mybatis之动态sql语句解析
写在前面本文在这篇文章基础上进行分析,详细解析sql语句相关的解析工作。
写在前面
本文在这篇文章基础上进行分析,详细解析sql语句相关的解析工作。
想要系统学习的,可以参考这篇文章,重要!!!。
入口
在初始化解析全局配置文件的过程中,会执行到如下的方法:
org.apache.ibatis.builder.xml.XMLMapperBuilder#parse
public void parse() {
if (!configuration.isResourceLoaded(resource)) {
// 获取mapper xml中的<mapper/>标签,并执行解析
// <2021-08-16 14:26:06>
configurationElement(parser.evalNode("/mapper"));
configuration.addLoadedResource(resource);
bindMapperForNamespace();
}
...snip...
}
<2021-08-16 14:26:06>处是获取mapper xml中的<mapper/>标签,并执行解析,源码如下:
org.apache.ibatis.builder.xml.XMLMapperBuilder#configurationElement
private void configurationElement(XNode context) {
try {
// 获取当前<mapper/>标签的命名空间
String namespace = context.getStringAttribute("namespace");
if (namespace.equals("")) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
builderAssistant.setCurrentNamespace(namespace);
// 解析<cache-ref/>标签
cacheRefElement(context.evalNode("cache-ref"));
// 解析<cache/>标签
cacheElement(context.evalNode("cache"));
// 解析<parameterMap>标签
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
// 解析<resultMap/>标签
resultMapElements(context.evalNodes("/mapper/resultMap"));
// 解析<sql/>标签
sqlElement(context.evalNodes("/mapper/sql"));
// 解析增删改查标签
// <2021-08-16 14:31:13>
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. Cause: " + e, e);
}
}
<2021-08-16 14:31:13>处是解析增删改查标签,源码如下:
org.apache.ibatis.builder.xml.XMLMapperBuilder#buildStatementFromContext(java.util.List<org.apache.ibatis.parsing.XNode>)
private void buildStatementFromContext(List<XNode> list) {
if (configuration.getDatabaseId() != null) {
buildStatementFromContext(list, configuration.getDatabaseId());
}
// <2021-08-16 14:32:09>
buildStatementFromContext(list, null);
}
<2021-08-16 14:32:09>处源码如下:
org.apache.ibatis.builder.xml.XMLMapperBuilder#buildStatementFromContext(java.util.List<org.apache.ibatis.parsing.XNode>, java.lang.String)
private void buildStatementFromContext(List<XNode> list, String requiredDatabaseId) {
// 遍历所有的增删改查节点,依次处理
for(XNode context : list) {
final XMLStatementBuilder statementParser = new XMLStatementBuilder(configuration, builderAssistant, context, requiredDatabaseId);
try {
// 执行解析,生成org.apache.ibatis.mapping.MappedStatement
// <2021-08-16 14:34:24>
statementParser.parseStatementNode();
} catch (IncompleteElementException e) {
configuration.addIncompleteStatement(statementParser);
}
}
}
<2021-08-16 14:34:24>处是解析增删改查节点并生成对应的org.apache.ibatis.mapping.MappedStatement对象,源码如下:
org.apache.ibatis.builder.xml.XMLStatementBuilder#parseStatementNode
public void parseStatementNode() {
// 解析增删改查节点的id属性
String id = context.getStringAttribute("id");
// 解析增删改查节点的databaseId属性
String databaseId = context.getStringAttribute("databaseId");
if (!databaseIdMatchesCurrent(id, databaseId, this.requiredDatabaseId)) return;
// 解析增删改查节点的fetchSize属性
Integer fetchSize = context.getIntAttribute("fetchSize");
// 解析增删改查节点的timeout属性
Integer timeout = context.getIntAttribute("timeout");
// 解析增删改查节点的parameterMap属性
String parameterMap = context.getStringAttribute("parameterMap");
// 解析增删改查节点的parameterType属性
String parameterType = context.getStringAttribute("parameterType");
Class<?> parameterTypeClass = resolveClass(parameterType);
// 解析增删改节点的resultMap属性
String resultMap = context.getStringAttribute("resultMap");
// 解析增删改查节点的resultType属性
String resultType = context.getStringAttribute("resultType");
// 解析增删改查节点的lang属性
String lang = context.getStringAttribute("lang");
// 创建lang属性对应的org.apache.ibatis.scripting.LanguageDriver实例
LanguageDriver langDriver = getLanguageDriver(lang);
Class<?> resultTypeClass = resolveClass(resultType);
String resultSetType = context.getStringAttribute("resultSetType");
// 获取statementType属性值对应的org.apache.ibatis.mapping.StatementType枚举值
StatementType statementType = StatementType.valueOf(context.getStringAttribute("statementType", StatementType.PREPARED.toString()));
...snip...
// 解析sql语句,并生成org.apache.ibatis.scripting.SqlSource对象
// <2021-08-16 14:43:47>
SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
...snip...
