基于城市场景下求解无人机三维路径规划的Q-learning 算法研究,提供完整MATLAB代码
在城市场景下,无人机的状态空间应能够全面描述其在三维空间中的位置和周围环境信息。将飞行空间划分为三维网格,每个网格点对应一个状态,用三维坐标 (x,y,z) 表示无人机的位置。同时,考虑到无人机需要感知周围障碍物的信息以避免碰撞,将附近障碍物的距离和方向等信息也纳入状态空间。
随着无人机在城市环境中的广泛应用,其三维路径规划问题日益受到关注。城市场景具有复杂多变的障碍物布局和严格的飞行安全要求,传统的路径规划算法往往难以满足实时性和最优性需求。本文提出了一种基于强化学习 Q-learning 算法的无人机三维路径规划方法,通过合理定义状态空间、动作空间和奖励函数,使无人机能够在城市场景中自主学习最优路径。实验结果表明,该算法能够有效避开障碍物,规划出较优的飞行路径,具有较高的成功率和适应性,为无人机在城市环境中的安全高效飞行提供了一种有效的解决方案。
一、引言
在城市环境中,无人机的应用场景不断拓展,如物流配送、航拍测绘、交通监控等。然而,城市场景的复杂性给无人机的路径规划带来了巨大挑战。建筑物、信号塔等障碍物密集且形状各异,飞行空间受限,同时还需考虑飞行安全、能量消耗等多方面因素。传统的路径规划算法,如 A* 算法、Dijkstra 算法等,在三维复杂空间中存在计算复杂度高、难以适应动态环境等问题。强化学习作为一种通过与环境交互学习最优策略的机器学习方法,为无人机路径规划提供了新的思路。Q-learning 算法作为强化学习中的典型代表,具有无需环境模型、通过试错学习等优点,适合应用于复杂多变的城市场景。本文旨在深入研究基于 Q-learning 算法的无人机三维路径规划方法,以提高无人机在城市环境中的自主导航能力和路径规划效率。
二、相关理论基础
(一)无人机三维路径规划问题描述
无人机三维路径规划的目标是在满足一定约束条件(如飞行安全、能量限制等)下,从起始点 [S] 到目标点 [T] 规划一条最优路径。在城市场景中,路径优化指标通常包括路径长度最短、飞行时间最短、能量消耗最少等。无人机的飞行姿态和动力学特性也会影响路径规划,但为简化问题,本文主要关注几何路径规划,暂不考虑复杂的动力学模型。
(二)强化学习基础
