ajax爬取微博,自动滚屏抓取新浪微博
微博是一种新媒体和通信工具,上面有大量,首先需要将微博的内容抓取下来。单从微博的网页结构来说,上面的数据具有很规整的语义结构和元数据,所以,对于这种旨在结构化网页数据的抓取工具来说,抓取微博的内容很容易。但是,从微博网站采用的编程技术来说,抓取微博又有很多障碍,最大的障碍是基于Javascript/JS的AJAX程序框架,导致网络爬虫很难在微博网站上爬行和抓取数据。但是,MetaSeeker具有很
微博是一种新媒体和通信工具,上面有大量,首先需要将微博的内容抓取下来。单从微博的网页结构来说,上面的数据具有很规整的语义结构和元数据,所以,对于这
种旨在结构化网页数据的抓取工具来说,抓取微博的内容很容易。但是,从微博网站采用的编程技术来说,抓取微博又有很多障碍,最大的障碍是基于
Javascript/JS的AJAX程序框架,导致网络爬虫很难在微博网站上爬行和抓取数据。但是,MetaSeeker具有很强的AJAX内容抓取能
力,我们在《抓取AJAX网站》一文已经有所体验。本文将以抓取新浪微博为例,讲解MetaSeeker的一些重要特性。本文讲解的方法同样适用于抓取腾讯微博。
假设有下面的抓取目标:
目的:抓取新浪微博,重复抓取,持续监控,进行Web数据挖掘,用于建设。
主题名:demo_sina_weibo
抓取目标
从微博列表中抓取下面的内容
内容
发布时间
转发数
点评数
翻页抓取:如果定时重复监测第一页是否出现新内容,翻页抓取是没有意义的,但是,我们在本文还是定义了翻页抓取规则,仅为演示。
注释1:登录前和登录后看到的内容数量有差别,定义上述网站抓取信息结构(用于自动生成抓取规则)时,事先登录了新浪微博,所以读者如果要用MetaStudio加载体验该信息结构,请事先通过火狐浏览器完成登录,否则可能加载失败,详细说明参见下节。
注释2:抓取AJAX网站的信息结构的加载方法有点不同,请参考《分页抓取卓越网的商品》
注释3:本文不是入门教程,如果对MetaSeeker的基本操作方法不熟悉,请按顺序阅读《MetaSeeker速成手册》
1 登录新浪微博
如果不登录新浪微博,访问上述样本网页看到的微博信息条数要少很多,所以,在运行之前先用Firefox访问新浪微博,完成登录。由于登录状态记录在cookie中,即便火狐浏览器退出了,在一定时间内登录状态还是有效的,在此期间运行MetaSeeker不用再次登录。
