tensorflow初试:mnist全连接分类
个人博客:http://www.chenjianqu.com/原文链接:http://www.chenjianqu.com/show-50.html其实以前也学过一点tensorflow,但是因为后来一直没怎么用,所以也忘的差不多。但是做算法的tf还是要会的,因此本文通过经典问题mnist手写数据集的分类来复习一下tensorflow的基本用法。tensorflow...
个人博客:http://www.chenjianqu.com/
原文链接:http://www.chenjianqu.com/show-50.html
其实以前也学过一点tensorflow,但是因为后来一直没怎么用,所以也忘的差不多。但是做算法的tf还是要会的,因此本文通过经典问题mnist手写数据集的分类来复习一下tensorflow的基本用法。
tensorflow和keras
tensorflow是Google开源的基于数据流图的机器学习框架,支持python和c++程序开发语言。轰动一时的AlphaGo就是使用tensorflow进行训练的,其命名基于工作原理,tensor 意为张量(即多维数组),flow 意为流动。即多维数组从数据流图一端流动到另一端。
Keras是基于TensorFlow和Theano的深度学习库,是由纯python编写而成的高层神经网络API,也仅支持python开发。它是为了支持快速实践而对tensorflow或者Theano的再次封装,让我们可以不用关注过多的底层细节,能够把想法快速转换为结果。
mnist数据集
MNIST 数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员. 测试集(test set) 也是同样比例的手写数字数据。该数据集包含了60000张的训练图像和10000张的测试图像。
代码实现
1.数据预处理
import numpy as np
import tensorflow as tf
import os
mnistDataset=np.load('data/mnist.npz')
train_images,train_labels=mnistDataset['x_train'],mnistDataset['y_train']
test_images,test_labels=mnistDataset['x_test'],mnistDataset['y_test']
#转换改变数据形状和数据类型(将uint8变为float32)
train_images=train_images.reshape(-1,784).astype('float32')/255.0
test_images=test_images.reshape(-1,784).astype('float32')/255.0
#对将数字标签one-hot
train_labels_onehot=np.zeros((train_labels.shape[0],10))
test_labels_onehot=np.zeros((test_labels.shape[0],10))
for i,label in enumerate(train_labels):
train_labels_onehot[i,label]=1
for i,label in enumerate(test_labels):
test_labels_onehot[i,label]=1
print(train_images.shape)
print(train_labels_onehot.shape)
print(test_images.shape)
print(test_labels_onehot.shape)2.定义前向传播网络
在tensorflow中,用张量表示数据,用计算图搭建神经网络,用会话执行计算图,优化线上的权重(参数),得到模型。计算图中的节点表示张量,有向边表示张量计算。为了进行计算, 图必须在session里被启动。session将图的op(图中的节点被称之为 op,operation的缩写)分发到诸如 CPU 或 GPU之类的设备 上, 同时提供执行op的方法。这些方法执行后, 将产生的 tensor 返回。
在TensorFlow中,变量(Variable)是特殊的张量(Tensor),它的值可以是一个任何类型和形状的张量。与其他张量不同,变量存在于单个 session.run 调用的上下文之外,也就是说,变量存储的是持久张量,当训练模型时,用变量来存储和更新参数。
函数:tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None,name=None),从截断的正态分布中输出随机值。 shape表示生成张量的维度,mean是均值,stddev是标准差。这个函数产生正太分布,均值和标准差自己设定。这是一个截断的产生正太分布的函数,就是说产生正太分布的值如果与均值的差值大于两倍的标准差,那就重新生成。和一般的正太分布的产生随机数据比起来,这个函数产生的随机数与均值的差距不会超过两倍的标准差,但是一般的别的函数是可能的。
INPUT_NODE=784
OUTPUT_NODE=10
LAYER1_NODE=500
#定义权重函数,参数:权重大小,L2正则化系数,权重变量的名字
def get_weight(shape,regularizer,name=None):
#定义变量,变量的初始化方式为截断正态分布
w=tf.Variable(tf.truncated_normal(shape,stddev=0.1),name=name)
if(regularizer!=None):
#定义了该权重矩阵的l2正则化项,并把该项添加到集合中,反向传播的时候用到
tf.add_to_collection('losses',tf.contrib.layers.l2_regularizer(regularizer)(w))
return w
#定义权重
def get_bias(shape,name=None):
#定义变量,变量初始化方法为常量0
b=tf.Variable(tf.zeros(shape),name=name)
return b
#定义前向传播网络,参数:输入张量,L2正则化系数
def forward(x,regularizer):
w1=get_weight([INPUT_NODE,LAYER1_NODE],regularizer,'w1')
b1=get_bias([LAYER1_NODE],'b1')
#定义激活函数为relu,matmul为张量点积
y1=tf.nn.relu(tf.matmul(x,w1)+b1)
w2=get_weight([LAYER1_NODE,OUTPUT_NODE],regularizer,'w2')
b2=get_bias([OUTPUT_NODE],'b2')
#由于输出 y 要经过 softmax 函数,使其符合概率分布,故输出 y 不经过 relu 函数。
y=tf.matmul(y1,w2)+b2
return y3.定义反向传播并通过session训练模型
