简单上手-docker搭建kafka环境(单例和集群)
本章内容介绍如何用docker的方式搭建kafka环境。由于kafka采用的注册中心为zookeeper,所以我们需要先部署zookeeper,再部署kafka。
·
本章内容介绍如何用docker的方式搭建kafka环境。由于kafka采用的注册中心为zookeeper,所以我们需要先部署zookeeper,再部署kafka。
一、单实例搭建
(一)、构建环境
1、拉取zookeeper镜像
docker pull wurstmeister/zookeeper
2、启动zookeeper
docker run -d --name zookeeper -p 2181:2181 wurstmeister/zookeeper

3、拉取kafka镜像
docker pull wurstmeister/kafka
4、启动kafka
docker run -d --name kafka -p 9092:9092 --link zookeeper:zookeeper --env KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 --env KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.102.179:9092 --env KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 --env KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 wurstmeister/kafka

5、检测容器运行状况
运行下列命令,可以看到容器的运行状态
docker ps

(二)、控制台测试接收消息
1、创建一个测试主题
在Kafka容器中,运行以下命令创建一个名字叫testone的主题:
kafka-topics.sh --create --topic testone --partitions 1 --replication-factor 1 --zookeeper zookeeper:2181

2、生产者发送消息
执行创建生产者命令,然后可以对主题testone发送一些消息
kafka-console-producer.sh --broker-list 192.168.102.179:9092 --topic testone

3、消费者接收消息
创建一个消费者,然后可以对主题testone接收消息
kafka-console-consumer.sh --bootstrap-server 192.168.102.179:9092 --topic testone --from-beginning

上面流程就完成了对kafka的消息收发验证
二、集群搭建
(一)、配置数据目录
1.创建数据目录
mkdir -p /tmp/kafka/broker{1..3}/{data,logs}
mkdir -p /tmp/zookeeper/zookeeper/{data,datalog,logs,conf}