2 抓取新浪微博的规则
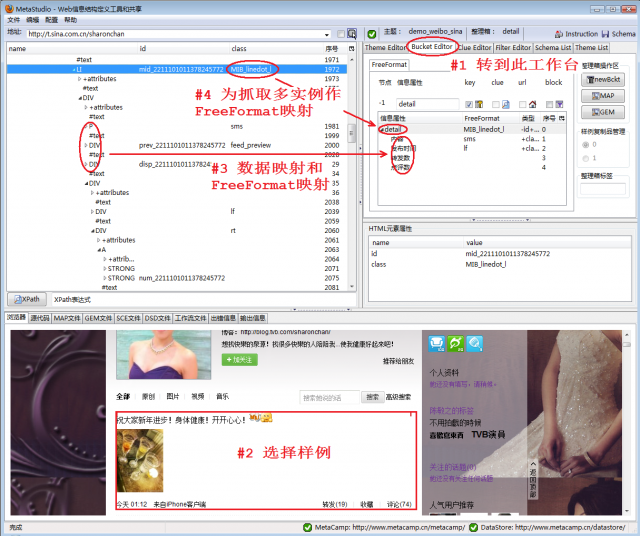
图1显示了如下步骤:
在内嵌浏览器上选择样例,如果打开了反向选择开关,则MetaStudio能够在DOM树视窗中自动定位对应的DOM节点,参见《抓取当当百货价格》
为各信息属性作数据映射和FreeFormat映射,以便MetaStudio自动生成抓取规则,参见《抓取当当百货价格》
为了抓取多条微博消息,即抓取多实例,进行FreeFormat映射,而且选择@class='MIB_linedot_l'作为
FreeFormat标志。因为在网页上,多个HTML
DOM节点具有这个class值,所以,可以用来抓取多实例。相反,因为@id一般在一个网页上是唯一的,所以,不能选择这个DOM节点的@id作为
FreeFormat标志。详细描述参见《抓取京东商城商品价格》。如果不用FreeFormat映射,也可以使用样例复制品方法抓取多实例,参见《抓取当当百货价格》
3 设置AJAX抓取模式
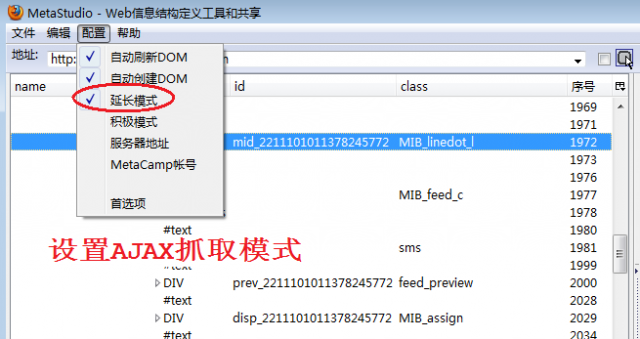
如图2所示,我们只选择了延长模式,而不像《分页抓取卓越网的商品》那样同时设置两个AJAX网页抓取模式,因为试验发现,转发数和点评数是在网页加载完成后才使用Javascript/JS程序从服务器异步加载的,所以,一定要设置延长模式。
4 定义分页抓取规则
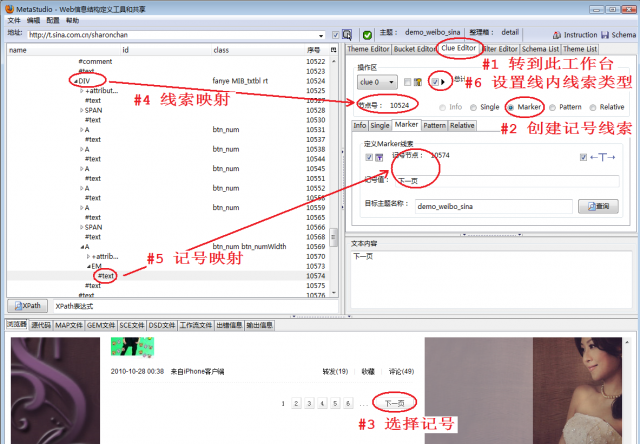
为了翻页抓取所有网页,需要定义线索抓取规则,而且应该设置成线内线索类型,详细操作步骤参见《批量抓取当当网价格数据》,本文只简单介绍一下步骤(如图3):
转到Clue Editor工作台
创建记号线索
选择记号“下一页”
进行线索映射
进行记号映射
设置成线内线索
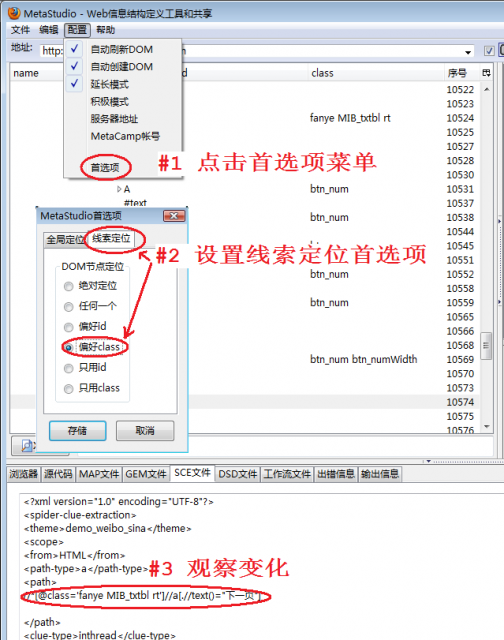
图4显示了怎样设置线索定位的首选项,这一步不是必须的,但是这样做可以提高抓取规则的适应度,也就是说即使目标网页结构修改了抓取规则受到的影响尽量小。原理说明参见,另一个应用案例参见
点击菜单“配置”-〉“首选项”
在弹出对话框中选择线索定位标签(tab),从“偏好id”改成“偏好class”
