卷积神经网络【图片分类】
本文是对卷积神经网络的一次学习,从图片分类入手,讲解了整个流程,对几个经典模型进行了解与分析
本文章的内容和知识为作者学习期间总结且部分内容借助AI理解,可能存在一定错误与误区,期待各位读者指正。
本文章中的部分例子仅用于生动解释相关概念,切勿结合实际过度解读。
语雀链接:《卷积神经网络【图片分类】》
部分内容来源:B站:李哥考研
本章内容已经更新完成,如有不足之处,不妨评论区一叙
分类
分类与回归
现实中有很多问题不是预测问题,比如当你在楼下玩泥巴的时候,突然发现一只奇特生物,你根据它的外貌特征,判断他是猫还是狗。打游戏时,观察队友的战绩,判断他是高手还是菜鸟。
与之前学习到的回归任务不同的是,分类的输出是离散的类别标签(“猫”“狗”),而不是具体的数值。如下图所示,回归任务的模型结构会拟合数据的整体趋势以预测输出值,而分类任务的模型是为了将样本划分为不同的类别区域。
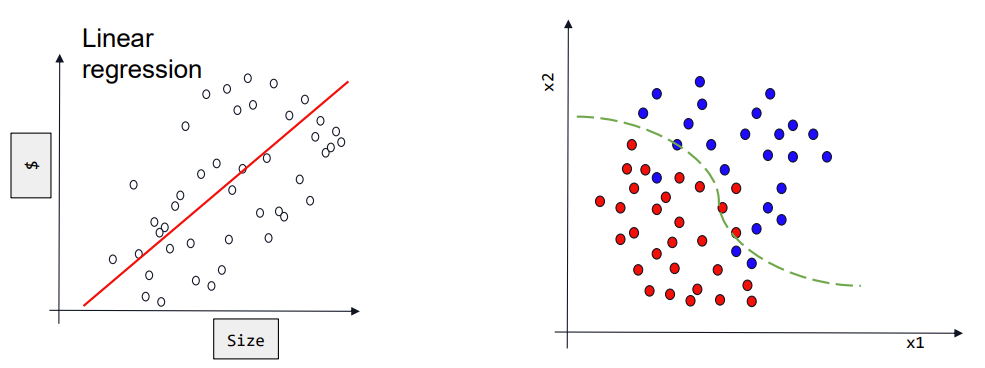
分类和回归任务的目的不同,因此我们应该合理设置输出方式,并利用合适的分类方法完成样本的分类。
如果是二分类问题,模型通常会输出一个概率值,我们可以使用基于阈值的方法,大于阈值则为正类,小于阈值则为负类。假设在一个垃圾邮件分类器中,模型对某封邮件预测为垃圾邮件的概率是 0.7,如果阈值是 0.5,那么这封邮件就会被分类为垃圾邮件。
如果是多分类问题,模型可能会输出每个类别的概率,我们可以选择概率最高的类别作为预测结果。例如在一个图像分类任务中,模型对一张图片输出的类别概率分别是:猫(0.3)、狗(0.6)、鸟(0.1),那么这张图片就会被分类为狗。
当然还有许多其他的分类方法,在本章节中便不再展开讨论
独热编码