强化学习是一种目标导向的学习方法,智能体通过与环境进行交互,根据环境反馈的奖励信号来学习最优行为策略,以最大化累积奖励。强化学习的基本要素包括智能体(Agent)、环境(Environment)、状态(State)、动作(Action)、奖励(Reward)和策略(Policy)。智能体根据当前状态选择动作,环境接收动作后发生变化并产生新的状态和奖励信号反馈给智能体。通过不断的试错过程,智能体逐渐学习到在不同状态下采取何种动作能够获得最大累积奖励。
(三)Q-learning 算法原理
Q-learning 算法是一种基于价值的强化学习方法,其核心是学习一个 Q 表,用于表示在给定状态下采取某个动作所能获得的预期累积奖励。Q 表的更新公式为:
Q(s,a) = Q(s,a) + α [r + γ max Q(s’,a’) - Q(s,a)]
其中,Q(s,a) 表示在状态 s 下采取动作 a 的 Q 值;α 是学习率,控制新旧信息的融合程度,取值范围在 [0,1] 之间;r 是当前动作获得的即时奖励;γ 是折扣因子,用于衡量未来奖励的权重,取值范围在 [0,1] 之间;max Q(s’,a’) 是下一个状态 s’ 下所有可能动作 a’ 中的最大 Q 值。通过不断地更新 Q 表,智能体最终能够收敛到最优策略。
三、基于 Q-learning 的无人机三维路径规划算法设计
(一)状态空间定义
在城市场景下,无人机的状态空间应能够全面描述其在三维空间中的位置和周围环境信息。将飞行空间划分为三维网格,每个网格点对应一个状态,用三维坐标 (x,y,z) 表示无人机的位置。同时,考虑到无人机需要感知周围障碍物的信息以避免碰撞,将附近障碍物的距离和方向等信息也纳入状态空间。
(二)动作空间确定
无人机的动作空间定义为其在三维空间中可能的飞行方向和速度变化。为了简化问题并保证飞行的连续性和稳定性,将动作空间离散化。同时,对每次移动的步长进行限制,确保无人机在安全的飞行区域内移动,并且步长的选择应根据实际场景的网格大小和飞行要求进行调整。
(三)奖励函数设计
奖励函数的设计对 Q-learning 算法的学习效果至关重要,它引导无人机朝着最优路径方向移动,同时避开障碍物。
(四)状态转移模型
在城市场景中,无人机的状态转移由其动作和环境约束决定。当无人机在当前状态 s 下采取动作 a 后,根据动作的位移向量移动到新的位置,同时更新周围障碍物的信息,得到下一个状态 s’。状态转移过程中需要考虑飞行区域边界、障碍物边界等约束条件,确保无人机不会飞出安全区域或穿过障碍物。例如,如果某个动作会导致无人机超出飞行边界或与障碍物碰撞,则该动作被禁止,无人机停留在当前状态,并给予相应的惩罚奖励。