观察MetaStudio自动生成的抓取规则文件,可以看到变化,定位记号“下一页”时就近采用@class='fanye MIB_txtbl rt'作为FreeFormat标志,这样可以提高抓取规则的适应性。
至此,信息结构定义完了,可以将它和自动生成的抓取规则一起上载到MetaSeeker服务器上,以便DataScraper随时随地使用这个抓取规则。很明显,信息结构定义过程与《分页抓取卓越网的商品》没有什么本质区别,但是,下面的章节我们可以看到需要更多高级技巧才能完整抓取新浪微博的内容。
5 自动滚屏抓取
用Firefox火狐浏览器阅读该样本网页上的微博消息时,如果网络速度不很快,会有一种特殊体验:微博消息很多,这个网页很长,需要拖动右侧的卷
滚条滚屏才能看全所有消息,当网速比较慢时,滚屏时先看到文字,然后是图片,然后是转发数和点评数。后者是异步加载的,没有滚动到可见范围就不从服务器上
下载这些内容。如果我们采用通常的抓取方法,势必只能抓取到前面几条消息的点评数和转发数,因此,必须要求DataScraper在抓取的时候自动滚屏。
这种情形不仅发生在微博网站上,有些网站的网页上有大量图片,为了提高网页下载速度,一般也是在滚屏时才下载图片,例如网站就是这样。
6 设置滚屏参数
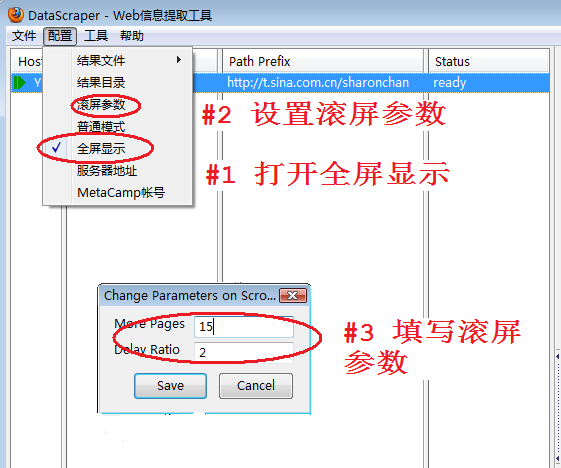
图5显示了设置滚屏参数的步骤:
打开全屏显示,DataScraper重新运行时或者启动多线程周期性抓取窗口时,DataScraper将占满整个屏幕,增大浏览器的可视范围,每屏显示的内容最多,以减少翻屏次数
选择滚屏参数菜单
在弹出对话框中输入滚屏参数。More Pages参数一定不能为0,否则就不会自动滚屏,具体滚多少,需要试验验证,详细说明参见《如何自动滚屏抓取AJAX网站数据》
如果采用周期性自动抓取模式,请参考修改crontab.xml文件的相关参数。
注释:本例将More Pages设置成15,当网络速度很慢的时候,也许30更合适,这样预留更多时间等待所有点评数和转发数加载上。
7 提高新浪微博的抓取速度
新浪微博上的照片尺寸很大,而且数量很多,下载时间很长,做Web数据挖掘系统时,图片一般不需要,如果能够阻止下载图片,将大大加快速度,如果您使用企业版,请参考。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)