// 创建org.apache.ibatis.mapping.MappedStatement对象并添加到org.apache.ibatis.session.Configuration
// 全局配置文件对象中
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets);
}
<2021-08-16 14:43:47>就是我们要分析的程序的入口了,下面我们就从这里开始吧,具体参考1:解析sql语句。
1:解析sql语句
源码如下:
org.apache.ibatis.scripting.xmltags.XMLLanguageDriver#createSqlSource(org.apache.ibatis.session.Configuration, org.apache.ibatis.parsing.XNode, java.lang.Class<?>)
public SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType) {
// 创建XMLScriptBuilder对象
XMLScriptBuilder builder = new XMLScriptBuilder(configuration, script, parameterType);
// 解析script节点
// <2021-08-16 15:14:39>
return builder.parseScriptNode();
}
<2021-08-16 15:14:39>处是解析script动态sql语句节点,源码如下:
org.apache.ibatis.scripting.xmltags.XMLScriptBuilder#parseScriptNode
public SqlSource parseScriptNode() {
// 获取所有的节点sql节点
// <2021-08-16 15:28:30>
List<SqlNode> contents = parseDynamicTags(context);
MixedSqlNode rootSqlNode = new MixedSqlNode(contents);
SqlSource sqlSource = null;
if (isDynamic) {
sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
} else {
sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
}
return sqlSource;
}
<2021-08-16 15:28:30>处是获取增删改查标签内部的所有的节点,具体参考1.1:获取增删改查标签内节点。
1.1:获取增删改查标签内节点
源码如下:
org.apache.ibatis.scripting.xmltags.XMLScriptBuilder#parseDynamicTags
private List<SqlNode> parseDynamicTags(XNode node) {
// 结果集合
List<SqlNode> contents = new ArrayList<SqlNode>();
// 获取增删改查节点内的所有的子节点
NodeList children = node.getNode().getChildNodes();
// 遍历所有的子节点依次处理
for (int i = 0; i < children.getLength(); i++) {
// 封装当前节点为org.apache.ibatis.parsing.XNode对象
XNode child = node.newXNode(children.item(i));
// 如果是节点是CDATA(输入包含特殊字符文本使用),或者是普通的文本节点
if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {
// 获取文本的内容,如"\n SELECT * FROM test_dynamic_sql \n"
// 这里的\n是换行符
String data = child.getStringBody("");
// 使用文本创建org.apache.ibatis.parsing.xmltags.TextSqlNode对象
TextSqlNode textSqlNode = new TextSqlNode(data);
// 如果是动态sql语句则直接添加,并标记动态标记为true,一般以下两种情况为动态sql
// 1:在sql语句中包含${xxx} 2:包含动态sql语句节点,如<if/>,<where/>,<trim/>,<foreach/>等
// 此处因为处理的是CDATA和文本的节点情况,所以是情况1
// <2021-08-16 15:43:23>
if (textSqlNode.isDynamic()) {
contents.add(textSqlNode);
isDynamic = true;
// 否则创建StaticTextSqlNode并添加到结果集合中
} else {
contents.add(new StaticTextSqlNode(data));
}
// 如果是元素节点,一般是<if/>,<foreach/>,<where/>,<trim/>等标签时,这里为true
} else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) {
// 获取节点的名称,如if,foreach,where,trim等
String nodeName = child.getNode().getNodeName();
// 根据当前动态sql语句节点的名称获取对应的节点处理器
// <2021-08-16 17:11:57>
NodeHandler handler = nodeHandlers.get(nodeName);
// 如果是没有获取到对应的处理器类,说明节点信息错误,直接异常
if (handler == null) {
throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
}
// 调用具体的处理器类处理动态sql语句节点
// <2021-08-16 17:30:33>
handler.handleNode(child, contents);
// 将动态sql语句的标记设置为true
isDynamic = true;
}
}
return contents;
}
<2021-08-16 15:43:23>处是判断是否为动态sql语句,具体参考1.1.1:判断是否为动态sql。<2021-08-16 17:11:57>处是根据动态sql语句节点的名称获取对应的处理器,具体参考1.1.2:根据动态节点名称获取处理器。<2021-08-16 17:30:33>处是使用动态sql标签的处理器来进行处理,具体参考2:各种动态sql标签处理器。
1.1.1:判断是否为动态sql
源码如下:
org.apache.ibatis.scripting.xmltags.TextSqlNode#isDynamic
public boolean isDynamic() {
// 创建DynamicCheckerTokenParser对象
DynamicCheckerTokenParser checker = new DynamicCheckerTokenParser();
// 创建解析器
// <2021-08-16 15:47:51>
GenericTokenParser parser = createParser(checker);
// 使用解析器解析文本
parser.parse(text);
// 返回是否为动态sql语句
return checker.isDynamic();
}
<2021-08-16 15:47:51>处是创建用于判断是否包含指定标记的解析器,源码如下:
