mybatis plus 看这篇就够了,一发入魂
mybatis-plus是一款Mybatis增强工具,用于简化开发,提高效率。下文使用缩写mp来简化表示mybatis-plus,本文主要介绍mp搭配SpringBoot的使用。注:本文使用的mp版本是当前最新的3.4.2,早期版本的差异请自行查阅文档官方网站:baomidou.com/快速入门创建一个SpringBoot项目导入依赖<!-- pom.xml --><?xml v
mybatis-plus是一款Mybatis增强工具,用于简化开发,提高效率。下文使用缩写mp来简化表示mybatis-plus,本文主要介绍mp搭配SpringBoot的使用。
注:本文使用的mp版本是当前最新的3.4.2,早期版本的差异请自行查阅文档
官方网站:baomidou.com/
快速入门
-
创建一个SpringBoot项目
-
导入依赖
<!-- pom.xml --> <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.3.4.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.example</groupId> <artifactId>mybatis-plus</artifactId> <version>0.0.1-SNAPSHOT</version> <name>mybatis-plus</name> <properties> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-configuration-processor</artifactId> </dependency> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.4.2</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> </project> -
配置数据库
# application.yml spring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/yogurt?serverTimezone=Asia/Shanghai username: root password: root mybatis-plus: configuration: log-impl: org.apache.ibatis.logging.stdout.StdOutImpl #开启SQL语句打印 -
创建一个实体类
package com.example.mp.po; import lombok.Data; import java.time.LocalDateTime; @Data public class User { private Long id; private String name; private Integer age; private String email; private Long managerId; private LocalDateTime createTime; } -
创建一个mapper接口
package com.example.mp.mappers; import com.baomidou.mybatisplus.core.mapper.BaseMapper; import com.example.mp.po.User; public interface UserMapper extends BaseMapper<User> { } -
在SpringBoot启动类上配置mapper接口的扫描路径
package com.example.mp; import org.mybatis.spring.annotation.MapperScan; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication @MapperScan("com.example.mp.mappers") public class MybatisPlusApplication { public static void main(String[] args) { SpringApplication.run(MybatisPlusApplication.class, args); } } -
在数据库中创建表
DROP TABLE IF EXISTS user; CREATE TABLE user ( id BIGINT(20) PRIMARY KEY NOT NULL COMMENT '主键', name VARCHAR(30) DEFAULT NULL COMMENT '姓名', age INT(11) DEFAULT NULL COMMENT '年龄', email VARCHAR(50) DEFAULT NULL COMMENT '邮箱', manager_id BIGINT(20) DEFAULT NULL COMMENT '直属上级id', create_time DATETIME DEFAULT NULL COMMENT '创建时间', CONSTRAINT manager_fk FOREIGN