爬虫基础知识之requests和lxml
今天学爬虫主要学了两个了模块:requests和lxml。下面来运行一些命令进行安装这两个模块。
·
模块准备
今天学爬虫主要学了两个了模块:requests和lxml。下面来运行一些命令进行安装这两个模块
# 安装requests模块
pip install requests
# 安装lxml模块
pip install lxml
requests模块
不用了解太细,只需要知道传入什么参数进去就OK。下面是一个演示:
# 下面是第一个参数url1
url1 = 'https://www.bookschina.com/'
# 下面是第二个参数headers1
headers1 = {
'cookie':'.............' # 可以省略不写
'host':'...............' # 可以省略不写
'referer':'............' # 可以省略不写
'user-agent':'填自己浏览器的信息' # 这一个一定要写
}
# 分别把两个参数传进去
result = requests.get(url = url1, headers = headers1) # 向要爬取的网页发起请求
# 如果下面的打印结果乱码,记得写下面这一行的代码
result.encoding = result.apparent_encoding
content = result.text # 爬取的网页的内容
print(content) # 打印内容,类型是字符串
注意:如果只填了user-agent却爬不出来内容,就把其他的都填了
下面是一个简单示例:
import requests
url = 'https://www.bookschina.com/'
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0'
}
result = requests.get(url=url,headers=headers)
# 一开始我并没有写下面这一行代码,所以结果出现了乱码
result.encoding = result.apparent_encoding
content = result.text
print(content) # 内容是一个html,但是类型仍然是字符串
lxml模块
lxml模块就是用来解析网页的。通过它的etree工具
导包示例:
from lxml import etree
网页基本知识
-
html标签
作为开始和结束的标记,由尖括号包围的关键词,比如 ,标签对中的第一个标签是开始标签,第二个标签是结束标签。html中常见标签如下:
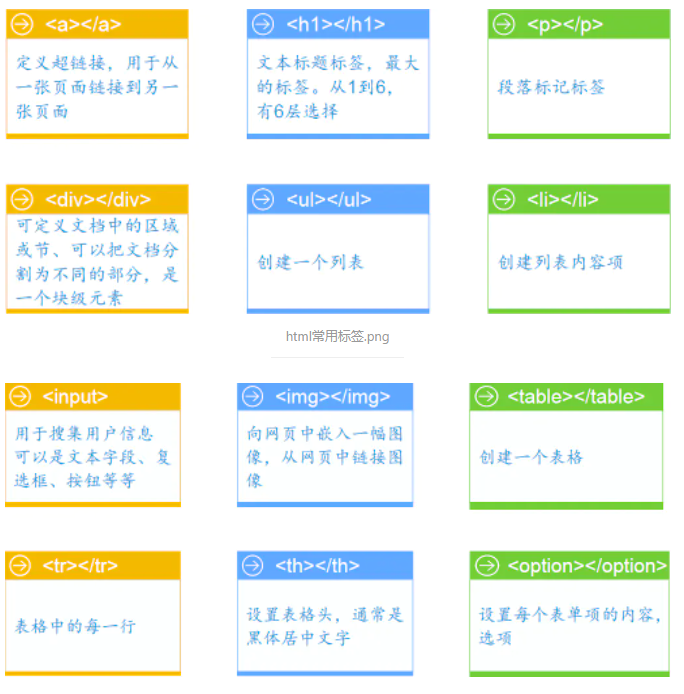
-
html属性
属性是用来修饰标签的,放在开始标签里里面,html中常见四大属性:
| 属性 | 说明 |
|---|---|
| class | 规定元素的类名,大多数时候用于指定样式表中的类 |
| id | 唯一标识一个元素的属性,在html里面必须是唯一的 |
| href | 指定超链接目标的url |
| src | 指定图像的url |
xpath
| 符号 | 功能 |
|---|---|
| // | 表示在整个文本中查找,是一种相对路径 |
| / | 表示则表示从根节点开始查找,是一种绝对路径 |
| text() | 找出文本值 |
| @ | 找出标签对应的属性值,比如@href就是找出对应的href链接 |
| . | 表示当前节点 |
| … | 表示当前节点的父节点 |
代码示例:
from lxml import etree
html1 = """
<!DOCTYPE html>
<html>
<head lang='en'>
<meta charest='utf-8'>
<title></title>
</head>
<body>
<div id="test-1">需要的内容1</div>
<div id="test-2">需要的内容2</div>
<div id="test-3">需要的内容3</div>
</body>
</html>
"""
# 首先这是字符串,需要转成html形式才能进行解析
# 把字符串转成html类型
content = etree.HTML(html1)
# 解析网页,取到我们要爬取的内容1
# 查找指定属性的标签,需要用表明 @属性="值",格式:标签[@属性="值"]
res1 = content.xpath('//div[@id="test-1"]')
print(res1) # [<Element div at 0x1b6634fb248>],这只是一个列表,里面其实是一个标签
# 在末尾加一个 /text() 就能拿到标签里面的值,但是仍然是一个列表
res2 = content.xpath('//div[@id="test-1"]/text()')
print(res2) # ['需要的内容1']
res3 = content.xpath('//div[@id="test-1"]/text()')[0]
# 这样虽然拿到了其中的元素,但是并不是字符串,不利于后面的操作,因为我们需要把它转成字符串
print(res3,type(res3)) # 需要的内容1 <class 'lxml.etree._ElementUnicodeResult'>