org.apache.ibatis.scripting.xmltags.TextSqlNode#createParser
private GenericTokenParser createParser(TokenHandler handler) {
// 创建用于判断是否包含${xxx}的解析器,即如果是在sql文本中包含${xxx}则就是动态sql语句
return new GenericTokenParser("${", "}", handler);
}
1.1.2:根据动态节点名称获取处理器
源码中的noteHanders是一个Map和初始化如下:
private Map<String, NodeHandler> nodeHandlers = new HashMap<String, NodeHandler>() {
private static final long serialVersionUID = 7123056019193266281L;
{
put("trim", new TrimHandler());
put("where", new WhereHandler());
put("set", new SetHandler());
put("foreach", new ForEachHandler());
put("if", new IfHandler());
put("choose", new ChooseHandler());
put("when", new IfHandler());
put("otherwise", new OtherwiseHandler());
put("bind", new BindHandler());
}
};
处理类的接口定义如下:
org.apache.ibatis.scripting.xmltags.XMLScriptBuilder.NodeHandler
private interface NodeHandler {
void handleNode(XNode nodeToHandle, List<SqlNode> targetContents);
}
2:各种动态sql标签处理器
对应的接口如下:
org.apache.ibatis.scripting.xmltags.XMLScriptBuilder.NodeHandler
private interface NodeHandler {
void handleNode(XNode nodeToHandle, List<SqlNode> targetContents);
}
主要的实现类如下: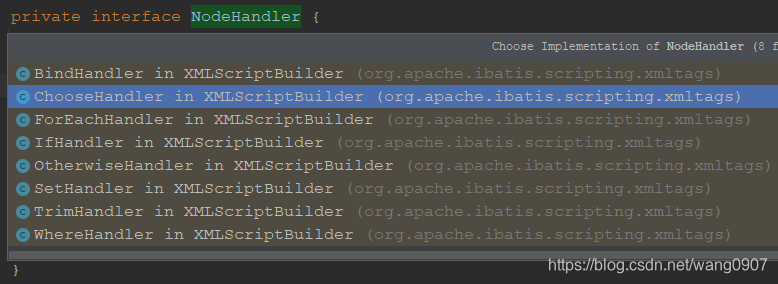
接下来我们分别看下每个实现类。
2.1:BindHandler
可能的配置,如:
<select id="queryListWithXmlDynamicSqlBind"
resultMap="myResultMap"
statementType="PREPARED">
<!-- 添加%模糊查询符号,这样程序里就需要添加了,不然程序调用几次就要添加几次,而这里只需要一次 -->
<bind name="myname_add_percent" value="'%' + myname + '%'"/>
SELECT * FROM test_dynamic_sql t WHERE t.`myname` LIKE #{myname_add_percent}
</select>
源码如下:
org.apache.ibatis.scripting.xmltags.XMLScriptBuilder.BindHandler
private class BindHandler implements NodeHandler {
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
// 获取name属性的值
final String name = nodeToHandle.getStringAttribute("name");
// 获取绑定后的value值
final String expression = nodeToHandle.getStringAttribute("value");
// <2021-08-17 10:37:18>
final VarDeclSqlNode node = new VarDeclSqlNode(name, expression);
targetContents.add(node);
}
}
<2021-08-17 10:37:18>处VarDeclSqlNode类继承自接口SqlNode,接口源码如下:
org.apache.ibatis.scripting.xmltags.SqlNode
// 每个xml的接口都会解析会解析成该类型的一个实例,只不过不同节点对应到接口的不同子类
// 如<bind/>节点对应到的就是BindHandle类
public interface SqlNode {
boolean apply(DynamicContext context);
}
VarDeclSqlNode源码如下:
org.apache.ibatis.scripting.xmltags.VarDeclSqlNode
public class VarDeclSqlNode implements SqlNode {
// 存储bind标签中name属性的值
private final String name;
// 存储bind标签中value属性的值,因为可能是ognl表达式,所以这里变量名称为expression
private final String expression;
// 构造函数
public VarDeclSqlNode(String var, String exp) {
name = var;
expression = exp;
}
public boolean apply(DynamicContext context) {
// 从ognl表达式缓存中获取值,该类是一个负责解析和缓存ognl表达式的类
final Object value = OgnlCache.getValue(expression, context.getBindings());
// 绑定到上下文中,其实就是存储bind标签对应的键值对到map中,方便后续获取使用
context.bind(name, value);
// 某些节点对应的SqlNode子类需要用到该布尔返回值,这里不需要,直接返回true
return true;
}
}
2.2:TrimHandler
源码如下:
org.apache.ibatis.scripting.xmltags.XMLScriptBuilder.TrimHandler
private class TrimHandler implements NodeHandler {
publicvoid handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
// 获取statement的所有的sql节点信息
// <2021-08-18 13:17:19>
List<SqlNode> contents = parseDynamicTags(nodeToHandle);
// 创建MixedSqlNode对象
MixedSqlNode mixedSqlNode = new MixedSqlNode(contents);
// 获取用于动态添加的前缀pefix属性值
String prefix = nodeToHandle.getStringAttribute("prefix");
// 获取用于动态删除的前缀prefixOverrides值
String prefixOverrides = nodeToHandle.getStringAttribute("prefixOverrides");
// 获取用于动态添加的后缀suffix的值
String suffix = nodeToHandle.getStringAttribute("suffix");
// 获取用于动态删除的后缀suffixOverrides的值