(五)Q-learning 算法实现步骤
-
初始化 Q 表,将所有 Q 值设为 0。Q 表的维度为 |S|×|A|,其中 |S| 是状态空间的大小,|A| 是动作空间的大小。
-
确定无人机的初始状态 s_0,通常为起始点位置及相关环境信息。
-
设置算法的终止条件,如最大迭代次数、成功到达目标点的次数要求或 Q 表的收敛阈值等。
-
对于每一次迭代:
- 根据当前状态 s,选择一个动作 a。采用 ε-greedy 策略,在探索与利用之间进行平衡。即以概率 ε 随机选择动作,以概率 1 - ε 选择当前 Q 表中对应状态 s 的最大 Q 值的动作。ε 的取值一般在初始阶段较大,随着学习过程逐渐减小,以保证算法在初期有足够的探索能力,后期则更多地利用已学到的知识进行决策。
- 执行动作 a,观察环境反馈的奖励 r 以及下一个状态 s’。
- 根据 Q-learning 更新公式,更新 Q 表中对应 (s,a) 的 Q 值:
Q(s,a) = Q(s,a) + α [r + γ max Q(s’,a’) - Q(s,a)] - 将状态更新为 s’,即 s = s’。
- 判断是否满足终止条件,如无人机到达目标点、超出最大迭代次数或 Q 值变化小于收敛阈值等。若满足,则结束算法;否则,继续下一次迭代。
-
算法结束后,根据 Q 表确定最优路径。从起始状态开始,每次选择 Q 值最大的动作,直到到达目标状态,所经过的路径即为最优路径。
四、实验与结果分析
(一)实验环境设置及部分MATLAB代码
为了验证基于 Q-learning 的无人机三维路径规划算法的性能,构建了一个城市场景仿真模型。该模型包含不同高度、形状和分布密度的建筑物,模拟真实的飞行环境。无人机的起始点和目标点随机设置在场景中,并且在飞行过程中需要避开各种障碍物。同时,设置飞行区域边界,限制无人机的飞行范围。
% 设置超参数
learning_rate = 0.1;
%学习率,它决定了新获得的信息覆盖旧信息的程度。
discount_factor = 0.9;
% 折扣因子,表示代理对当前奖励的偏好高于对未来奖励的偏好。
% 折现因子为1意味着代理对未来奖励的重视程度与眼前奖励一样高。