KEY(manager_id) REFERENCES user (id) ) ENGINE=INNODB CHARSET=UTF8; INSERT INTO user (id, name, age ,email, manager_id, create_time) VALUES (1, '大BOSS', 40, 'boss@baomidou.com', NULL, '2021-03-22 09:48:00'), (2, '李经理', 40, 'boss@baomidou.com', 1, '2021-01-22 09:48:00'), (3, '黄主管', 40, 'boss@baomidou.com', 2, '2021-01-22 09:48:00'), (4, '吴组长', 40, 'boss@baomidou.com', 2, '2021-02-22 09:48:00'), (5, '小菜', 40, 'boss@baomidou.com', 2, '2021-02-22 09:48:00')
注解
mp一共提供了8个注解,这些注解是用在Java的实体类上面的。
-
@TableName注解在类上,指定类和数据库表的映射关系。实体类的类名(转成小写后)和数据库表名相同时,可以不指定该注解。
-
@TableId注解在实体类的某一字段上,表示这个字段对应数据库表的主键。当主键名为id时(表中列名为id,实体类中字段名为id),无需使用该注解显式指定主键,mp会自动关联。若类的字段名和表的列名不一致,可用
value属性指定表的列名。另,这个注解有个重要的属性type,用于指定主键策略,参见主键策略小节 -
@TableField注解在某一字段上,指定Java实体类的字段和数据库表的列的映射关系。这个注解有如下几个应用场景。
-
排除非表字段
若Java实体类中某个字段,不对应表中的任何列,它只是用于保存一些额外的,或组装后的数据,则可以设置
exist属性为false,这样在对实体对象进行插入时,会忽略这个字段。排除非表字段也可以通过其他方式完成,如使用static或transient关键字,但个人觉得不是很合理,不做赘述 -
字段验证策略
通过
insertStrategy,updateStrategy,whereStrategy属性进行配置,可以控制在实体对象进行插入,更新,或作为WHERE条件时,对象中的字段要如何组装到SQL语句中。参见配置小节 -
字段填充策略
通过
fill属性指定,字段为空时会进行自动填充
-
-
@Version乐观锁注解,参见乐观锁小节
-
@EnumValue注解在枚举字段上
-
@TableLogic逻辑删除,参见逻辑删除小节
-
KeySequence序列主键策略(
oracle) -
InterceptorIgnore插件过滤规则
CRUD接口
mp封装了一些最基础的CRUD方法,只需要直接继承mp提供的接口,无需编写任何SQL,即可食用。mp提供了两套接口,分别是Mapper CRUD接口和Service CRUD接口。并且mp还提供了条件构造器Wrapper,可以方便地组装SQL语句中的WHERE条件,参见条件构造器小节
Mapper CRUD接口
只需定义好实体类,然后创建一个接口,继承mp提供的BaseMapper,即可食用。mp会在mybatis启动时,自动解析实体类和表的映射关系,并注入带有通用CRUD方法的mapper。BaseMapper里提供的方法,部分列举如下:
insert(T entity)插入一条记录deleteById(Serializable id)根据主键id删除一条记录delete(Wrapper<T> wrapper)根据条件构造器wrapper进行删除selectById(Serializable id)根据主键id进行查找selectBatchIds(Collection idList)根据主键id进行批量查找selectByMap(Map<String,Object> map)根据map中指定的列名和列值进行等值匹配查找selectMaps(Wrapper<T> wrapper)根据 wrapper 条件,查询记录,将查询结果封装为一个Map,Map的key为结果的列,value为值selectList(Wrapper<T> wrapper)根据条件构造器wrapper进行查询update(T entity, Wrapper<T> wrapper)根据条件构造器wrapper进行更新updateById(T entity)- ...
简单的食用示例如前文快速入门小节,下面讲解几个比较特别的方法
selectMaps
BaseMapper接口还提供了一个selectMaps方法,这个方法会将查询结果封装为一个Map,Map的key为结果的列,value为值
该方法的使用场景如下:
-
只查部分列
当某个表的列特别多,而SELECT的时候只需要选取个别列,查询出的结果也没必要封装成Java实体类对象时(只查部分列时,封装成实体后,实体对象中的很多属性会是null),则可以用
selectMaps,获取到指定的列后,再自行进行处理即可比如