String suffixOverrides = nodeToHandle.getStringAttribute("suffixOverrides");
// 创建<trim/>节点对应的节点对象TrimSqlNode
// <2021-08-18 13:35:48>
TrimSqlNode trim = new TrimSqlNode(configuration, mixedSqlNode, prefix, prefixOverrides, suffix, suffixOverrides);
targetContents.add(trim);
}
}
<2021-08-18 13:17:19>处是获取所有的sql节点,比如如下可能的配置和对应的结果:
<trim prefix="set" suffixOverrides=",">
<if test="myname!=null">myname=#{myname},</if>
<if test="myage!=null">myage=#{myage}</if>
</trim>
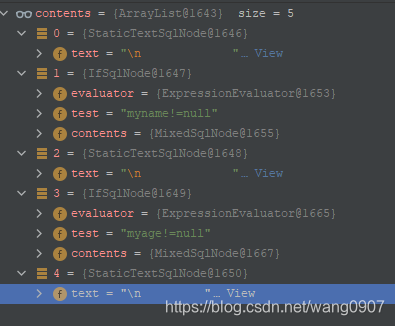
元素分别如下:
0:trim后的换行和空格内容
1:第一个if标签的内容
2:第一个if标签后的换行和空格内容
3:第二个if的内容
4:第二个if后的换行和空格内容
<2021-08-18 13:35:48>处是创建trim节点对应的TrimSqlNode对象,关于TrimSqlNode参考3.1:TrimSqlNode。
2.3:WhereHandler
源码如下:
org.apache.ibatis.scripting.xmltags.XMLScriptBuilder.WhereHandler
private class WhereHandler implements NodeHandler {
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
// 获取所有的子节点
List<SqlNode> contents = parseDynamicTags(nodeToHandle);
// 使用<where/>标签子节点封装为MixedSqlNode对象
MixedSqlNode mixedSqlNode = new MixedSqlNode(contents);
// 创建WhereSqlNode对象
// <2021-08-18 15:03:25>
WhereSqlNode where = new WhereSqlNode(configuration, mixedSqlNode);
targetContents.add(where);
}
}
<2021-08-18 15:03:25>处是创建WhereSqlNode,关于WhereSqlNode具体参考3.2:WhereSqlNode。
2.4:SetHandler
对应的是动态sql语句中的<set>标签,用在更新语句中,源码如下:
org.apache.ibatis.scripting.xmltags.XMLScriptBuilder.SetHandler
private class SetHandler implements NodeHandler {
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
// 获取<set/>标签的所有子节点
List<SqlNode> contents = parseDynamicTags(nodeToHandle);
// 通过<set/>标签的子节点创建MixedSqlNode节点
MixedSqlNode mixedSqlNode = new MixedSqlNode(contents);
// 创建SetSqlNode节点
// <2021-08-18 15:15:07>
SetSqlNode set = new SetSqlNode(configuration, mixedSqlNode);
targetContents.add(set);
}
}
<2021-08-18 15:15:07>处是通过<set>标签子节点创建SetSqlNode对象,关于SetSqlNode具体参考3.3:SetSqlNode。
2.5:ForEachHandler
源码如下:
org.apache.ibatis.scripting.xmltags.XMLScriptBuilder.ForEachHandler
private class ForEachHandler implements NodeHandler {
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
// 获取<foreach/>标签的所有子节点(包含换行符等各种不可见字符)
List<SqlNode> contents = parseDynamicTags(nodeToHandle);
// 使用<foreach/>标签的子节点创建org.apache.ibatis.scripting.xmltags.MixedSqlNode对象
MixedSqlNode mixedSqlNode = new MixedSqlNode(contents);
// 获取collection属性,该属性用于配置集合的类型
String collection = nodeToHandle.getStringAttribute("collection");
// 获取item属性值,该值用于设置遍历集合的每个条目的变量名
String item = nodeToHandle.getStringAttribute("item");
// 索引值
String index = nodeToHandle.getStringAttribute("index");
// 获取open属性值,即需要添加在最前面的信息,如in,为"("
String open = nodeToHandle.getStringAttribute("open");
// 获取close属性值,即需要添加在最后面的信息,如in,为")"
String close = nodeToHandle.getStringAttribute("close");
// 获取separator属性值,即遍历生成的每个元素的分割符,如in,为","
String separator = nodeToHandle.getStringAttribute("separator");
// 创建<foreach>标签对应的ForEachSqlNode节点
// <2021-08-18 16:31:11>
ForEachSqlNode forEachSqlNode = new ForEachSqlNode(configuration, mixedSqlNode, collection, index, item, open, close, separator);
targetContents.add(forEachSqlNode);
}
}
<2021-08-18 16:31:11>处是通过<foreach>标签的配置信息创建ForEachNode对象,具体参考3.4:ForEachNode。
2.6:IfHandler
源码如下:
org.apache.ibatis.scripting.xmltags.XMLScriptBuilder.IfHandler
private class IfHandler implements NodeHandler {
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
// 获取<if>节点的子节点
List<SqlNode> contents = parseDynamicTags(nodeToHandle);
// 将<if>节点子节点封装为MixedSqlNode节点
MixedSqlNode mixedSqlNode = new MixedSqlNode(contents);
// 获取<if>标签中的test属性的值
