必看!大模型训练圣经《从头训练大模型》免费PDF分享
Current Best Practices for Training LLMs from Scratch》是由Weights & Biases(W&B)提供的一份关于从头开始训练大型语言模型(LLMs)的权威指南。这份白皮书深入剖析了LLMs训练的最佳实践,内容覆盖了从数据收集与处理、模型架构选择、训练技巧与优化策略,到模型评估与部署等各个环节。这份指南适合对自然语言处理和机器学习感兴趣的读者,
·

本书介绍
《Current Best Practices for Training LLMs from Scratch》是由Weights & Biases(W&B)提供的一份关于从头开始训练大型语言模型(LLMs)的权威指南。这份白皮书深入剖析了LLMs训练的最佳实践,内容覆盖了从数据收集与处理、模型架构选择、训练技巧与优化策略,到模型评估与部署等各个环节。
**本书免费获取地址:**
**关注下方公众号“大模型科技说”回复关键字“**db24**”获取下载地址。**
核心内容:
1. 是否从头开始训练LLM:指南首先讨论了是否应该自己从头开始训练一个LLM,还是使用现有的商业API或开源LLM。
2. 训练LLM的三种基本方法:
使用商业LLM的API,例如GPT-3。
使用现有的开源LLM,例如GPT-J。
自己预训练LLM,可以是自己管理训练或雇佣LLM顾问和平台。
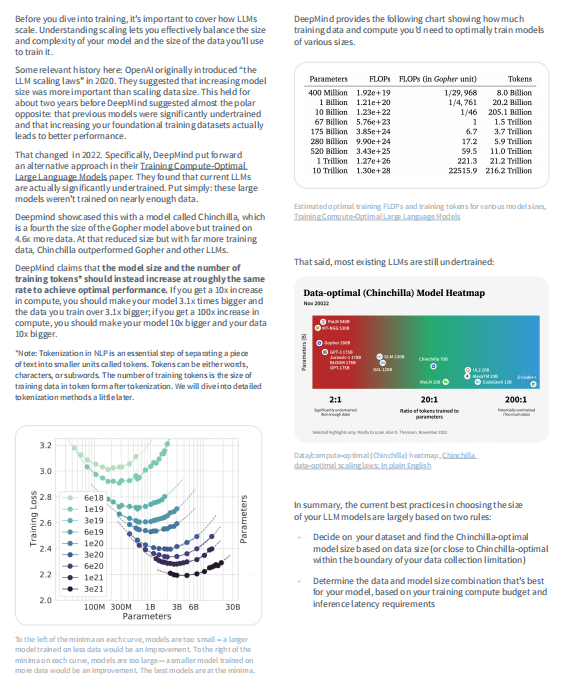
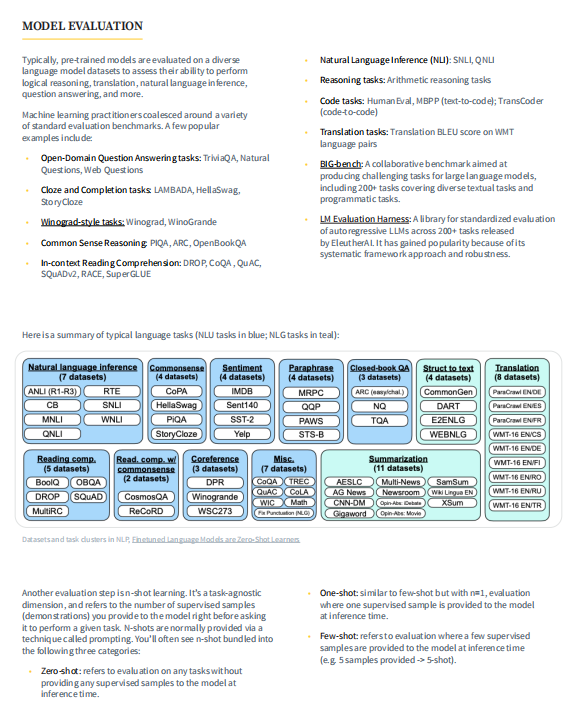
3. 模型和数据集的扩展性:介绍了LLMs的扩展性,包括模型大小和训练数据量的平衡,以及如何根据训练计算预算和推理延迟要求确定模型和数据大小的最佳组合。
4. 并行训练技术:讨论了在训练过程中可能使用的并行技术,如张量并行、数据并行和流水线并行。
5. 训练中的挑战和策略:包括硬件故障、训练不稳定性等问题,以及如何应对这些问题的策略,例如批大小、学习率调度、权重初始化等。
6. 基于人类反馈的强化学习(RLHF):介绍了如何通过人类反馈来优化模型性能,特别是在模型表现出不期望的行为时。
这份指南适合对自然语言处理和机器学习感兴趣的读者,尤其是那些想要了解LLMs训练最新进展的研究者和实践者。
内容截图




本书免费下载地址
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 2
2 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)