mybatis一对一,多对一,一对多--使用自动映射避免繁琐的resultMap
我们知道,相比较hibernate,mybatis的一对一,一对多都比较繁琐,hibernate可以直接在实体类里面配置好映射关系,获取值的时候就能把一对一和一对多的对象带出来了,而mybatis需要用到resultMap,需要在resultMap中把实体类与表字段的对应关系一一写出来,如果遇到关联表有相同字段名,还要写别名,画风往往是这样的:看着好像还行,但是要知道有些表可是有几十个字段的, 不
头疼的一对一,多对一,一对多写法
我们知道,相比较hibernate,mybatis的一对一,一对多都比较繁琐,hibernate可以直接在实体类里面配置好映射关系,获取值的时候就能把一对一和一对多的对象带出来了,而mybatis需要用到resultMap,需要在resultMap中把实体类与表字段的对应关系一一写出来,如果遇到关联表有相同字段名,还要写别名,画风往往是这样的:
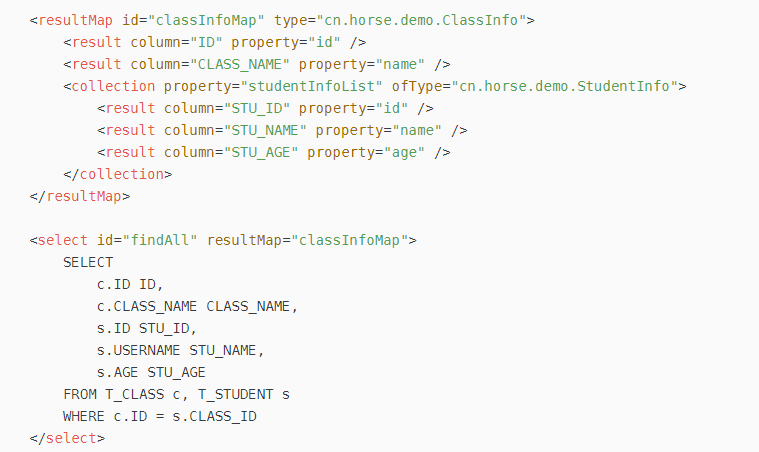
看着好像还行,但是要知道有些表可是有几十个字段的, 不仅要写resultMap,还要在sql中把所有列名写出来,这酸爽,看着就头疼,幸亏有个大杀器autoMapping,可以大大简化mapper.xml的代码量,下面来讲解下使用方法,让你对mybatis的一对一,一对多,多对一不再头疼.
autoMapping
有三个自动映射级别:
- NONE - 禁用自动映射。只会设置手动映射的属性。
- PARTIAL - 除了内部定义了嵌套结果映射的结果(联接)之外,其他都会自动映射。
- FULL - 自动映射所有内容。
默认是partial,也就是当你resultMap中包含 association,collection等嵌套结果时是不会自动映射的,但是可以在resultMap中配置autoMapping="true"手动开启,为啥默认配置是partical自然是有原因的,因为表关联的时候很可能会引入相同的字段,这时自动映射可能会出现错误的结果,不过这个问题是有办法规避的
试验用sql
我们定义两张表,department部门表和employee员工表,每个员工属于一个部门,员工与部门是多对一的关系,部门与员工是一对多的关系,一对一的写法其实和多对一一样,就不另外介绍了
CREATE TABLE `department` (
`id` int(0) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`remark` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '备注',
`create_time` date NULL DEFAULT NULL COMMENT '成立时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
CREATE TABLE `employee` (
`id` int(0) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`birthday` date NULL DEFAULT NULL,
`job` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`department_id` int(0) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;多对一
定义一个EmployeeDTO,里面有员工所属部门的对象,在员工数据中返回所属部门,就实现了多对一的效果
@Getter
@Setter
public class EmployeeDTO extends Employee {
private Department department;
}多对一有两种实现方式,一种是表连接然后直接映射,还有一种是先查主表,再查关联表
表连接方式
可以看到,下面的代码开启了自动映射,并且sql中没有写字段名,直接通过*来取所有字段,这样是最简洁的写法,后续就算department加字段我们也不需要改resultMap了,但是这种写法遇到同名的字段就会有问题
<mapper namespace="cn.hollycloud.server.mapper.EmployeeMapper">
<!-- 错误的示范 -->
<resultMap id="BaseResultMap" type="cn.hollycloud.server.dto.EmployeeDTO" autoMapping="true">
<id column="id" property="id" />
<association property="department" javaType="cn.hollycloud.server.entity.Department" autoMapping="true">
</association>
</resultMap>
<select id="listAll" resultMap="BaseResultMap">
select e.*,d.* from employee e
left join department d on e.department_id = d.id
</select>
</mapper>返回结果中可以看到,department中注入了员工的id和名字,这显然不是我们想要的结果,该如何解决呢?