String test = nodeToHandle.getStringAttribute("test");
// 将<if>标签封装为对应的IfSqlNode对象
// <2021-08-18 17:39:56>
IfSqlNode ifSqlNode = new IfSqlNode(mixedSqlNode, test);
targetContents.add(ifSqlNode);
}
}
<2021-08-18 17:39:56>是将<if>标签封装为对应的IfSqlNode对象,具体参考3.5:IfSqlNode。
2.7:OtherwiseHandler
源码如下:
org.apache.ibatis.scripting.xmltags.XMLScriptBuilder.OtherwiseHandler
private class OtherwiseHandler implements NodeHandler {
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
// 获取<otherwise>节点的所有子节点
List<SqlNode> contents = parseDynamicTags(nodeToHandle);
// 将<otherwise>节点的子节点封装为MixedSqlNode对象
MixedSqlNode mixedSqlNode = new MixedSqlNode(contents);
// 直接添加
targetContents.add(mixedSqlNode);
}
}
2.8:ChooseHandler
源码如下:
org.apache.ibatis.scripting.xmltags.XMLScriptBuilder.ChooseHandler
private class ChooseHandler implements NodeHandler {
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
// <choose/>标签的<when/>子标签集合
List<SqlNode> whenSqlNodes = new ArrayList<SqlNode>();
// <choose/>标签的<otherwise/>子标签集合
List<SqlNode> otherwiseSqlNodes = new ArrayList<SqlNode>();
// 处理<when>,<otherwise>标签
handleWhenOtherwiseNodes(nodeToHandle, whenSqlNodes, otherwiseSqlNodes);
// 获取默认标签,即<otherwise>标签
SqlNode defaultSqlNode = getDefaultSqlNode(otherwiseSqlNodes);
// 将<when>标签集合和<otherwise>标签集合封装为ChooseSqlNode对象
// <2021-08-18 18:01:38>
ChooseSqlNode chooseSqlNode = new ChooseSqlNode(whenSqlNodes, defaultSqlNode);
targetContents.add(chooseSqlNode);
}
private void handleWhenOtherwiseNodes(XNode chooseSqlNode, List<SqlNode> ifSqlNodes, List<SqlNode> defaultSqlNodes) {
List<XNode> children = chooseSqlNode.getChildren();
for (XNode child : children) {
// 根据节点名称获取对应的节点处理器
String nodeName = child.getNode().getNodeName();
NodeHandler handler = nodeHandlers.get(nodeName);
// 这里需要注意<when>标签对应的处理器和<if>标签是一样的,因为都是判断逻辑,标签名称不同而已
// <2021-08-18 18:07:10>
if (handler instanceof IfHandler) {
handler.handleNode(child, ifSqlNodes);
// otherwise标签情况,对应的handler是OtherwiseHandler
// <2021-08-18 18:08:19>
} else if (handler instanceof OtherwiseHandler) {
handler.handleNode(child, defaultSqlNodes);
}
}
}
// 获取唯一的<otherwise>节点,<otherwise>节点要么没有要么只能有一个
private SqlNode getDefaultSqlNode(List<SqlNode> defaultSqlNodes) {
SqlNode defaultSqlNode = null;
// 需要注意的一点是<otherwise>节点只能有一个,因此会有一个对于长度>1是抛出异常的逻辑
if (defaultSqlNodes.size() == 1) {
defaultSqlNode = defaultSqlNodes.get(0);
} else if (defaultSqlNodes.size() > 1) {
throw new BuilderException("Too many default (otherwise) elements in choose statement.");
}
return defaultSqlNode;
}
}
<2021-08-18 18:01:38>处是将when节点信息和otherwise节点信息封装为ChooseSqlNode,关于ChooseSqlNode参考3.6:ChooseSqlNode。<2021-08-18 18:07:10>处的IfHandler具体参考2.6:IfHandler,<2021-08-18 18:08:19>处是处理otherwise标签,对应的handle是OtherwiseHandler,具体参考2.7:OtherwiseHandler。
3:各种标签对应的节点
对应的接口如下:
org.apache.ibatis.scripting.xmltags.SqlNode
public interface SqlNode {
boolean apply(DynamicContext context);
}
3.1:TrimSqlNode
这是<trim/>节点对应的类,源码如下:
构造函数,源码如下:
private SqlNode contents;
private String prefix;
private String suffix;
private List<String> prefixesToOverride;
private List<String> suffixesToOverride;
private Configuration configuration;
public TrimSqlNode(Configuration configuration, SqlNode contents, String prefix, String prefixesToOverride, String suffix, String suffixesToOverride) {
this(configuration, contents, prefix, parseOverrides(prefixesToOverride), suffix, parseOverrides(suffixesToOverride));
}
protected TrimSqlNode(Configuration configuration, SqlNode contents, String prefix, List<String> prefixesToOverride, String suffix, List<String> suffixesToOverride) {