输出值有了,哪预测值应该怎么表示呢?还记得我们之前提到的独热编码吗?对于一个具有n个不同类别的分类变量,独热编码会将该变量转换为一个长度为n的向量。在这个向量中,只有一个元素为1,其余元素均为0,其中所在的位置对应于该样本所属的类别。
例如,在颜色分类中,有红、绿、蓝三种颜色。独热编码将红、绿、蓝分别表示为 [ 1 0 0 ] \begin{bmatrix} 1 \\ 0\\ 0 \end{bmatrix}
100
、 [ 0 1 0 ] \begin{bmatrix} 0 \\ 1\\ 0 \end{bmatrix}
010
、 [ 0 0 1 ] \begin{bmatrix} 0 \\ 0\\ 1 \end{bmatrix}
001
能够准确地表示类别信息。向量长度就是类别的数量,如果长度为n,那模型就只能辨识出这n种类别。我们就这样用向量将预测值和真实值表示出来了
卷积神经网络
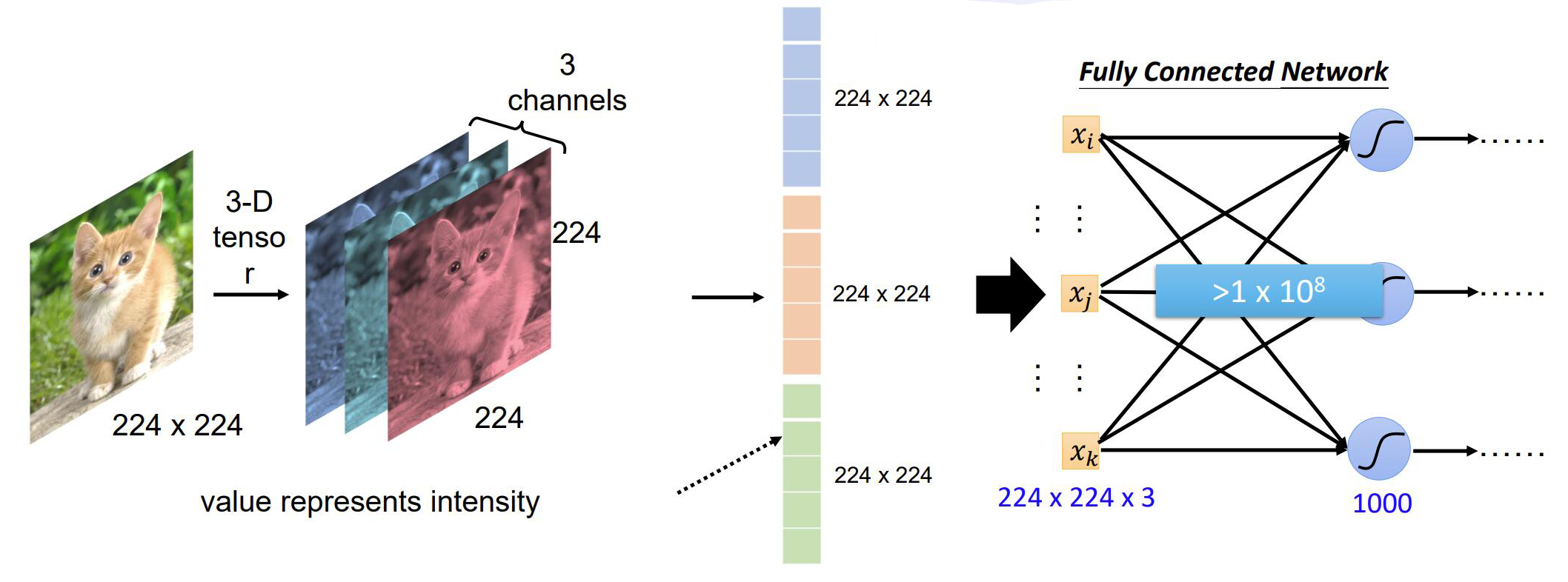
输入图片,我们通常将图片设置为224*244像素大小,并且该图像有 3 个通道(RGB 三色通道),并对应了一个3*244*244大小的矩阵,矩阵中每个值代表该位置像素的强度(颜色值)。得到输入值后如何变为类别的数量呢,毕竟输入有3*244*244个数值,而我们仅有着1000个类别。如果直接使用全连接的方式,就会产生相当多的参数,而且容易出现过拟合的情况。因此我们放弃使用这种方法,并引入一种新的神经网络——卷积神经网络。
卷积核与特征图
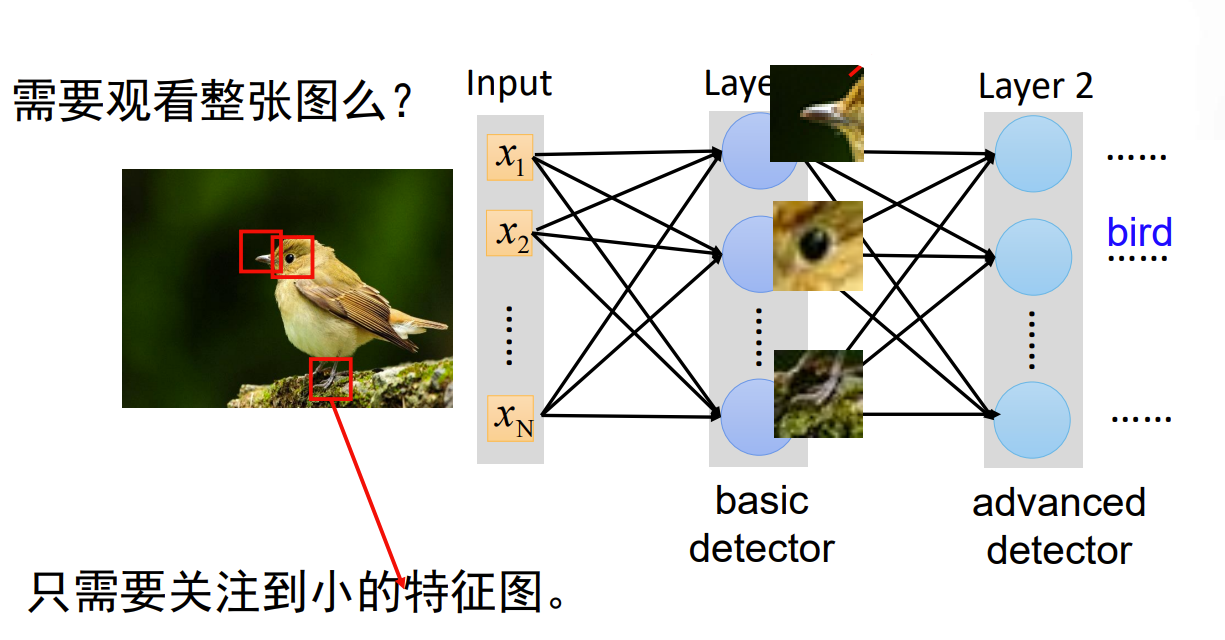
我们来举一个简单的例子,如果我们想知道大图中是否存在小图,应该怎么办呢?对于人来说可以用小图从第一行开始滑动对比,那这种方式应该如何通过机器实现呢?