@Test public void test3() { QueryWrapper<User> wrapper = new QueryWrapper<>(); wrapper.select("id","name","email").likeRight("name","黄"); List<Map<String, Object>> maps = userMapper.selectMaps(wrapper); maps.forEach(System.out::println); }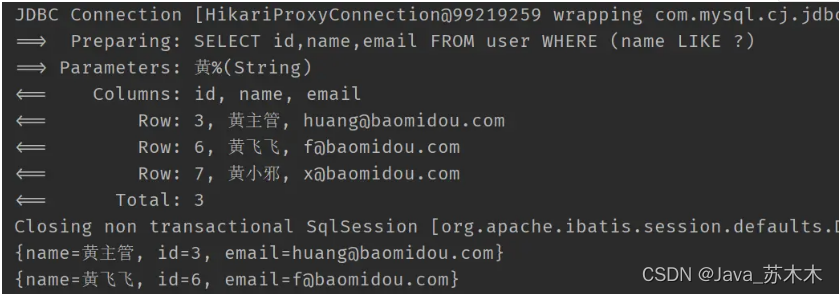
- 进行数据统计
比如
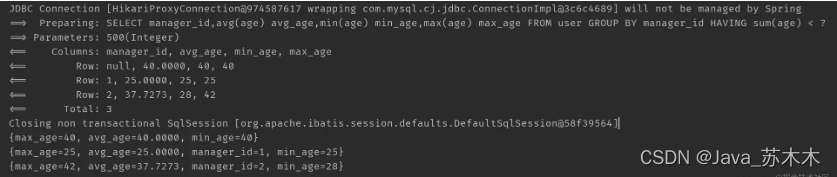
// 按照直属上级进行分组,查询每组的平均年龄,最大年龄,最小年龄
/**
select avg(age) avg_age ,min(age) min_age, max(age) max_age from user group by manager_id having sum(age) < 500;
**/
@Test
public void test3() {
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.select("manager_id", "avg(age) avg_age", "min(age) min_age", "max(age) max_age")
.groupBy("manager_id").having("sum(age) < {0}", 500);
List<Map<String, Object>> maps = userMapper.selectMaps(wrapper);
maps.forEach(System.out::println);
}
selectObjs
只会返回第一个字段(第一列)的值,其他字段会被舍弃
比如
@Test
public void test3() {
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.select("id", "name").like("name", "黄");
List<Object> objects = userMapper.selectObjs(wrapper);
objects.forEach(System.out::println);
}
得到的结果,只封装了第一列的id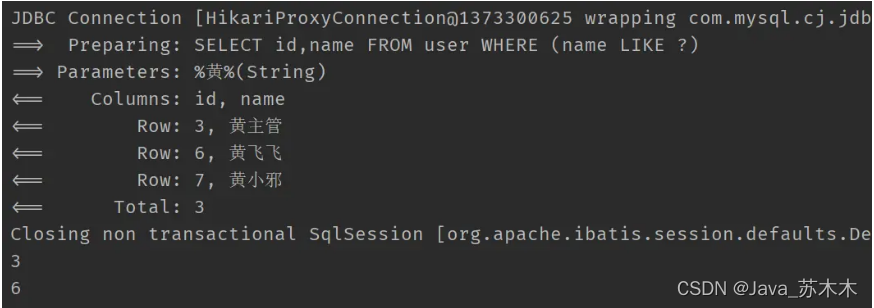
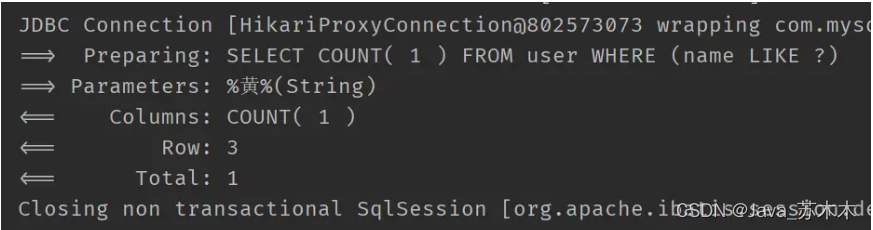
selectCount
查询满足条件的总数,注意,使用这个方法,不能调用QueryWrapper的select方法设置要查询的列了。这个方法会自动添加select count(1)
比如
@Test
public void test3() {
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.like("name", "黄");
Integer count = userMapper.selectCount(wrapper);
System.out.println(count);
}
总结
-
条件构造器
AbstractWrapper中提供了多个方法用于构造SQL语句中的WHERE条件,而其子类QueryWrapper额外提供了select方法,可以只选取特定的列,子类UpdateWrapper额外提供了set方法,用于设置SQL中的SET语句。除了普通的Wrapper,还有基于lambda表达式的Wrapper,如LambdaQueryWrapper,LambdaUpdateWrapper,它们在构造WHERE条件时,直接以方法引用来指定WHERE条件中的列,比普通Wrapper通过字符串来指定要更加优雅。另,还有链式Wrapper,如LambdaQueryChainWrapper,它封装了BaseMapper,可以更方便地获取结果。 -
条件构造器采用链式调用来拼接多个条件,条件之间默认以
AND连接 -
当
AND或OR后面的条件需要被括号包裹时,将括号中的条件以lambda表达式形式,作为参数传入and()或or()特别的,当
()需要放在WHERE语句的最开头时,可以使用nested()方法 -
条件表达式时当需要传入自定义的SQL语句,或者需要调用数据库函数时,可用
apply()方法进行SQL拼接 -
条件构造器中的各个方法可以通过一个
boolean类型的变量condition,来根据需要灵活拼接WHERE条件(仅当condition为true时会拼接SQL语句) -
使用lambda条件构造器,可以通过lambda表达式,直接使用实体类中的属性进行条件构造,比普通的条件构造器更加优雅
-
若mp提供的方法不够用,可以通过自定义SQL(原生mybatis)的形式进行扩展开发
-
使用mp进行分页查询时,需要创建一个分页拦截器(Interceptor),注册到Spring容器中,随后查询时,通过传入一个分页对象(Page对象)进行查询即可。单表查询时,可以使用
BaseMapper提供的selectPage或selectMapsPage方法。复杂场景下(如多表联查),使用自定义SQL。 -
AR模式可以直接通过操作实体类来操作数据库。让实体类继承自
Model即可

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)