爬虫实例7 爬取豆瓣电影数据 (json+ajax)
什么是异步加载
什么是异步加载(ajax)、同步加载、延迟加载?
同步加载:
同步模式又称阻塞模式,会阻止浏览器的后续处理,停止了后续的文件的解析,执行,如图像的渲染。流览器之所以会采用同步模式,是因为加载的js文件中有对dom的操作,重定向,输出document等默认行为,所以同步才是最安全的。通常会把要加载的js放到body结束标签之前,使得js可在页面最后加载,尽量减少阻塞页面的渲染。这样可以先让页面显示出来
异步加载:
异步加载也叫非阻塞模式加载,浏览器在下载js的同时,同时还会执行后续的页面处理。
在script标签内,用js创建一个script元素并插入到document中,这种就是异步加载js文件了。同步加载流程是瀑布模型,异步加载流程是并发模型
延迟加载:
有些 js 代码并不是页面初始化的时候就立刻需要的,而稍后的某些情况才需要的。延迟加载就是一开始并不加载这些暂时不用的js,而是在需要的时候或稍后再通过js 的控制来异步加载。
也就是将 js 切分成许多模块,页面初始化时只加载需要立即执行的 js ,然后其它 js 的加载延迟到第一次需要用到的时候再加载。
特别是页面有大量不同的模块组成,很多可能暂时不用或根本就没用到。
就像图片的延迟加载,在图片出现在可视区域内时(在滚动条下拉)才加载显示图片
什么是json?
json就是一种在各个编程语言中流通的数据格式,负责不同编程语言中的数据传递和交互。
类似于:国际通用语言-英语,中国56个民族不同地区的通用语言-普通话
知道了什么是异步加载,什么是json,我们用一个爬虫来看看具体的实现。
目标地址:https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=&start=0
使用异步加载的代表网站有豆瓣,今日头条等。我们用豆瓣举例。
首先我们打开抓包工具,发现我们要找的的数据在页面源代码中是没有的。
那json数据到底在哪里?如果我们拿不到我们想要的数据,就无法完成数据抓取工作。
找到json数据步骤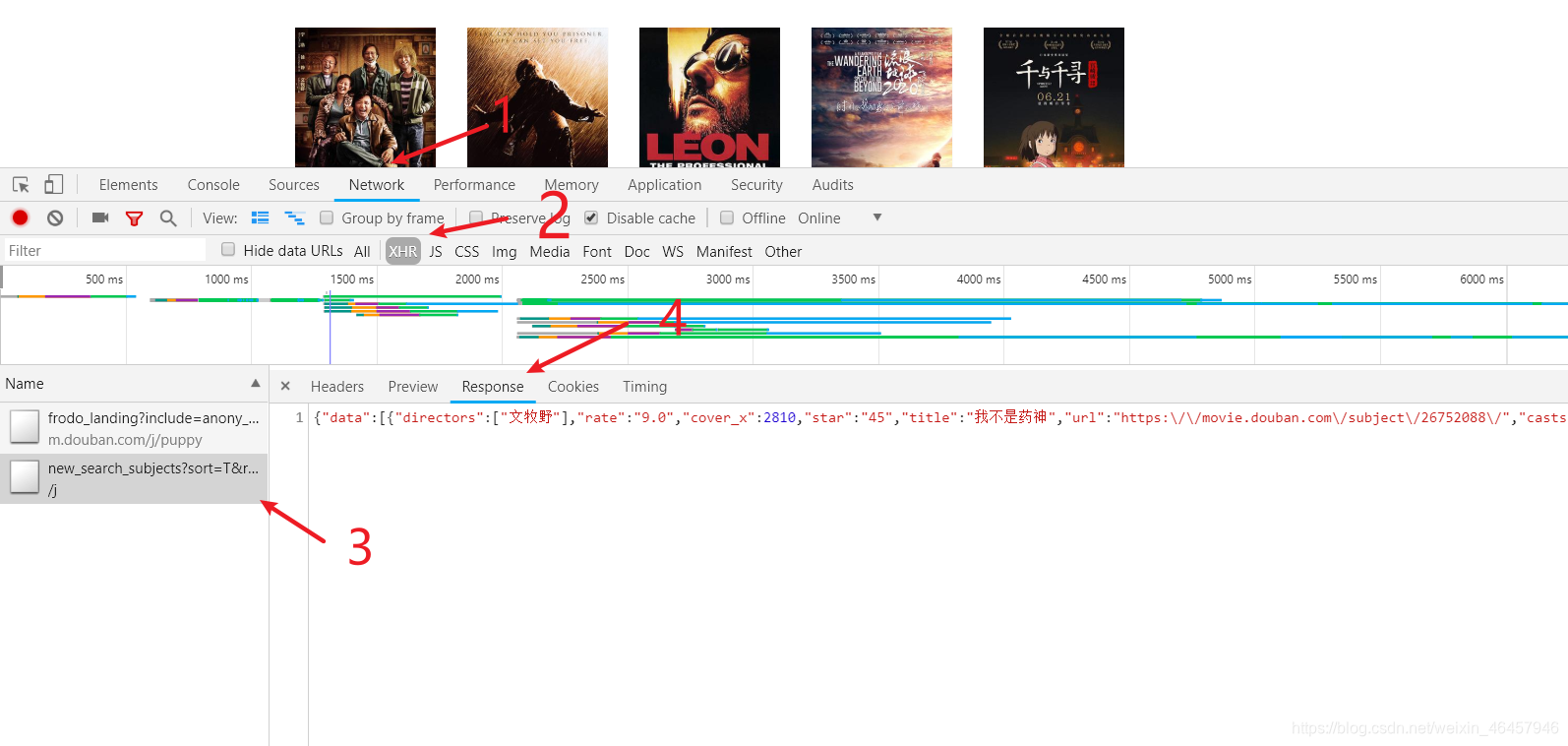
拿到json数据后我们拿到浏览器json解析工具看看数据的格式和特点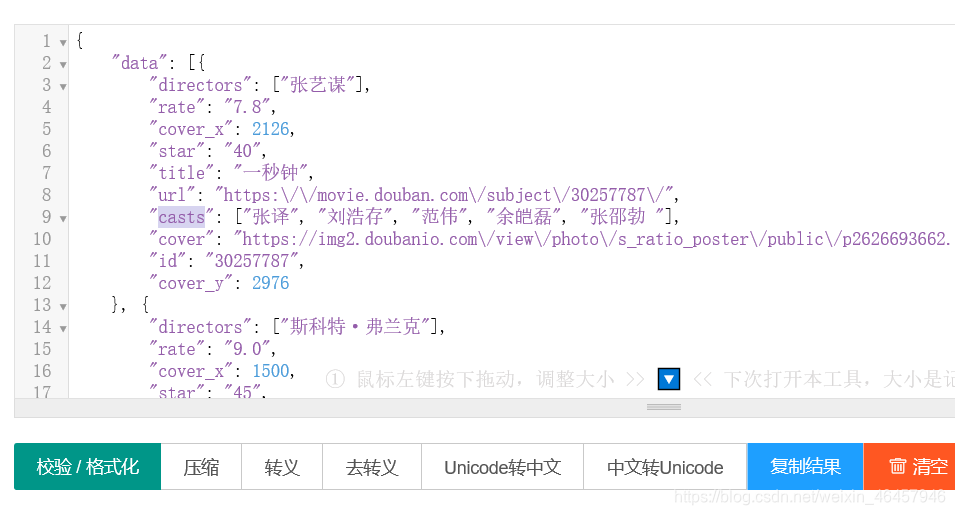 要爬取多个页面,就要分析链接地址的区别在哪里
要爬取多个页面,就要分析链接地址的区别在哪里 可以很清楚的看到这里的区别只有最后的start不一样,也就是说每一页在上一条的基础上都增加了20条数据。
可以很清楚的看到这里的区别只有最后的start不一样,也就是说每一页在上一条的基础上都增加了20条数据。
最后附上代码,每行代码都注释的很清楚了。只需要改UA参数和数据库参数就能直接运行。
import requests
import json
import pymysql
#数据解析
allMovelist=[]#保存所有影视信息
currenPage=1#默认页面等于1
def parse():
global currenPage#这个currenPage是局部变量
