hadoop伪分布部署
hadoop伪分布部署
目录
一、上传安装包
利用Moba工具将jdk1.8.0_131的安装包以及hadoop-2.7.7 的安装包上传至虚拟机中/opt/environment的目录下,解压jdk和hadoop的安装包:
tar -zxvf jdk-8u171-linux-x64.tar.gz
tar -zxvf hadoop-2.7.3.tar.gz
二、安装jdk
编辑/etc/profile文件
vi /etc/profile
添加以下内容:
export JAVA_HOME=/opt/environment/jdk1.8.0_171
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
让刚刚配置的环境变量生效
source /etc/profile
验证jdk是否安装成功:
java -version

说明jdk安装成功!
三、配置主机名与ip地址的映射关系
虚拟机中配置:
vi /etc/hosts

添加虚拟机的ip和主机名(master是我的主机名)
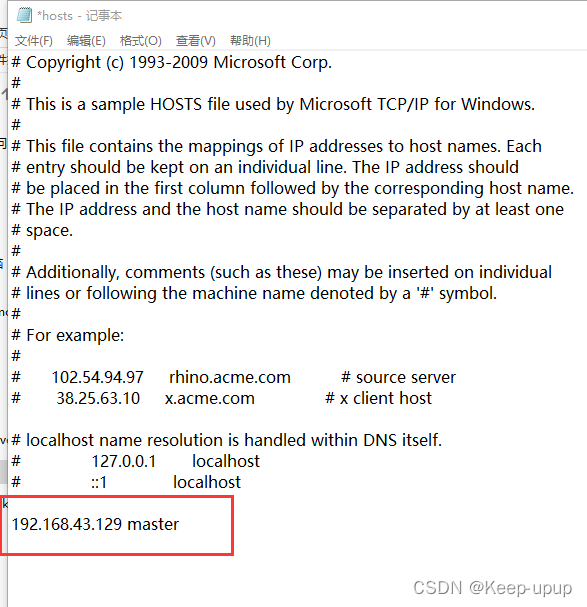
Windows中配置:
找到C:\Windows\System32\drivers\etc 下的hosts文件,添加完成记得保存此文件!
四、关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
五、设置免密登录
ssh-keygen -t rsa (执行命令后,只需敲三次回车键)
cd ~/.ssh/
ssh-copy-id -i id_rsa.pub root@master
六 、安装hadoop
- 配置环境变量
vi /etc/profile- 添加以下内容:
export HADOOP_HOME=/opt/environment/jdk1.8.0_171
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin- 使环境变量生效
source /etc/profile- 验证hadoop是否生效可以使用
hdfs dfs -ls 命令出现hadoop相关说明生效了
接下来就是对/opt/environment/hadoop-2.7.3/etc/hadoop下的文件进行配置
1、vi hadoop-env.sh 将jdk的路径添加进去
export JAVA_HOME=/opt/environment/jdk1.8.0_171
2、 vi hdfs-site.xml 将以下内容添加到<configuration></configuration>之间
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
3、vi core-site.xml 将以下内容添加到<configuration></configuration>之间(master是我的主机名,你可以更改为你的主机名再复制)
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/training/hadoop-2.7.3/tmp</value>
</property>
4、先将 mapred-site.xml.template 复制一份并改名为 mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
再对文件进行编辑 vi mapred-site.xml 将以下内容添加到<configuration></configuration>之间,master是我的主机名,你可以更改为你的主机名再复制)
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
5、vi yarn-site.xml 将以下内容添加到<configuration></configuration>之间,master是我的主机名,你可以更改为你的主机名再复制)
<!--Yarn的主节点RM的位置-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property><!--MapReduce运行方式:shuffle洗牌-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!--配置Log Server -->
<property>
<name>yarn.log.server.url</name>
<value>http://master:19888/jobhistory/logs</value>
</property>
文件配置完毕,下一步是格式化HDFS
hdfs namenode -format
如格式化成功,在打印出来的日志可以看到如下信息:Storage directory/opt/environment/jdk1.8.0_171/tmp/dfs/name has been successfully formatted.
