2021-08-28-CR-004 Python爬虫 用requests和lxml 解析网页,获取精美图片的链接
这个可以看做是前面两节002和003 的另外一种获取和解析数据的方法import requestsre=requests.get('https://pic.netbian.com/4kdongwu/').textfrom lxml import etreehtml = etree.HTML(re)result = etree.tostring(html)li=html.xpath('//div[@
这个可以看做是前面两节002和003 的另外一种获取和解析数据的方法
import requests
re=requests.get('https://pic.netbian.com/4kdongwu/').text
from lxml import etree
html = etree.HTML(re)
result = etree.tostring(html)
li=html.xpath('//div[@class="slist"]//li')
addrlist=[]
for i in li:
addrlist.append(i.xpath('./a/@href')[0])
第一步获取图片
使用requests库获取这个页面
第二步用lxml解析
html = etree.HTML(re)
因为HTML函数参数要求是string,所以这里的解析前的数据要使用.text属性
第三步去网页找这个数据
取得li元素的列表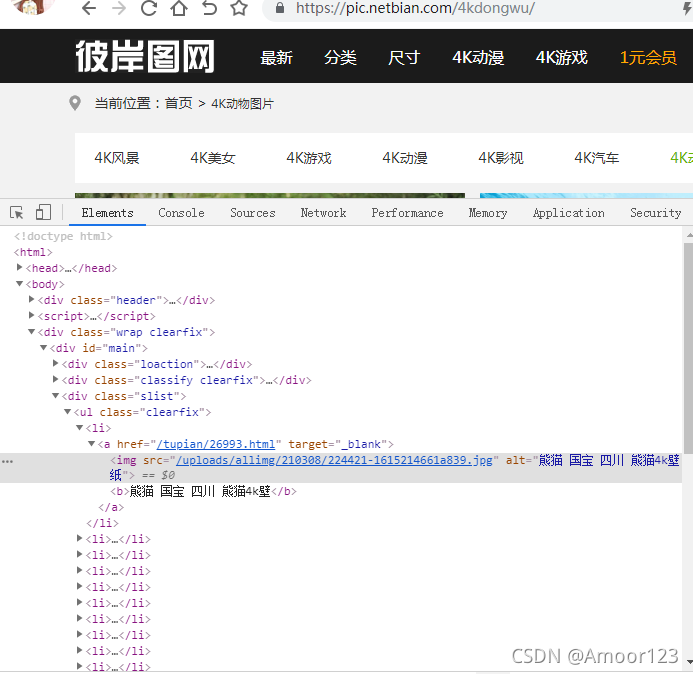
li=html.xpath(’//div[@class=“slist”]//li’)
我们是自己写的,//表示所有节点的
div[@class=“slist”]表示选取 class属性为slist的div
//表示的所有节点中的
li表示所有的li节点
连起来解释为
所有节点中 找到class为slist的div下面的所有li节点
这个也可以在浏览器里面找到第一个 节点并又见复制xpath
google浏览器的方法就是对着第一个 要提取的< li> —右键copy选xpath
复制出来是这样的
//*[@id=“main”]/div[3]/ul/li[1]
去掉末尾的序号-----[1]
然后运行,同样得到了这个属性,这里也是取得li这个元素的列表
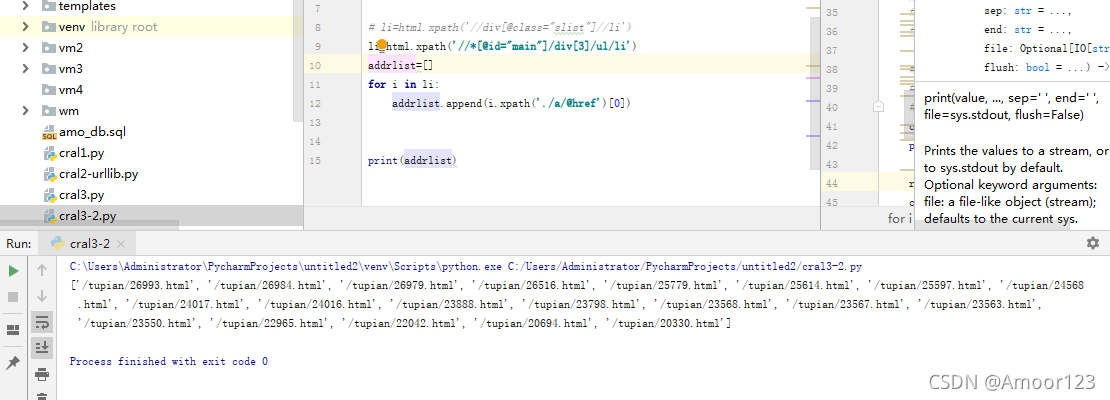
然后遍历这个取得的li元素列表里的元素
i.xpath(’./a/@href’)[0]
选取当前节点下的a元素的属性href
因为取得的是列表,所以取第【0】个数据
这里浏览器的copy效果不好,也要自己加href属性
这样就可以取得 前面的资源列表了

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)