// 所有的子节点集合构成的MixSqlNode对象
this.contents = contents;
// trim标签中配置的prefix属性值
this.prefix = prefix;
// trim标签中配置的prefixesOverride值
this.prefixesToOverride = prefixesToOverride;
// trim标签中配置的suffix值
this.suffix = suffix;
// trim标签中配置的suffixesToOverrides值
this.suffixesToOverride = suffixesToOverride;
// 全局配置文件对应的org.apache.ibatis.session.Configuration对象
this.configuration = configuration;
}
apply方法源码如下:
org.apache.ibatis.scripting.xmltags.TrimSqlNode#apply
public boolean apply(DynamicContext context) {
// 创建FiteredDynamicContext对象,该对象用于辅助动态sql语句生成最终sql
// <2021-08-18 13:50:50>
FilteredDynamicContext filteredDynamicContext = new FilteredDynamicContext(context);
// 这里的contents是封装了trim子节点信息的MixedSqlNode对象
// <2021-08-18 14:16:06>
boolean result = contents.apply(filteredDynamicContext);
// 应用trim信息,生成最终的sql语句
// <2021-08-18 14:35:05>
filteredDynamicContext.applyAll();
return result;
}
<2021-08-18 13:50:50>处FiteredDynamicContext对象参考2.1.1:FiteredDynamicContext。<2021-08-18 14:16:06>处是应用trim的子节点信息,具体参考2.1.2:应用trim子节点信息。<2021-08-18 14:35:05>处是应用trim的配置信息,生成最终sql,具体参考2.1.3:应用trim信息生成最终sql。
3.1.1:FiteredDynamicContext
构造函数源码如下:
org.apache.ibatis.scripting.xmltags.TrimSqlNode.FilteredDynamicContext#FilteredDynamicContext
public FilteredDynamicContext(DynamicContext delegate) {
super(configuration, null);
// 设置被代理的对象,该对象是封装了动态sql语句和参数相关信息
this.delegate = delegate;
// 是否已经应用了前缀的标记,默认为false
this.prefixApplied = false;
// 是否已经引用了后缀的标记,默认为false
this.suffixApplied = false;
// 生成的sql语句信息
this.sqlBuffer = new StringBuilder();
}
3.1.2:应用trim子节点信息
源码如下:
org.apache.ibatis.scripting.xmltags.MixedSqlNode#apply
public boolean apply(DynamicContext context) {
// 遍历trim节点的所有子节点信息,依次调用自己的apply方法
for (SqlNode sqlNode : contents) {
// 调用当前SqlNode的apply方法
// <2021-08-18 14:20:59>
sqlNode.apply(context);
}
return true;
}
<2021-08-18 14:20:59>处当节点为StaticTextSqlNode时参考2.1.2.1:StaticTextSqlNode的apply。<2021-08-18 14:20:59>处当节点为IfSqlNode时参考2.1.2.2:IfSqlNode的apply。通过这个过程来拼接生成多个<if>标签构成的sql语句,如下配置:
UPDATE test_dynamic_sql
<trim prefix="set" suffixOverrides=",">
<if test="myname!=null">myname=#{myname},</if>
<if test="myage!=null">myage=#{myage}</if>
</trim>
当第一个条件满足时,最终的sql语句是UPDATE test_dynamic_sql myname=#{myname},,注意此时sql语句少一个set,多一个,这个添加set和去除,的工作需要通过后续的代码完成,,具体参考2.1.3:应用trim信息生成最终sql。
3.1.2.1:StaticTextSqlNode的apply
源码如下:
org.apache.ibatis.scripting.xmltags.StaticTextSqlNode#apply
public boolean apply(DynamicContext context) {
// 拼接sql
// <2021-08-18 14:23:07>
context.appendSql(text);
return true;
}
<2021-08-18 14:23:07>处源码如下:
org.apache.ibatis.scripting.xmltags.TrimSqlNode.FilteredDynamicContext#appendSql
public void appendSql(String sql) {
// 直接拼接
// private StringBuilder sqlBuffer;
sqlBuffer.append(sql);
}
3.1.2.2:IfSqlNode的apply
源码如下:
org.apache.ibatis.scripting.xmltags.IfSqlNode#apply
public boolean apply(DynamicContext context) {
// 判断是否符合条件,符合条件才继续
if (evaluator.evaluateBoolean(test, context.getBindings())) {
// private SqlNode contents;
// 此时contents又是一个MiexSqlNode,相当于是递归调用
contents.apply(context);
return true;
}
return false;
}
3.1.3:应用trim信息生成最终sql
源码如下:
org.apache.ibatis.scripting.xmltags.TrimSqlNode.FilteredDynamicContext#applyAll
public void applyAll() {
// 获取当前的sql语句,如myname=#{myname},
sqlBuffer = new StringBuilder(sqlBuffer.toString().trim());
// 转小写,避免大小写造成问题
String trimmedUppercaseSql = sqlBuffer.toString().toUpperCase(Locale.ENGLISH);
if (trimmedUppercaseSql.length() > 0) {
// 应用前缀 如update语句添加set