% 如果折扣系因子小于1,那么未来奖励的价值就会低于当前奖励。通常在0.9到0.99之间。
exploration_rate = 0.1;
% 探索率,它决定了智能体探索随机行为的概率。
num_episodes = 50000;
% 训练次数,表示代理将与环境交互学习的次数。
% Q-learning算法主循环
% 这一部分设置集的数量,并将代理的状态初始化为1。
for episode = 1:num_episodes
state = 1; % 初始状态
done = false;
while ~done
% 在这里,智能体使用epsilon-greedy策略选择一个动作。
% 对于exploration_rate,它选择随机行动;否则,选择当前状态下q值最高的动作。
if rand() < exploration_rate
action = randi(num_actions); % 随机选择动作
else
[~, action] = max(Q(state, :)); % 选择最优动作
end
% 执行动作并观察反馈
% 代理采取行动,转移到下一个状态(next_state),并根据环境接收奖励。
next_state = takeAction(state, action, size(environment));
reward = getReward(next_state, environment);
% 更新Q值,使用Q-learning更新规则,更新当前状态-动作对的q值。
Q(state, action) = Q(state, action) + learning_rate * (reward + discount_factor * max(Q(next_state, :)) - Q(state, action));
(二)实验结果与分析
- 路径规划效果
实验结果显示,基于 Q-learning 的算法能够成功规划出从起始点到目标点的可行路径,从下图可以看到无人机有效地避开了建筑物等障碍物,沿着相对平滑且较短的路径到达目标点。
(1)10x10x100地图下
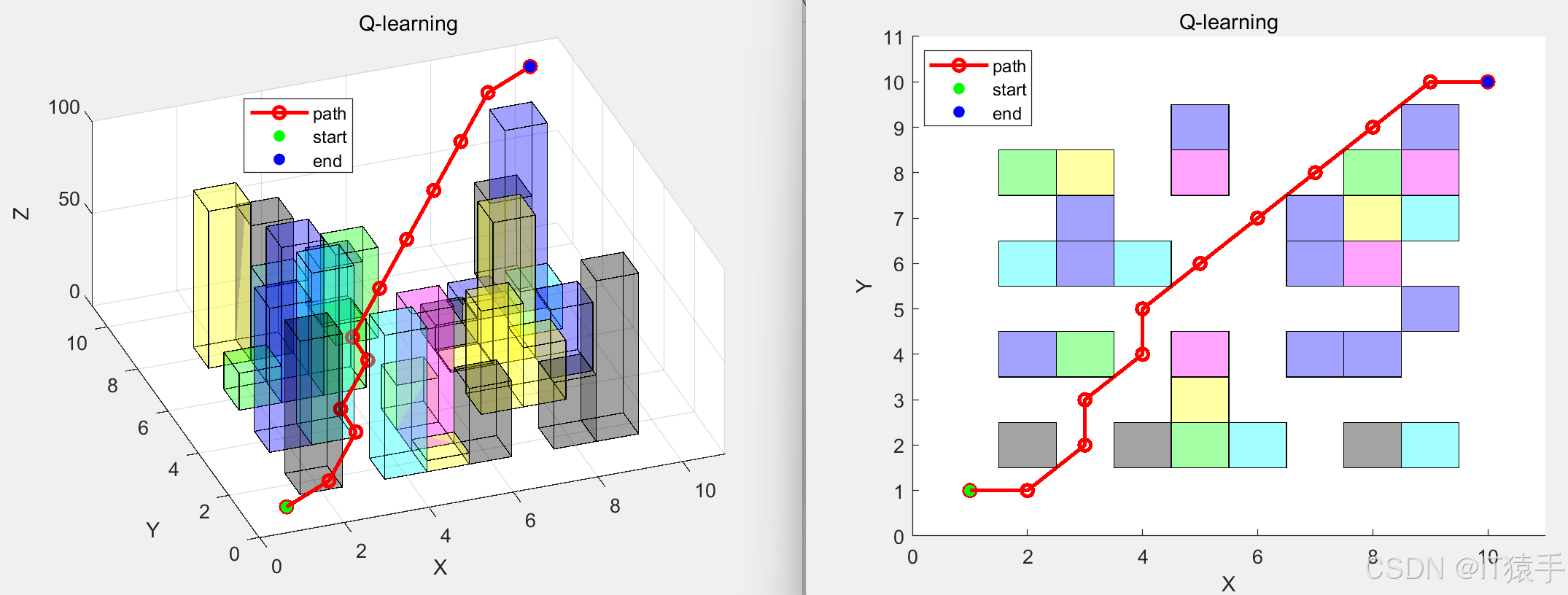
路径坐标:
1 1 1
1 2 11
2 3 22
3 3 23
4 4 34
5 4 35
6 5 46
7 6 57
8 7 68