启动hdfs 环境
启动服务:start-all.sh
启动mr历史服务: mr-jobhistory-daemon.sh start historyserver
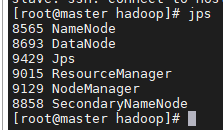
最后进行验证:
jps查看hadoop进程:
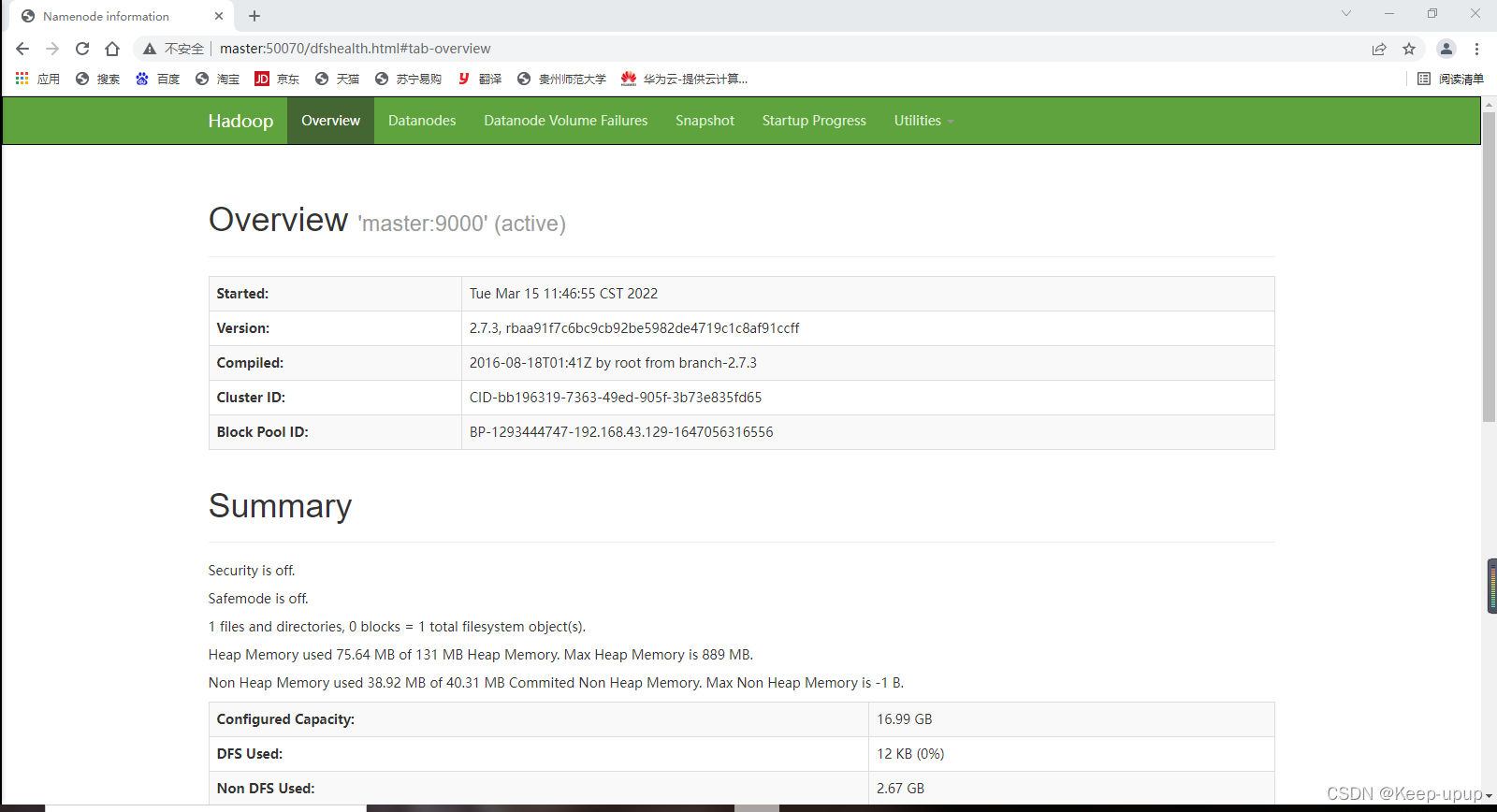