// <2021-08-18 14:39:29>
applyPrefix(sqlBuffer, trimmedUppercaseSql);
applySuffix(sqlBuffer, trimmedUppercaseSql);
}
delegate.appendSql(sqlBuffer.toString());
}
<2021-08-18 14:39:29>处源码如下:
org.apache.ibatis.scripting.xmltags.TrimSqlNode.FilteredDynamicContext#applyPrefix
private void applyPrefix(StringBuilder sql, String trimmedUppercaseSql) {
// 还没有应用前缀才继续
if (!prefixApplied) {
// 设置前缀已经应用,方式重复添加前缀
prefixApplied = true;
// 如果是需要动态删除的前缀不为空,则先动态删除
// 比如配置<trim prefix="where" suffixOverrides="and">,此时sql为
// “and name='张三' and age='90'”, 处理后就是 ‘ name='张三' and age='90'”
if (prefixesToOverride != null) {
for (String toRemove : prefixesToOverride) {
if (trimmedUppercaseSql.startsWith(toRemove)) {
sql.delete(0, toRemove.trim().length());
break;
}
}
}
// 如果是prefix为不空,则动态添加
// 比如配置<trim prefix="where" suffixOverrides="and">,此时sql为
// “name='张三' and age='90'”, 处理后就是 ‘where name='张三' and age='90'”
if (prefix != null) {
// 先添加个空格,防止sql语法错误
sql.insert(0, " ");
sql.insert(0, prefix);
}
}
}
3.2:WhereSqlNode
构造函数如下:
org.apache.ibatis.scripting.xmltags.WhereSqlNode
// 注意这是TrimSqlNode的一个子类,因为where标签只是trim标签的一种特殊情况而已,所以
// 直接继承然后指定prefix和prefixOverrides就可以了,不需要实现其他逻辑
public class WhereSqlNode extends TrimSqlNode {
// where中可能的需要替换的前缀,列举了我们写程序时所有可能的写法
private static List<String> prefixList = Arrays.asList("AND ","OR ","AND\n", "OR\n", "AND\r", "OR\r", "AND\t", "OR\t");
public WhereSqlNode(Configuration configuration, SqlNode contents) {
// 直接调用父类TrimSqlNode创建对象
// <2021-08-18 15:08:11>
super(configuration, contents, "WHERE", prefixList, null, null);
}
}
<2021-08-18 15:08:11>处是通过通过父类org.apache.ibatis.scripting.xmltags.TrimSqlNode创建实例,关于org.apache.ibatis.scripting.xmltags.TrimSqlNode具体参考3.1:TrimSqlNode。
3.3:SetSqlNode
源码如下:
org.apache.ibatis.scripting.xmltags.SetSqlNode
// 这里继承org.apache.ibatis.scripting.xmltags.TrimSqlNode的原因是
// <set>标签时<trim>标签的一种特殊情况而已,即相当于是trim的如下设置
// <trim prefix="set" suffixOverrides=",">
public class SetSqlNode extends TrimSqlNode {
// suffixOverrides的集合值
private static List<String> suffixList = Arrays.asList(",");
public SetSqlNode(Configuration configuration,SqlNode contents) {
// 将prefix这是为set,并调用父类构造函数创建实例
// <2021-08-18 15:20:28>
super(configuration, contents, "SET", null, null, suffixList);
}
}
<2021-08-18 15:20:28>处是设置设置前缀为set,并调用父类org.apache.ibatis.scripting.xmltags,TrimSqlNode创建实例,关于org.apache.ibatis.scirpting.xmltags.TrimSqlNode具体参考3.1:TrimSqlNode。
3.4:ForEachNode
构造函数如下:
org.apache.ibatis.scripting.xmltags.ForEachSqlNode#ForEachSqlNode
public ForEachSqlNode(Configuration configuration, SqlNode contents, String collectionExpression, String index, String item, String open, String close, String separator) {
// 表达式解析器
this.evaluator = new ExpressionEvaluator();
// 集合的表达式,即在foreach标签中的collection属性中设置的值,如list
this.collectionExpression = collectionExpression;
// 封装foreach标签子节点的MixedSqlNode对象
this.contents = contents;
// foreach标签中open属性设置的值
this.open = open;
// foreach标签中close属性设置的值
this.close = close;
// foreach标签中separator设置的值
this.separator = separator;
// foreach标签中index属性设置的值
this.index = index;
// foreach标签中item属性设置的值
this.item = item;
// 全局配置文件对应的org.apache.ibatis.session.Configuration对象
this.configuration = configuration;
}
apply源码如下:
org.apache.ibatis.scripting.xmltags.ForEachSqlNode#apply
public boolean apply(DynamicContext context) {
// 获取参数信息
// <2021-08-18 16:41:50>
Map<String, Object> bindings = context.getBindings();
// 获取指定集合的迭代器对象,后续使用该迭代器对象迭代每个元素
final Iterable<?> iterable = evaluator.evaluateIterable(collectionExpression, bindings);
