urllib_ajax的get请求_豆瓣电影前十页
在豆瓣电影(排行榜动作类)页面中,找到获取信息对应的接口。分别获取第一页、第二页、第三页的对应接口的url。
·
找接口
在豆瓣电影(排行榜动作类)页面中,找到获取信息对应的接口。
分别获取第一页、第二页、第三页的对应接口的url
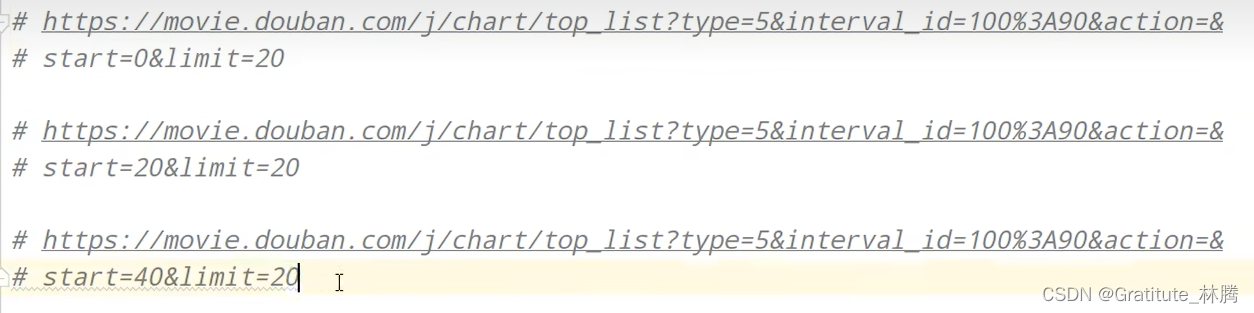
找规律
从中找到规律

从0开始,每一页20条数据
所以在url里面可以把start改成0,把limit改成200,这样就得到了前十页的数据了。
代码实现
# 下载豆瓣电影前十页的数据
# get请求
import urllib.request
url="https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=200"
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0'
}
# 将url和headers定制成一个request对象
request = urllib.request.Request(url=url,headers=headers)
# 使用urlopen方法得到页面内容
response = urllib.request.urlopen(request)
# 读取页面源码,并转成正确的格式
content = response.read().decode('utf-8')
print(content)
# 数据下载到本地
# open方法默认情况下使用的是gbk的编码,如果我们想要保存汉字,需要在open方法中指定编码格式为utf-8
# encoding = 'utf-8'
# 方式一
# fp = open('douban.json','w',encoding='utf-8')
# fp.write(content)
#方式二
with open('douban10.json','w',encoding='utf-8') as fp:
fp.write(content)
魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)