res4 = str(content.xpath('//div[@id="test-1"]/text()')[0])
print(res4,type(res4)) # 需要的内容1 <class 'str'>
注意:查找的标签一定是唯一的,而id属性全局唯一,classs属性未必是全局唯一的
爬虫案例【今天刚做的】
爬取中图网畅销榜TOP1000,并存入文件
# 导入必要的库
import requests
import pandas as pd
from lxml import etree
from datetime import datetime
# headers参数,是固定的
headers = {
#'cookie':'indexCache=yes; ASP.NET_SessionId=k5p0hlk2vraym1e011vugrx0; Hm_lvt_6993f0ad5f90f4e1a0e6b2d471ca113a=1733368611; HMACCOUNT=40935BD88D5084BE; BookUser=1%7ced48e890-6613-47a1-8156-bffb64892beb%7c1%7c0%7c638715862242118910%7c20180722%7cd4088da2803a400e; UserSign=069f073dff21b10b; booklisthistory=8419819; UserUnionId=f42e84c8-61b1-41de-b9a0-d05e8facf13d; Hm_lpvt_6993f0ad5f90f4e1a0e6b2d471ca113a=1733368651',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0'
}
# 书名列表,用来存入每一本书的名字
book_name_list = []
# 作者列表,用来存入每一本书的作者
book_author_list = []
# 出版社列表,用来存入每一本书的出版社
book_publisher_list = []
# 售价列表,用来存入每一本书的当前售价
sellPrice_list = []
# 折扣列表,用来存入每一本书的折扣
discount_list = []
# 定价列表,用来存入每一本书的定价
Pricing_list = []
# 优惠列表,用来存入每一本书的额外优惠信息
activeIcon_list = []
# 评论列表,用来存入每一本书的评论数
book_content_list = []
# 评分星级列表,用来存入每一本书的星级
star_grade_list = []
# 先定下来一个变量,用来接收后面的时间
date = 0
# 所有内容一共34页
for page in range(1,35):
print(f"正在获取中图网第{page}页的信息".center(50,'-'))
# 每一页的url,随着而页数的改变而改变
url = f'https://www.bookschina.com/24hour/1_0_{page}/'
# 向当前页发起请求
ztw_content = requests.get(url,headers)
# 以防内容是乱码的
ztw_content.encoding = ztw_content.apparent_encoding
# 获取当前时间,并进行格式化处理,传给前面设定好的date
date = datetime.strftime(datetime.now(),'%Y-%m-%d')
# 获取当前的内容,也就是HTML代码,只不过是字符串的类型
ztw_html_str = ztw_content.text
# 对获取的内容进行转换,转换成html形式
ztw_html = etree.HTML(ztw_html_str)
# 解析网页,每一本书都在 li 里面,所以,获取所有的 li 成一个列表
li_list = ztw_html.xpath('//div[@class="bookList"]/ul/li')
# 遍历这个列表
for li in li_list:
# 书名
# div[2],表示当前目录下第二个div标签,然后获取其内容并转换成字符串类型
book_name = str(li.xpath('./div[2]/h2/a/text()')[0])
# 将这本书的名字追加到书名列表中
book_name_list.append(book_name)
# 作者
# 用try...except...捕捉异常,因为有的商品没有作者,不捕捉的话,会报错,
try:
book_author = str(li.xpath('./div[2]/div[@class="author"]/a/text()')[0])
except:
# 捕捉成功,把作者用其他的值进行填充,因为后面会进行转成DataFrame表格,必须保证每一个列表的长度相同
book_author = '无作者'
# 将这本书的作者追加到作者列表中
book_author_list.append(book_author)
# 出版社,作同理
try:
book_publisher = str(li.xpath('./div[2]/div[@class="publisher"]/a/text()')[0])
except:
book_publisher = '无出版社'
book_publisher_list.append(book_publisher)