学习率(learning rate):表示了每次参数更新的幅度大小。学习率过大,会导致待优化的参数在最
小值附近波动,不收敛;学习率过小,会导致待优化的参数收敛缓慢。在训练过程中,参数的更新向着损失函数梯度下降的方向。参数的更新公式为:
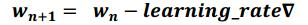
指数衰减学习率:学习率随着训练轮数变化而动态更新。计算公式:
decayed_learning_rate = learning_rate * decay_rate ^ (global_step / decay_steps)
用 Tensorflow 的函数表示为:
global_step = tf.Variable(0, trainable=False)
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
LEARNING_RATE_STEP,
LEARNING_RATE_DECAY,
staircase=True/False
)
其中:
LEARNING_RATE_BASE 为学习率初始值,
LEARNING_RATE_DECAY 为学习率衰减率,
global_step 记录了当前训练轮数,为不可训练型参数。
LEARNING_RATE_STEP表示学习率更新频率为输入数据集总样本数除以每次喂入样本数。
若 staircase 设置为 True 时,表示global_step / LEARNING_RATE_STEP取整数,学习率阶梯型衰减;若 staircase 设置为 false 时,学习率会是一条平滑下降的曲线。
直观解释:假设给定初始学习率learning_rate为0.1,学习率衰减率为0.1,decay_steps为10000。
则随着迭代次数从1到10000,当前的学习率decayed_learning_rate慢慢的从0.1降低为0.1*0.1=0.01,
当迭代次数到20000,当前的学习率慢慢的从0.01降低为0.1*0.1^2=0.001,以此类推。
也就是说每10000次迭代,学习率衰减为前10000次的十分之一,该衰减是连续的,这是在staircase为False的情况下。
如果staircase为True,则global_step / decay_steps始终取整数,也就是说衰减是突变的,每decay_steps次变化一次,变化曲线是阶梯状。滑动平均:滑动平均会为目标变量维护一个影子变量,影子变量不影响原变量的更新维护,但是在测试或者实际预测过程中(非训练时),使用影子变量代替原变量。
影子 = 衰减率 * 影子 +(1 - 衰减率) * 参数
衰减率=min(MOVING_AVERAGE_DECAY, (1 + global_step) / (10 + global_step))
MOVING_AVERAGE_DECAY 表示滑动平均衰减率,一般会赋接近 1 的值, global_step 表示当前训练了多少轮。相关代码:
滑动平均求解对象初始化
ema = tf.train.ExponentialMovingAverage(decay,num_updates)
添加/更新变量,添加目标变量,为之维护影子变量。注意维护不是自动的,需要每轮训练中运行此句,所以一般都会使用tf.control_dependencies使之和train_op绑定,以至于每次train_op都会更新影子变量
ema.apply([var0, var1])
函数实现把所有待训练参数汇总为列表。
tf.trainable_variables()
获取影子变量值,这一步不需要定义图中,从影子变量集合中提取目标值
sess.run(ema.average([var0, var1]))控制依赖:tf.control_ dependencies(control_ inputs),此函数指定某些操作执行的依赖关系,返回一个控制依赖的上下文管理器,使用with关键字可以让在这个上下文环境中的操作都在control_ inputs 执行。
with tf.control_ dependencies([a, bI):
c=....
d=...
在执行完a,b操作之后,才能执行c,d操作。意思就是C,d操作依赖a,b操作
with tf.control_ dependencies([train step, variable_ averages_ opl):
train op = tf.no oP (name='train')
tf.no_ op()表示执行完 train_ step, variable_ averages_ op操作之后什么都不做交叉熵(Cross Entropy):表示两个概率分布之间的距离。交叉熵越大,两个概率分布距离越远,两个概率分布越相异;交叉熵越小,两个概率分布距离越近,两个概率分布越相似。交叉熵计算公式: H(y_ , y)=-Ey_ *log y
用Tensorflow函数表示为:ce= -tf. reduce_ mean(y_ * tf. log(tf. clip_ by_value(y, 1e-12, 1. 0)))
下面继续写代码:
定义一些常量
BATCH_SIZE=200 #每轮的样本数
LEARNING_RATE_BASE=0.1 #基础学习率
LEARNING_RATE_DECAY=0.99 #学习率衰减率
REGULARIZER=0.0001 #正则化系数
STEPS=50000 #训练轮数
MOVING_AVERAGE_DECAY=0.99 #滑动平均衰减率
MODEL_SAVE_PATH='./model/' #模型保存路径
MODEL_NAME='mnist_model' #模型名称
data_len=train_images.shape[0] #训练数据集长度定义反向传播并通过session训练模型
def backward(X,Y_):
#定义输入占位符 占位符就是指暂时没用任何值的符号,待用户输入。只在运算中做一个变量的表示。类似于方程中的未知数。
x=tf.placeholder(tf.float32,[None,INPUT_NODE])
#定义标签占位符
y_=tf.placeholder(tf.float32,[None,OUTPUT_NODE])
#构建前向传播网络
y=forward(x,REGULARIZER)
#定义一个用于存放步数的全局变量
global_step=tf.Variable(0,trainable=False)
#将前向网络的输出softmax并计算交叉熵
ce=tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,labels=tf.argmax(y_,1))
cem=tf.reduce_mean(ce) #求所有样本的平均交叉熵
#定义loss,包括交叉熵和正则项,tf.add_n()即将列表中的各项求和
loss=cem+tf.add_n(tf.get_collection('losses'))
#定义指数衰减的学习率,
learning_rate=tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