// 一个元素都没有的情况
if (!iterable.iterator().hasNext()) {
return true;
}
boolean first = true;
// 先添加open属性的值
// <2021-08-18 16:46:50>
applyOpen(context);
int i = 0;
for (Object o : iterable) {
DynamicContext oldContext = context;
// 如果当前是第一个元素
if (first) {
// 创建PrefixedContext实例,构造函数如下:
/*
private DynamicContext delegate;
private String prefix;
private boolean prefixApplied;
public PrefixedContext(DynamicContext delegate, String prefix) {
super(configuration, null);
this.delegate = delegate;
// 前缀
this.prefix = prefix;
// 是否已经应用前缀
this.prefixApplied = false;
}
*/
// 该对象用于处理分隔符,因为首个元素不需要分隔符,所以这里传入""
context = new PrefixedContext(context, "");
// 非首个元素情况
} else {
// 如果是<foreach>标签中设置了separator属性值,则传入分割符,否则就是需要分隔符,直接传入""
if (separator != null) {
context = new PrefixedContext(context, separator);
} else {
context = new PrefixedContext(context, "");
}
}
// 生成唯一数字,用于存储索引值,和当前遍历的条目对象
int uniqueNumber = context.getUniqueNumber();
// 如果是map.entry
if (o instanceof Map.Entry) { // Issue #709
@SuppressWarnings("unchecked")
Map.Entry<Object, Object> mapEntry = (Map.Entry<Object, Object>) o;
// 使用map.entry的键作为索引值,以uniqueNumber为标识存储
applyIndex(context, mapEntry.getKey(), uniqueNumber);
// 使用map.entry的value作为条目值,以uniqueNumber为标识存储
applyItem(context, mapEntry.getValue(), uniqueNumber);
// list,set等的情况
} else {
// 使用i,即当前遍历的位置作为索引值,使用uniqueNumber作为唯一标识存储
applyIndex(context, i, uniqueNumber);
// 使用o,即当前遍历的条目作为条目值,使用uniqueNumber作为唯一标识存储
applyItem(context, o, uniqueNumber);
}
// 调用MixedSqlNode应用<foreach>标签的所有子节点,其实就是生成sql语句
// <2021-08-18 17:22:05>
contents.apply(new FilteredDynamicContext(configuration, context, index, item, uniqueNumber));
// 判断prefix是否已经插入
if (first) first = !((PrefixedContext) context).isPrefixApplied();
context = oldContext;
i++;
}
// 添加close后缀
applyClose(context);
return true;
}
<2021-08-18 16:41:50>处是获取foreach的collection属性值对应的集合的参数信息,如下可能的结果: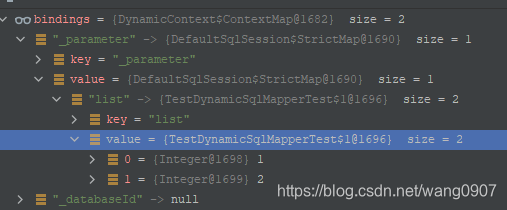
<2021-08-18 16:46:50>处是添加open属性的值,源码如下:
org.apache.ibatis.scripting.xmltags.ForEachSqlNode#applyOpen
private void applyOpen(DynamicContext context) {
// 添加sql语句
if (open != null) {
// 该处代码再前面已经分析过了,其实就是向StringBuilder中追加信息,这里是添加open属性值
context.appendSql(open);
}
}
<2021-08-18 17:22:05>是应用foreach标签的子节点生成sql语句,具体参考3.1.2:应用trim子节点信息。
3.5:IfSqlNode
构造函数如下:
private ExpressionEvaluator evaluator;
private String test;
private SqlNode contents;
public IfSqlNode(SqlNode contents, String test) {
this.test = test;
this.contents = contents;
this.evaluator = new ExpressionEvaluator();
}
apply方法源码如下:
org.apache.ibatis.scripting.xmltags.IfSqlNode#apply
public boolean apply(DynamicContext context) {
// 如果是test表达式的值为true
if (evaluator.evaluateBoolean(test, context.getBindings())) {
// 应用<if>标签的所有子节点,生成sql语句
contents.apply(context);
return true;
}
return false;
}
3.6:ChooseSqlNode
源码如下:
public class ChooseSqlNode implements SqlNode {
private SqlNode defaultSqlNode;
private List<SqlNode> ifSqlNodes;
public ChooseSqlNode(List<SqlNode> ifSqlNodes, SqlNode defaultSqlNode) {
this.ifSqlNodes = ifSqlNodes;
this.defaultSqlNode = defaultSqlNode;
}
public boolean apply(DynamicContext context) {
for (SqlNode sqlNode : ifSqlNodes) {
if (sqlNode.apply(context)) {
return true;
}
}
if (defaultSqlNode != null) {
defaultSqlNode.apply(context);
return true;
}
return false;
}
}
写在后面
本部分通过分析scripting包相关的API,看了针对动态sql语句是如何进行解析的,这些解析逻辑是通过org.apache.ibatis.mapping.SqlSource的API调用获取sql语句时来执行的,关于SqlSource的具体内容可以参考这篇文章。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)