在浏览器中输入192.168.43.129:50070(或者把ip换成主机名)访问HDFS可以看到:
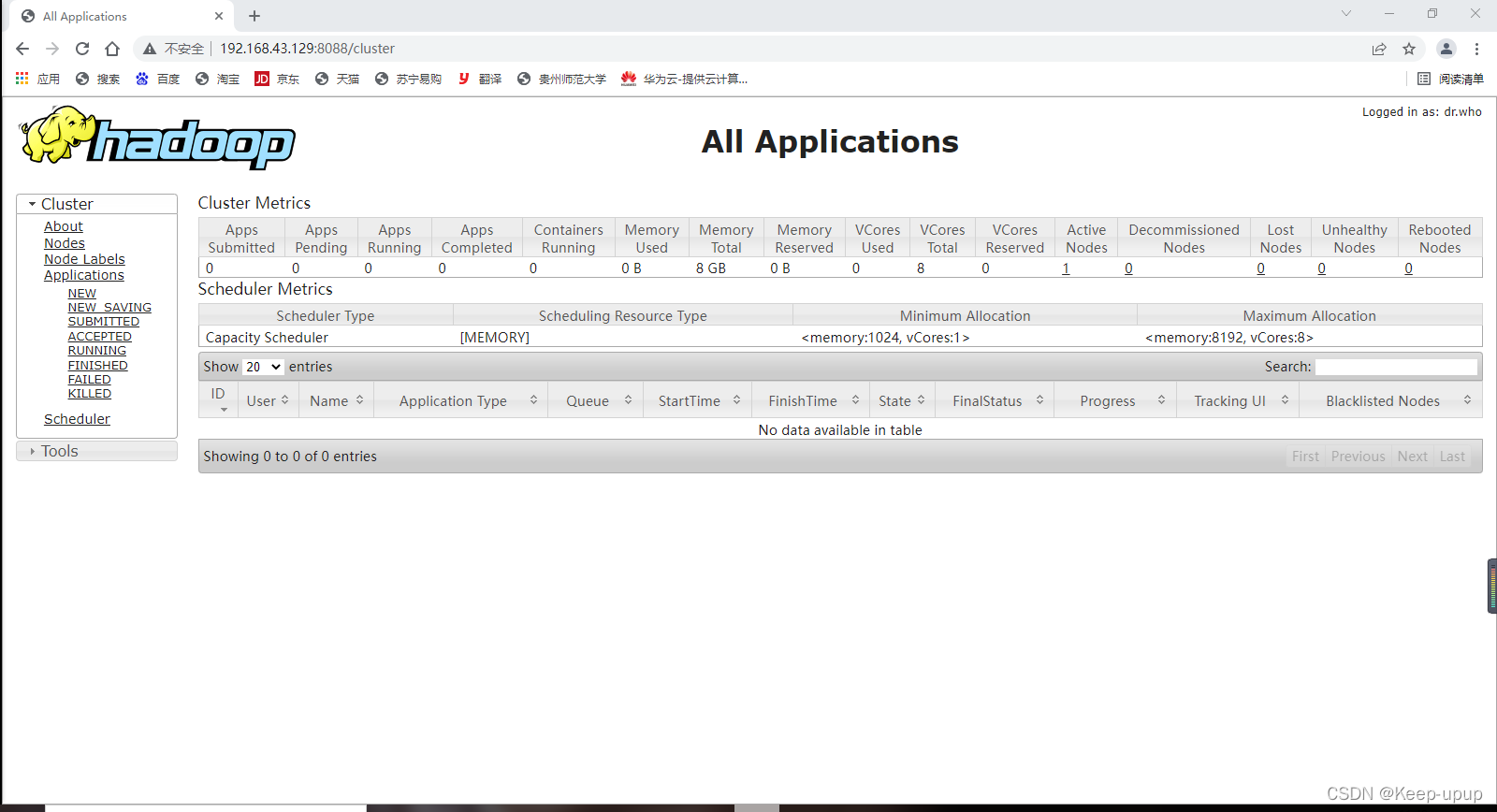
访问yarn输入:master:8088
到此,Hadoop伪分布模式就部署完毕了!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)