(二)、创建Zookeeper配置文件
1、zoo.cfg配置文件
vim /tmp/zookeeper/zookeeper/conf/zoo.cfg
文件内容如下
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/data
dataLogDir=/datalog
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
autopurge.purgeInterval=1
2、log4j.properties配置文件
vim /tmp/zookeeper/zookeeper/conf/log4j.properties
文件内容如下
# Define some default values that can be overridden by system properties
zookeeper.root.logger=INFO, CONSOLE
zookeeper.console.threshold=INFO
zookeeper.log.dir=/logs
zookeeper.log.file=zookeeper.log
zookeeper.log.threshold=DEBUG
zookeeper.tracelog.dir=.
zookeeper.tracelog.file=zookeeper_trace.log
#
# ZooKeeper Logging Configuration
#
# Format is "<default threshold> (, <appender>)+
# DEFAULT: console appender only
log4j.rootLogger=${zookeeper.root.logger}
# Example with rolling log file
#log4j.rootLogger=DEBUG, CONSOLE, ROLLINGFILE
# Example with rolling log file and tracing
#log4j.rootLogger=TRACE, CONSOLE, ROLLINGFILE, TRACEFILE
#
# Log INFO level and above messages to the console
#
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.Threshold=${zookeeper.console.threshold}
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n
#
# Add ROLLINGFILE to rootLogger to get log file output
# Log DEBUG level and above messages to a log file
log4j.appender.ROLLINGFILE=org.apache.log4j.RollingFileAppender
log4j.appender.ROLLINGFILE.Threshold=${zookeeper.log.threshold}
log4j.appender.ROLLINGFILE.File=${zookeeper.log.dir}/${zookeeper.log.file}
# Max log file size of 10MB
log4j.appender.ROLLINGFILE.MaxFileSize=10MB
# uncomment the next line to limit number of backup files
log4j.appender.ROLLINGFILE.MaxBackupIndex=10
log4j.appender.ROLLINGFILE.layout=org.apache.log4j.PatternLayout
log4j.appender.ROLLINGFILE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n
#
# Add TRACEFILE to rootLogger to get log file output
# Log DEBUG level and above messages to a log file
log4j.appender.TRACEFILE=org.apache.log4j.FileAppender
log4j.appender.TRACEFILE.Threshold=TRACE
log4j.appender.TRACEFILE.File=${zookeeper.tracelog.dir}/${zookeeper.tracelog.file}
log4j.appender.TRACEFILE.layout=org.apache.log4j.PatternLayout
### Notice we are including log4j's NDC here (%x)
log4j.appender.TRACEFILE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L][%x] - %m%n
(三)、创建Docker编排文件
vim docker-compose.yaml
文件内容如下
version: '2'
services:
zookeeper:
container_name: zookeeper
image: wurstmeister/zookeeper
restart: unless-stopped
hostname: zoo1
volumes:
- "/tmp/zookeeper/zookeeper/data:/data"
- "/tmp/zookeeper/zookeeper/datalog:/datalog"
- "/tmp/zookeeper/zookeeper/logs:/logs"
- "/tmp/zookeeper/zookeeper/conf:/opt/zookeeper-3.4.13/conf"
ports:
- "2181:2181"
networks:
- kafka
kafka1:
container_name: kafka1
image: wurstmeister/kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 192.168.102.179 ## 修改:宿主机IP
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.102.179:9092 ## 修改:宿主机IP
KAFKA_ZOOKEEPER_CONNECT: "zoo1:2181"
KAFKA_ADVERTISED_PORT: 9092
KAFKA_BROKER_ID: 1
KAFKA_LOG_DIRS: /kafka/data
volumes:
- /tmp/kafka/broker1/logs:/opt/kafka/logs
- /tmp/kafka/broker1/data:/kafka/data
depends_on:
- zookeeper
networks:
- kafka
kafka2:
container_name: kafka2
image: wurstmeister/kafka
ports:
- "9093:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 192.168.102.179 ## 修改:宿主机IP
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.102.179:9093 ## 修改:宿主机IP
KAFKA_ZOOKEEPER_CONNECT: "zoo1:2181"
KAFKA_ADVERTISED_PORT: 9093
KAFKA_BROKER_ID: 2
KAFKA_LOG_DIRS: /kafka/data
volumes:
- /tmp/kafka/broker2/logs:/opt/kafka/logs
- /tmp/kafka/broker2/data:/kafka/data
depends_on:
- zookeeper
networks:
- kafka
kafka3:
container_name: kafka3
image: wurstmeister/kafka
ports:
- "9094:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 192.168.102.179 ## 修改:宿主机IP
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.102.179:9094 ## 修改:宿主机IP
KAFKA_ZOOKEEPER_CONNECT: "zoo1:2181"
KAFKA_ADVERTISED_PORT: 9094
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3
KAFKA_MIN_INSYNC_REPLICAS: 2
KAFKA_BROKER_ID: 3
KAFKA_LOG_DIRS: /kafka/data
volumes:
- /tmp/kafka/broker3/logs:/opt/kafka/logs
- /tmp/kafka/broker3/data:/kafka/data
depends_on:
- zookeeper
networks:
- kafka
kafka-manager:
image: sheepkiller/kafka-manager ## 镜像:开源的web管理kafka集群的界面
environment:
ZK_HOSTS: 192.168.102.179 ## 修改:宿主机IP
ports:
- "9000:9000" ## 暴露端口
networks:
- kafka
networks:
kafka:
driver: bridge
(四)、启动服务
docker-compose up -d
由于网络拉取有问题,就没安装kafka-manager

