爬虫之lxml模块中etree.tostring函数的使用
爬虫之lxml模块中etree.tostring函数的使用运行下边的代码,观察对比html的原字符串和打印输出的结果from lxml import etreehtml_str = ''' <div> <ul><li class="item-1"><a href="link1.html">first item</a></li>
·
爬虫之lxml模块中etree.tostring函数的使用
运行下边的代码,观察对比html的原字符串和打印输出的结果
from lxml import etree
html_str = ''' <div> <ul>
<li class="item-1"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul> </div>
'''
html = etree.HTML(html_str)
print(html)
handeled_html_str = etree.tostring(html).decode()
# handeled_html_str = etree.tostring(html)
print(handeled_html_str)
运行效果:
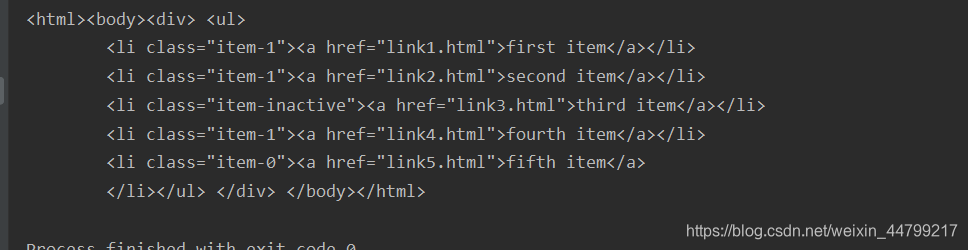
1.1 现象和结论
打印结果和原来相比:
- 自动补全原本缺失的
li标签- 自动补全
html等标签
<html><body><div> <ul>
<li class="item-1"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</li></ul> </div> </body></html>
结论:
-
lxml.etree.HTML(html_str)可以自动补全标签
-
lxml.etree.tostring函数可以将转换为Element对象再转换回html字符串 - 爬虫如果使用lxml来提取数据,应该以
lxml.etree.tostring的返回结果作为提取数据的依据

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 4
4 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)