data_len/BATCH_SIZE,
LEARNING_RATE_DECAY,
staircase=True
)
#使用梯度下降优化参数
train_step=tf.train.GradientDescentOptimizer(learning_rate).minimize(loss,global_step=global_step)
#定义滑动平均求解对象
ema=tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY,global_step)
#apply()添加变量,trainable_variables()把所有待训练参数汇总为列表。
ema_op=ema.apply(tf.trainable_variables())
#设置控制依赖,先更新参数,再更新影子变量
with tf.control_dependencies([train_step,ema_op]):
train_op=tf.no_op(name='train')
#初始化保存对象,在反向传播过程中,一般会间隔一定轮数保存一次神经网络模型, 并产生三个文件(保存当前图结构的.meta 文件、 保存当前参数名的.index 文件、 保存当前参数的.data 文件)
#saver=tf.train.Saver(max_to_keep=1)默认保存最近5次
saver=tf.train.Saver()
#打开会话管理器
with tf.Session() as sess:
#初始化所有待训练的参数
init_op=tf.global_variables_initializer()
sess.run(init_op)
#断点续训
ckpt=tf.train.get_checkpoint_state(MODEL_SAVE_PATH)
if(ckpt and ckpt.model_checkpoint_path):
saver.restore(sess,ckpt.model_checkpoint_path)
#训练网络
for i in range(STEPS):
start=(i*BATCH_SIZE)%(data_len-BATCH_SIZE)
end=start+BATCH_SIZE
_,loss_value,step=sess.run([train_op,loss,global_step],feed_dict={x:X[start:end],y_:Y_[start:end]})
if(i%1000==0):
print('%d %g'%(step,loss_value))
saver.save(sess,os.path.join(MODEL_SAVE_PATH,MODEL_NAME),global_step=global_step)
backward(train_images,train_labels_onehot)4.测试模型
加载训练好的模型,使用测试数据集对模型进行测试
def test(X,Y_):
x=tf.placeholder(tf.float32,[None,INPUT_NODE])
y_=tf.placeholder(tf.float32,[None,OUTPUT_NODE])
y=forward(x,None)
ema=tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY)
#变量的滑动平均值都是由影子变量所维护的,如果你想要获取变量的滑动平均值需要获取的是影子变量而不是变量本身。
#通过使用variables_to_restore函数,可以使在加载模型的时候将影子变量直接映射到变量的本身,所以我们在获取变量的滑动平均值的时候只需要获取到变量的本身值而不需要去获取影子变量。
'''
variables_to_restore:获取变量名与其对应的影子变量的MAP,例如:
{'Variable_3/ExponentialMovingAverage': <tf.Variable 'Variable_3:0' shape=(10,) dtype=float32_ref>,
'Variable/ExponentialMovingAverage': <tf.Variable 'Variable:0' shape=(784, 500) dtype=float32_ref>}
global_step: global_step
'''
ema_restore=ema.variables_to_restore()
print(ema_restore)
saver=tf.train.Saver(ema_restore)
#argmax(y,1)从每行中获得最大值的下标
#equal若相关参数相等则返回true
#correct_prediction是一个bool tensor
correct_prediction=tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
#cast将bool转换为float
#计算均值就是精度
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
print(Y_.shape)
print(Y_.dtype)
with tf.Session() as sess:
#该函数返回的是checkpoint文件CheckpointState proto类型的内容,其中有model_checkpoint_path和all_model_checkpoint_paths两个属性。
#其中model_checkpoint_path保存了最新的tensorflow模型文件的文件名,all_model_checkpoint_paths则有未被删除的所有tensorflow模型文件的文件名。
ckpt=tf.train.get_checkpoint_state(MODEL_SAVE_PATH)
if(ckpt and ckpt.model_checkpoint_path):
#恢复sess
saver.restore(sess,ckpt.model_checkpoint_path)
#从文件名中恢复轮数
global_step=ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
#计算精度
accuracy_score=sess.run(accuracy,feed_dict={x:X,y_:Y_})
print('%s %g'%(global_step,accuracy_score))
test(test_images,test_labels_onehot)最终得到的测试精度是0.9814,对于一个全连接网络来说还是不错的。
参考文献
[1]「Jack LDZ」.tensorflow简介以及与Keras的关系、常用机器学习框架一览.https://blog.csdn.net/li528405176/article/details/83857286. 2018-11-08

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)