(五)、springcloud整合连接测试
这里用java整合连接kafka进行测试,为了方便简单,将生产者和消费者都弄在一个服务里
1、pom依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>2021.0.2</version> <!-- 确保与 Spring Boot 2.6.x 兼容 -->
<scope>import</scope>
<type>pom</type>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
<version>2.2.1.RELEASE</version>
</dependency>
</dependencies>
2、application.yml
添加kafka的相关配置
spring:
kafka:
bootstrap-servers: 192.168.102.179:9092,192.168.102.179:9093,192.168.102.179:9094
consumer:
group-id: my-consumer-group # 消费者组ID,多个消费者可以共享这个ID
enable-auto-commit: true # 自动提交消费的位移
auto-offset-reset: earliest # 如果没有初始偏移量,则从最早的消息开始消费
producer:
acks: all # 生产者确认模式,'all'表示等待所有副本确认,确保消息不丢失
retries: 3 # 生产者最大重试次数
batch-size: 16384 # 批量发送消息的大小(字节数)
linger-ms: 5 # 消息批处理延迟,等待更多消息聚集再一起发送
cloud:
stream:
kafka:
binder:
zk-nodes: 192.168.102.179:2181 #Zookeeper的节点,如果集群,后面加,号分隔
auto-create-topics: true #如果设置为false,就不会自动创建Topic 有可能你Topic还没创建就直接调用了。
brokers: ${spring.kafka.bootstrap-servers}
auto-add-partitions: true #自动分区
replication-factor: 3 #副本
min-partition-count: 3 #最小分区
bindings:
stream-topic1-out-0:
producer:
retries: Integer.MAX_VALUE # 无限重试次数,避免丢失消息
acks: all # 设置生产者的确认方式,确保消息的可靠性
batch-size: 16384 # 设置生产者批量发送的大小
linger-ms: 5 # 设置批量发送消息的延迟时间
min:
insync:
replicas: 3 # 确保消息至少被3个副本成功写入
stream-topic1-in-0:
consumer:
concurrency: 1 # 设置消费者的并发数
group: my-consumer-group # 消费者组ID,确保多个消费者在同一组内共享消息
enable-dlq: true # 启用死信队列(DLQ),用于处理消费失败的消息
max-attempts: 3 # 设置消息消费的最大尝试次数
3、生产者StreamClient
import org.springframework.cloud.stream.annotation.Output;
import org.springframework.messaging.MessageChannel;
/**
* @Author 码至终章
* @Date 2025/1/15 10:40
* @Version 1.0
*/
public interface StreamClient {
String STREAM_DEMO = "stream-topic1";
@Output(StreamClient.STREAM_DEMO)
MessageChannel streamDateOut();
}
4、消费者StreamClient
import org.springframework.cloud.stream.annotation.Input;
import org.springframework.messaging.SubscribableChannel;
/**
* @Author 码至终章
* @Date 2025/1/15 10:40
* @Version 1.0
*/
public interface StreamClient {
String STREAM_DEMO = "stream-topic1";
//SubscribableChannel与生产者处写的不一样,此处为接收信息
@Input(StreamClient.STREAM_DEMO)
SubscribableChannel streamDateInput();
}
5、消费者订阅消息
import lombok.extern.slf4j.Slf4j;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.annotation.StreamListener;
/**
* @Author 码至终章
* @Date 2025/1/8 14:19
* @Version 1.0
*/
@Slf4j
@EnableBinding(StreamClient.class)
public class MyKafkaConsumer {
@StreamListener(StreamClient.STREAM_DEMO)
public void consume(String message) {
log.info("接收到主题消息,消息内容:{}", message);
}
}
6、生产者发送消息
@RestController
@Slf4j
@EnableBinding(StreamClient.class)
public class KafkaMsgController {
@Resource
private StreamClient streamClient;
@GetMapping("/sendMessage")
public String sendMessage() {
streamClient.streamDateOut().send(MessageBuilder.withPayload("nice food").build());
return "成功";
}
}
7、调用接口查看结果
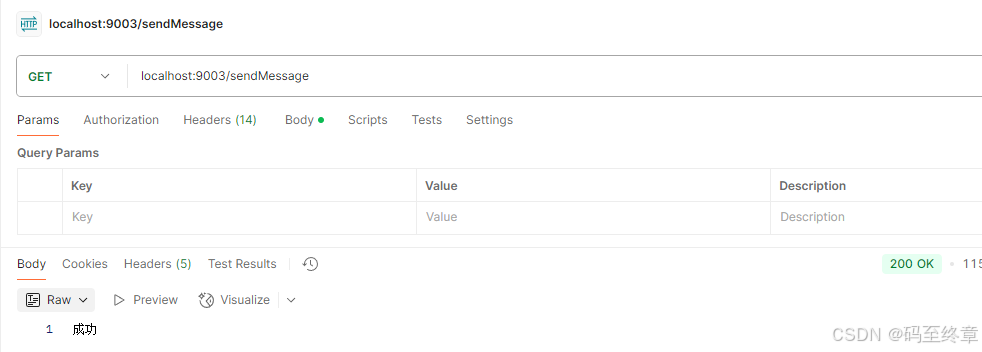
可以看到能正常收到消息
Q&A
1、如果执行docker编排文件报错docker-compose: command not found,说明没有安装docker-compose,可以按如下步骤进行安装
#1、下载安装文件
sudo curl -L "https://github.com/docker/compose/releases/download/1.29.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
#2、赋予执行权限
sudo chmod +x /usr/local/bin/docker-compose
#3、创建软连接
sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
#4、测试,能出现版本号说明可以了
docker-compose --version


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)