9 8 79
10 9 90
10 10 100
(2)20x20x400地图下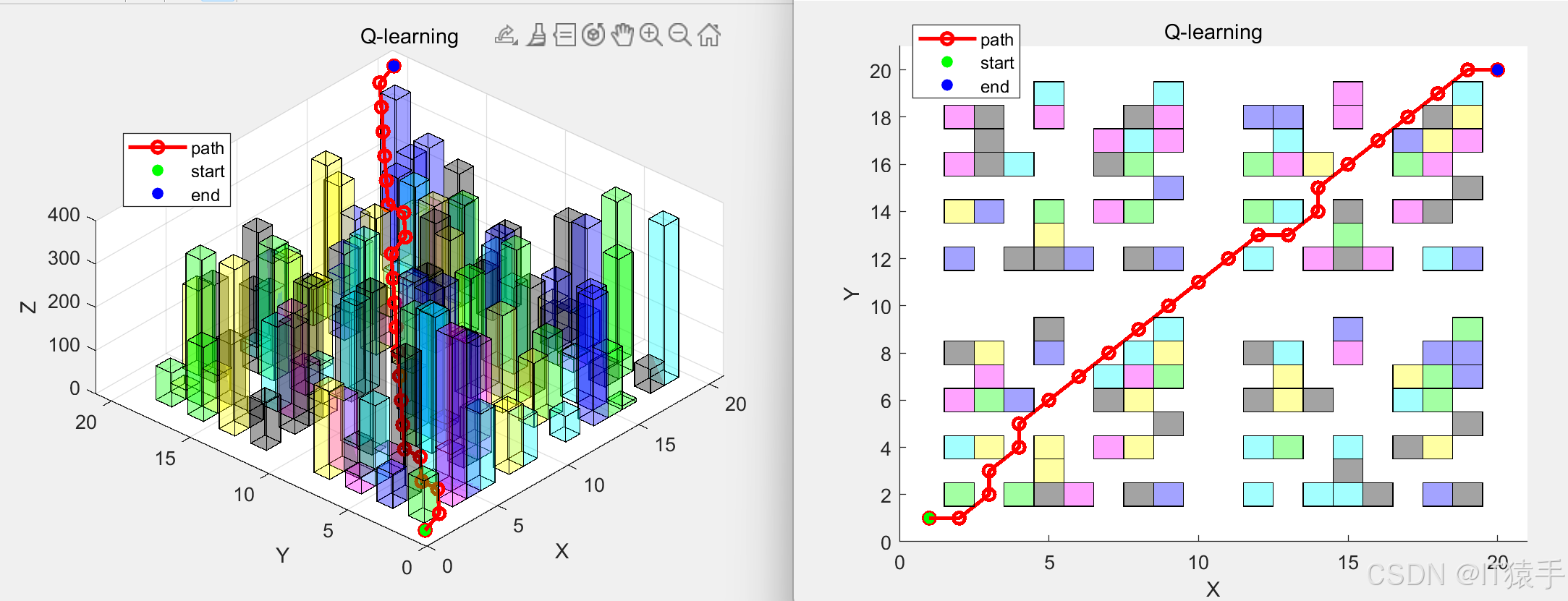
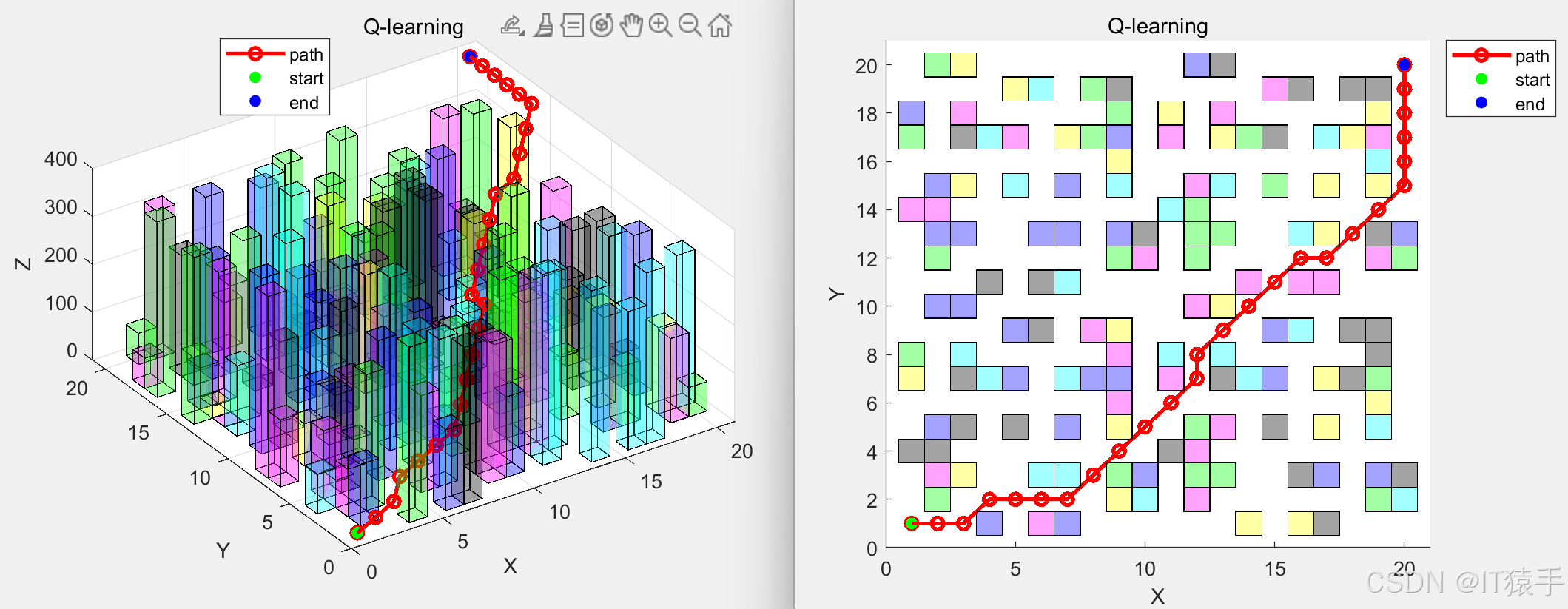
五、完整MATLAB代码见下方名片
参考文献:
[1] Sutton R S, Barto A G. Reinforcement Learning: An Introduction[M]. MIT Press, 2018.
[2] Watkins C J C H, Dayan P. Q-learning[J]. Machine Learning, 1992, 8(3-4): 279-292.
[3] 郑南山, 王建业, 贾钢. 无人机路径规划技术研究进展[J]. 航空学报, 2019, 40(3): 1-20.
[4] 陈明, 张伟, 李强. 城市场景下无人机路径规划方法综述[J]. 控制与决策, 2020, 35(6): 1185-1196.
[5] Silver D, et al. Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016, 529(7587): 484-489.
[6] Mnih V, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533.
[7] 胡晓飞, 王晓华, 刘洋. 基于深度强化学习的移动机器人路径规划研究进展[J]. 机器人, 2021, 43(2): 141-154.
[8] 王刚, 李明, 张强. 城市环境中无人机三维路径规划的 A* 算法改进[J]. 计算机工程与应用, 2018, 54(12): 56-61.
[9] 刘洋, 赵伟, 张涛. 基于遗传算法的无人机路径规划方法[J]. 西北工业大学学报, 2017, 35(3): 456-462.
[10] 陈亮, 李华, 王强. 基于粒子群优化算法的无人机路径规划研究[J]. 系统仿真学报, 2016, 28(6): 1320-1326.

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 25
25 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)