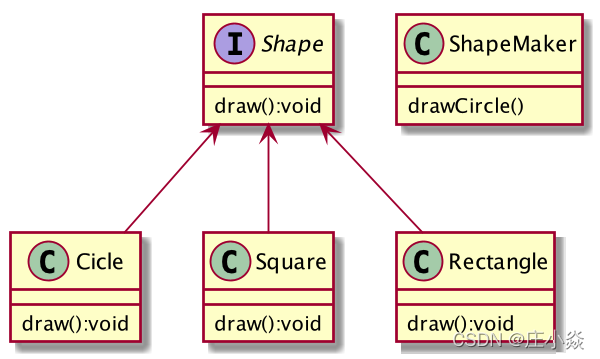
之后,当我们在本地项目中需要调用实现的会话功能时,直接调用 ShapeMaker 类,并传入我们要绘制的图形信息,就可以实现图形的绘制功能了。它使用起来非常简单,不必关心其底层是如何实现绘制操作的,只要将我们需要绘制的图形信息传入到接口函数中即可。
而在 ZooKeeper 中使用 SLF4J 日志框架也同样简单,如下面的代码所示,首先在类中通过工厂函数创建日志工具类 LOG,然后在需要搜集的操作流程处引入日志搜集函数 LOG.info 即可。
protected static final Logger LOG = LoggerFactory.getLogger(Learner.class);
LOG.info("Revalidating client: 0x" + Long.toHexString(clientId));
LOG.warn("Couldn't find the leader with id = "
+ current.getId());5.1.2 存储日志
搜集完的日志是什么样子的。在开头我们已经说过,系统日志的存放位置,在 zoo.cfg 文件中。假设我们的日志路径为dataDir=/var/lib/zookeeper,打开系统命令行,进入到该文件夹,就会看到如下图所示的样子,所有系统日志文件都放在了该文件夹下。
5.2 快照文件
ZooKeeper 中另一种十分重要的文件数据是快照日志文件。快照日志文件主要用来存储 ZooKeeper 服务中的事务性操作日志,并通过数据快照文件实现集群之间服务器的数据同步功能。
5.2.1 快照创建
在 ZooKeeper 的源码中定义了一个 SnapShot 接口类,在该接口中描述了 ZooKeeper 服务的相关属性和方法。其中 serialize 函数是用来将内存中的快照文件转存到本地磁盘中时的序列化操作。而 deserialize 的作用正好与其相反,是把快照文件从本地磁盘中加载到内存中时的反序列化操作。无论是序列化还是反序列化,整个快照所操作的数据对象是 ZooKeeper 数据模型,也就是由 Znode 组成的结构树。
public interface SnapShot {
long deserialize(DataTree dt, Map<Long, Integer> sessions)
throws IOException;
void serialize(DataTree dt, Map<Long, Integer> sessions,
File name, boolean fsync)
throws IOException;
File findMostRecentSnapshot() throws IOException;
void close() throws IOException;
}5.2.2 快照存储
创建完 ZooKeeper 服务的数据快照文件后,接下来就要对数据文件进行持久化的存储操作了。其实在整个 ZooKeeper 中,随着服务的不同阶段变化,数据快照存放文件的位置也随之变化。存储位置的变化,主要是内存和本地磁盘之间的转变。当 ZooKeeper 集群处理来自客户端的事务性的会话请求的时候,会首先在服务器内存中针对本次会话生成数据快照。当整个集群可以执行该条事务会话请求后,提交该请求操作,就会将数据快照持久化到本地磁盘中,如下图所示。
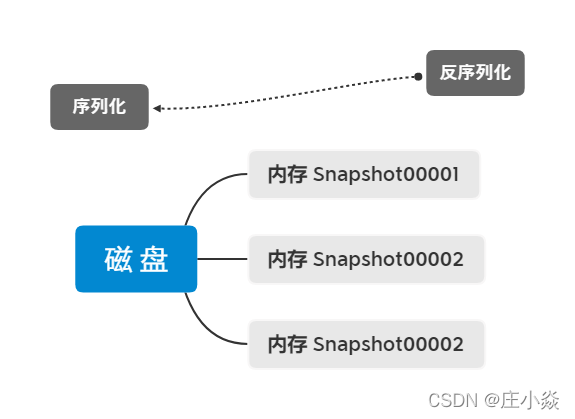
存储到本地磁盘中的数据快照文件,是经过 ZooKeeper 序列化后的二进制格式文件,通常我们无法直接查看,但如果想要查看,也可以通过 ZooKeeper 自带的 SnapshotFormatter 类来实现。如下图所示,在 SnapshotFormatter 类的内部用来查看快照文件的几种函数分别是: printDetails 函数,用来打印日志中的数据节点和 Session 会话信息;printZnodeDetails 函数,用来查看日志文件中节点的详细信息,包括节点 id 编码、state 状态信息、version 节点版本信息等。
public class SnapshotFormatter {
private void printDetails(DataTree dataTree, Map<Long, Integer> sessions)
private void printZnodeDetails(DataTree dataTree)
private void printZnode(DataTree dataTree, String name)
private void printSessionDetails(DataTree dataTree, Map<Long, Integer> sessions)
private void printStat(StatPersisted stat)
private void printHex(String prefix, long value)
}无论是数据日志文件,还是数据快照文件,最终都会存储在本地磁盘中。而从文件的生成方式来看,两种日志文件的不同是:数据日志文件实施性更高,相对的产生的日志文件也不断变化,只要 ZooKeeper 服务一直运行,就会产生新的操作日志数据;而数据快照并非实时产生,它是当集群中数据发生变化后,先在内存中生成数据快照文件,经过序列化后再存储到本地磁盘中。
博文参考

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)