url="https://movie.douban.com/j/new_search_subjects?start=0"
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36"
}
conn = pymysql.connect(host="localhost", db="test", user="root", passwd="123456")
cur = conn.cursor()
for p in range(1,21):#遍历1,21页的数据,你还可以改的更多,我也不知道有多少页
url = "https://movie.douban.com/j/new_search_subjects?start=%d" % (p * 20)
# 拿到json数据
html_json = requests.get(url=url, headers=headers).text
# 转换为json文本
json_text = html_json
# 转换为字典
move_dict = json.loads(json_text)
# 判断数据是否为空,如果为空直接返回
if len(move_dict["data"]) == 0:
return
# 保存信息到字典
for one_move in move_dict["data"]:
print(one_move)
# 获取电影名称
title = one_move["title"]
# 获取导演
directors = one_move["directors"]
directors = ",".join(directors)#这一步是因为可能多个导演,将他们的名字用逗号隔开,下同
# 获取演员
casts = one_move["casts"]
casts = ",".join(casts)
# 获取评分
rate = (one_move["rate"])
# 一部电影信息
oneMovelist = [title, directors, casts, rate]
allMovelist.append(oneMovelist)#将每部电影信息添加到所有信息列表里,注意上边定义的空列表
sql = "insert into actor(title,directors,casts,rate)values ('" + title + "','" + directors + "','" + casts + "','" + str(rate) + "')"
cur.execute(sql)
conn.commit()#提交数据
conn.close()#关闭游标
# 主函数
if __name__ == '__main__':
parse()#调用函数
print(allMovelist)
新手博主,请前辈批评指正——丁一

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 2
2 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)