大数据之数仓建模
数仓建模理论基础文章目录数仓建模理论基础一、范式理论1.1函数依赖例表1.1.1完全函数依赖1.1.2部分函数依赖1.1.3传递函数依赖二、范式区分1.1第一范式1.2第二范式1.2第三范式三、维度表和事实表3.1维度表3.2事实表3.3加深理解一、范式理论1.1函数依赖例表1.1.1完全函数依赖(学号,课程)推出 分数 ,但是单独用学号推断不出来分数,那么就可以说:分数完全依赖(学号,课程)即:
数仓理论
文章目录
一、范式理论
1.1函数依赖例表
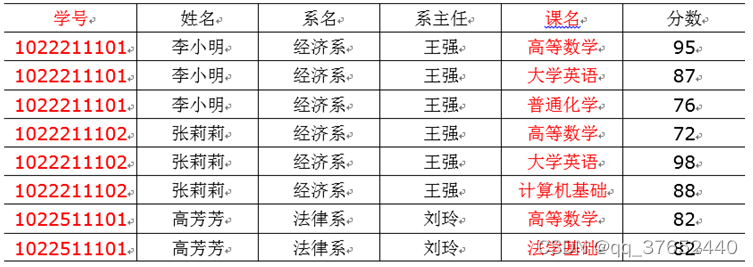
1.1.1完全函数依赖
(学号,课程)推出 分数 ,但是单独用学号推断不出来分数,那么就可以说:分数完全依赖(学号,课程)
即:通过AB能得出C,但是A或B单独得不出C,那么说C完全依赖于AB
1.1.2部分函数依赖
(学号,课程)推出姓名,因为学号可以直接推出姓名,所以姓名部分依赖于 (学号课程)
即:通过AB能得出C,通过A单独得到C,或者通过B单独得到C,那么说C部分依赖于AB
1.1.3传递函数依赖
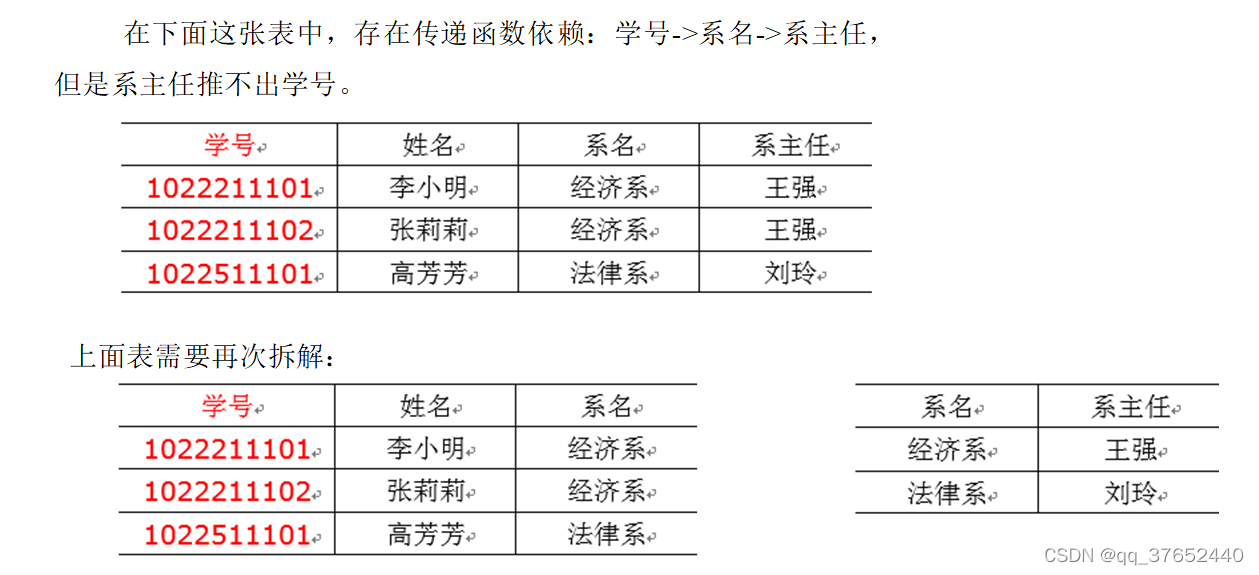
学号推出系名,系名推出系主任,但是,系主任退不出学号,系主任主要依赖于系名。这种情况可以说:系主任传递依赖于学号。
即:通过A得到B,通过B得到C,但是C得不到A,那么说C传递依赖于A。
二、范式区分
1.1第一范式
第一范式核心原则:属性不可分割


实际上,1NF是所有关系型数据库的最基本要求,在关系型数据库管理系统(RDBMS),例如mysql,SQL server,Oracle中创建数据表的时候,如果数据表的设计不符合这个最基本要求,那么操作一定是不能成功的。也就是说RDBMS中已经存在的数据表,一定是符合1NF范式的
1.2第二范式
第二范式2NF核心原则:不能存在部分函数依赖
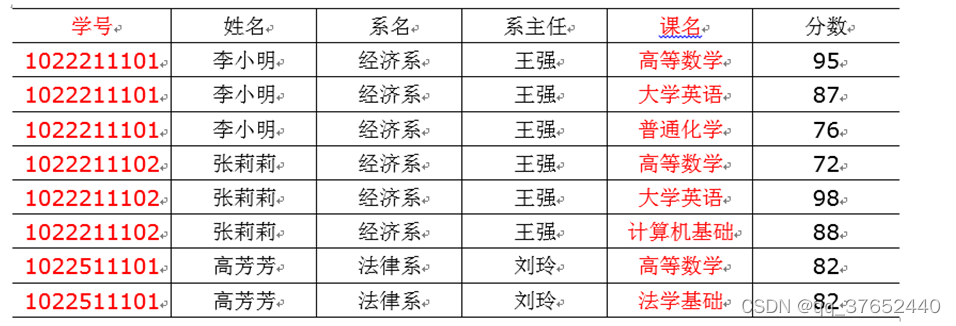 以上表格明显存在部分函数依赖、比如:这张表的主键是(学号,课名),分数完全依赖(学号,课名),但是姓名不是完全依赖于(学号,课名)
以上表格明显存在部分函数依赖、比如:这张表的主键是(学号,课名),分数完全依赖(学号,课名),但是姓名不是完全依赖于(学号,课名)

1.2第三范式
第三范式3NF核心原则:不能存在传递函数依赖
三、维度表和事实表
3.1维度表
维度表:一般是对事实的描述信息、每张维度表对应现实世界的一个对象或者概念、例如:用户,商品,日期,地区等。
维度表特征:
- 维度表的范围很宽(具有多个属性,列比较多)
- 跟事实表相比,行数相对比较小
- 内容相对固定:编码表
3.2事实表
事实表的每一行数据代表一个业务事件(下单,支付,退款,评价等)。“事实”这个术语表示的是业务事件的度量值(可统计次数、个数、金额等),例如,2020年5月21日,宋宋老师在京东花了250块钱买了一瓶海狗人参丸。维度表:时间、用户、商品、商家。事实表:250块钱、一瓶。
每一个事实表的行包括:具有可加性的数值型的度量值、与维表相连接的外键,通常具有两个和两个以上的外键。
事实表的特征:
- 非常的大
- 内容相对的窄:列数较少(主要是外键id和度量值)
- 经常发生变化,每天会新增加很多。
3.3加深理解
理解加深:可以java中的面向对象做拟合,例如一个对象实例可以理解为维度表,此对象的属性有用户,商品,日期等。而对象中的方法类似于事实表,代表了某一种行为

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)