我们需要把 子表中同名的字段命名为别名,并且在resultMap中做单独的映射,正确版本如下:
<mapper namespace="cn.hollycloud.server.mapper.EmployeeMapper">
<!-- 通用查询映射结果 -->
<resultMap id="BaseResultMap" type="cn.hollycloud.server.dto.EmployeeDTO" autoMapping="true">
<id column="id" property="id" />
<association property="department" javaType="cn.hollycloud.server.entity.Department" autoMapping="true">
<id column="d_id" property="id" />
<result column="d_name" property="name" />
</association>
</resultMap>
<select id="listAll" resultMap="BaseResultMap">
select e.*,d.id d_id,d.name d_name,d.* from employee e
left join department d on e.department_id = d.id
</select>
</mapper>可以看到,结果是正确的

关于重名的疑虑
看看上面的sql,select e.*,d.id d_id,d.name d_name,d.*,这个sql展开就是select e.id,e.name,d.id d_id,d.name d_name,d.id,d.name,其实返回的字段还是有重名的,如何能确定resultMap一定能找到正确的值呢?我们可以看看源码
DefaultResultSetHandler的getRowValue
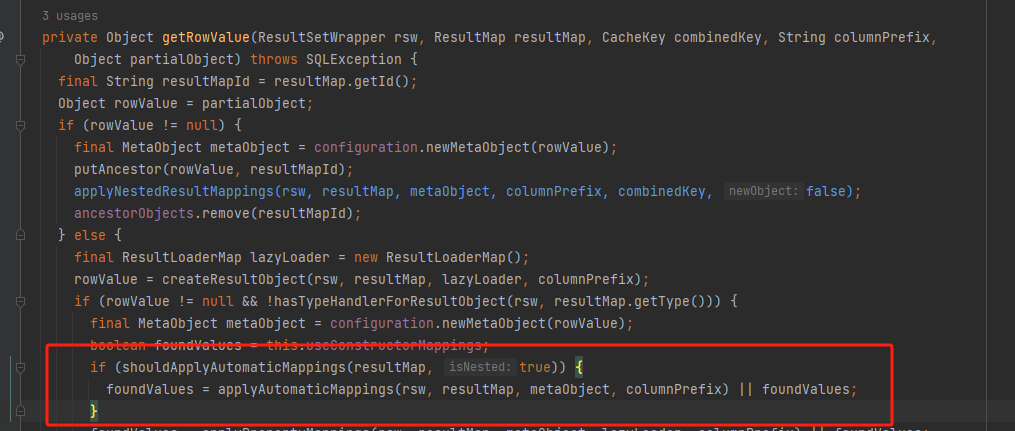
 一路跟进去我们发现最后其实就是调用的resultSet.getString(columnName),而这个方法优先返回第一个遇到的列的值,所以employee注入的是e.name而不是d.name,但是如果你写成select d.*,e.*也就是把d放前面就会注入部门的name,这点需要注意
一路跟进去我们发现最后其实就是调用的resultSet.getString(columnName),而这个方法优先返回第一个遇到的列的值,所以employee注入的是e.name而不是d.name,但是如果你写成select d.*,e.*也就是把d放前面就会注入部门的name,这点需要注意
子查询方式
子查询方式实现方式跟hibernate类似,先是查主表,下面例子中就是查员工表,再根据员工表中的department_id去查所属部门,优点是不用考虑重名问题,直接能够自动映射好,缺点是效率没表连接高,比如主表有10条数据,它先查出10条数据,再一个个根据id去查子表,要执行11条sql
association中column="{id = department_id}"的意思是把主表中department_id赋值给id,再把id作为参数传入getDepartmentById中
<mapper namespace="cn.hollycloud.server.mapper.EmployeeMapper">
<select id="listAll1" resultMap="BaseResultDto">
select * from employee
</select>
<select id="getDepartmentById" resultType="cn.hollycloud.server.entity.Department">
select * from department where id = #{id}
</select>
<!-- 通用查询映射结果 -->
<resultMap id="BaseResultDto" type="cn.hollycloud.server.dto.EmployeeDTO">
<id column="id" property="id" />
<association property="department" select="getDepartmentById" column="{id = department_id}"/>
</resultMap>
</mapper>一对多
一对多跟多对一其实差不多,只要association改成collection就行了,下面的例子中返回的部门数据中包含部门下所有员工,就是一对多了,一对多也有两种实现方式,表连接和子查询,表连接优点是效率高,缺点是需要考虑重名,不能分页,子查询优点是写法简洁,可以分页,缺点是效率不高
@Getter
@Setter
public class DepartmentDTO extends Department {
private List<Employee> employees;
}表连接方式
<mapper namespace="cn.hollycloud.server.mapper.DepartmentMapper">
<resultMap id="BaseResultMap" type="cn.hollycloud.server.dto.DepartmentDTO" autoMapping="true">
<id column="id" property="id" />
<collection property="employees" ofType="cn.hollycloud.server.entity.Employee" autoMapping="true">
<id column="e_id" property="id" />
<result column="e_name" property="name" />
</collection>
</resultMap>
<select id="listAll" resultMap="BaseResultMap">
select d.*, e.id e_id, e.name e_name, e.* from department d left join employee e on e.department_id = d.id
</select>
</mapper>子查询方式
<mapper namespace="cn.hollycloud.server.mapper.DepartmentMapper">
<resultMap id="BaseResultDTO" type="cn.hollycloud.server.dto.DepartmentDTO">
<id column="id" property="id" />
<collection property="employees" ofType="cn.hollycloud.server.entity.Employee"
select="listByDepartmentId" column="{id = id}"/>
</resultMap>
<select id="listByDepartmentId" resultType="cn.hollycloud.server.entity.Employee">
select * from employee where department_id = #{id}
</select>
<select id="listAll1" resultMap="BaseResultDTO">
select * from department
</select>
</mapper>
魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)