简单易懂的数据标注
众所周知,人工智能的三个关键要素:算法、算力、数据。我们今天主要讲讲数据,那数据标注就是逃不开的话题。
众所周知,人工智能的三个关键要素:算法、算力、数据。
我们今天主要讲讲数据,那数据标注就是逃不开的话题
什么是数据?
数据可以分为文本、音频、图片、视频等形式,我们从数据分类聊一聊
数据可以分为结构化数据和非结构化数据
音频、图片、视频形式的数据多为非结构化数据,而文本类数据可以分为结构化数据和非结构化数据
结构化数据是指具有固定格式和明确结构的数据,通常以表格形式(如数据库中的行和列)存储,每个数据项都有明确的字段名和数据类型,便于计算机程序直接处理和分析。
白话文是 Excel 表格的数据大约是结构化数据
什么是数据标注?
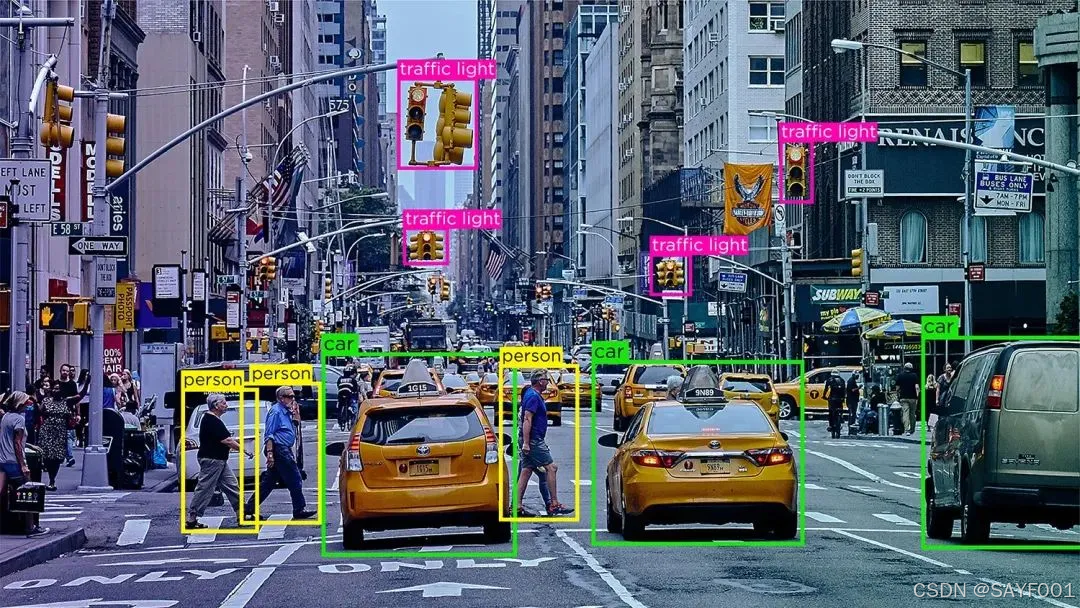
通过添加有意义的标签、分类或注释,帮助将非结构化数据(如图像、文本、视频或音频)转换为结构化的带标签的数据集
对数据进行加工处理,通过添加标签、注释或标记,使其转化为计算机可识别的结构化数据的过程。简单理解,就是为数据“打标签”。
那为什么要进行数据标注?
目的是让AI模型能“理解”并学习数据中的特征和规律。
因为大型语言模型时代,数据标注质量直接决定了模型的智能上限。
数据一直被当作人工智能的“血液”,算法可以理解为人的大脑智商高低,算力理解为人的健康寿命
数据标注的过程就是通过人工贴标的方式,为机器系统提供大量学习的样本,没有标注数据,模型就无法从海量信息中提取出有价值的知识。只有经过数据标注后的数据,才能为人工智能所利用,提高应用的准确性和可靠性。
怎么进行数据标注
对文本进行特征标记,对其打上具体的语义、构成、语境、目的、情感等数据标签,通过标注好的训练数据,可以教会机器如何来识别文本中所隐含的意图或者情感,使机器可以更好地理解语言。

文本数据标注有文本分类、实体识别、问答系统及情绪分析等多种标注任务。
- 文档分类:标注者可以根据文档内容将其归类到相应的类别中,比如科技、医疗、汽车类别。
- 命名实体识别:标注者随后会在文本中标注出这些实体,并将其归类到相应的类别中,比如需要识别的实体类型(如人名、地名等)
- 问答系统:标注者将问题与答案进行关联,以生成训练数据,就是QA的文本数据。
- 情绪分析:标注者随后会阅读文本内容,并根据其表达的情绪倾向进行标注,比如情绪标签(如正面、负面、中性)。
"前面有多少智能,后面就有多少人工"——这句调侃道出了数据标注工作的本质。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)