# 现价:¥15.9 因为我们只要数据,不要符号,所以对字符串进行了切片操作
sellPrice = str(li.xpath('./div[2]/div[@class="priceWrap"]/span[@class="sellPrice"]/text()')[0])[1:]
sellPrice_list.append(sellPrice)
# 折扣:(3.2折) 不要小括号,同样进行切片操作
discount = str(li.xpath('./div[2]/div[@class="priceWrap"]/span[@class="discount"]/text()')[0])[1:-1]
discount_list.append(discount)
# 定价
Pricing = str(li.xpath('./div[2]/div[@class="priceWrap"]/del/text()')[0])[1:]
Pricing_list.append(Pricing)
# 额外优惠信息,try...except...的作用同上
try:
activeIcon = str(li.xpath('./div[2]/div[@class="activeIcon""]/a/text()')[0])
except:
activeIcon = "无优惠"
activeIcon_list.append(activeIcon)
# 评论数 class="startWrap" :38条评论 我们只要数字,因为后面判断星级有用
book_content = str(li.xpath('./div[2]/div[@class="startWrap"]/a/text()')[0])
book_content_list.append(book_content)
# 星级
star_grade = 0
# 每一个星级都会有5个i标签,一个i标签代表0,半个,或者1个星,把所有的i标签放在一个列表里面
star_list = li.xpath('./div[2]/div[@class="startWrap"]/i')
# 遍历这个列表,获取每一个i标签
for star in star_list:
# 如果评论数为0,则星级一定是0
if int(book_content[:-3]) == 0:
star_grade = 0
# 结束当其次循环
break
# 获取当前i标签的属性对应的值
s = star.attrib.get("class")
# 代表了一个星
if s=="one":
star_grade+=1
elif s=="half":
# 代表了半个星
star_grade+=0.5
break
# 代表没有星
else:
star_grade = 0
break
star_grade_list.append(star_grade)
print(f"书名:{book_name},作者:{book_author},出版社:{book_publisher},现价:{sellPrice},折扣:{discount},定价:{Pricing},额外优惠:{activeIcon},评论数:{book_content},评分星级:{star_grade}星")
# 这是因为转换成DataFrame表格需哦呜,说明列表不一样长,所以我把每个列表的长度都打印出来,看看是哪里出了问题,最终找到并改正过来
# print(f"书名列表的长度:{len(book_name_list)}")
# print(f"作者列表的长度:{len(book_author_list)}")
# print(f"出版社列表的长度:{len(book_publisher_list)}")
# print(f"现价列表的长度:{len(sellPrice_list)}")
# print(f"折扣列表的长度:{len(discount_list)}")
# print(f"定价列表的长度:{len(Pricing_list)}")
# print(f"额外优惠列表的长度:{len(activeIcon_list)}")
# print(f"评论数列表的长度:{len(book_content_list)}")
# print(f"评分星级列表的长度:{len(star_grade_list)}")
# 将创建的列表存入字典
book_dict = {
"书名":book_name_list,
"作者":book_author_list,
"出版社": book_publisher_list,
"现价":sellPrice_list,
"折扣":discount_list,
"定价":Pricing_list,
"额外优惠信息":activeIcon_list,
"评论数":book_content_list,
"评分星级":star_grade_list
}
# 将字典转换成DataFrame表格
df = pd.DataFrame(book_dict)
# 将表格转成csv文件,这里软件内是可以看到的,但是拿出去用excel看就乱码,所以我们把文件复制出去之后,先用记事本修改它的编码为ANSI,然后就不了乱码了
df.to_csv(f'data/中图网排行榜TOP1000-{date}.csv',index=False,encoding='utf-8')

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)