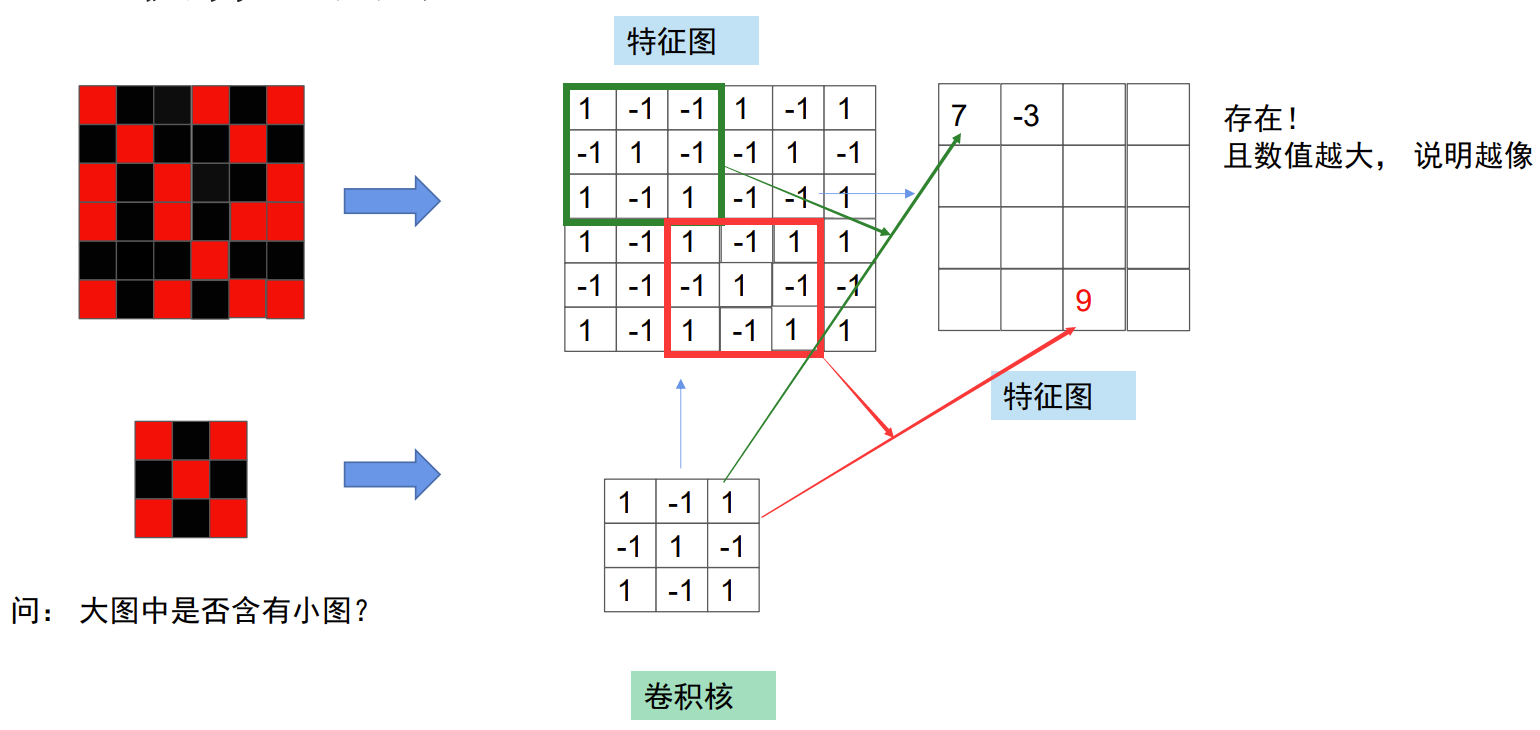
我们先将图用矩阵表示,即红色表示为1,黑色表示为-1,这样组成了一个6*6的矩阵和一个3*3的矩阵,这个大矩阵就称之为特征图,小矩阵称为卷积核。我们从大矩阵的绿色矩阵开始对比计算,将绿色矩阵和卷积核上对应数字相乘并加和,得到结果7,并将得到的值写到新的矩阵上。这个数值越大就说明二者越相像,最后根据特征图来判断结果。这个对卷积层进行的处理就叫做卷积运算
让我们继续看一些例子
当我们判断图片上是否是一只小鸟的时候,我们不必观看整张图片,只需关注到小的特点(特征图),如鸟喙,眼睛,爪子等,便可以判断出这是鸟了。如果我们把图片看作是特征图,那么鸟喙,眼睛,爪子这些特点就是卷积核了。
而由于图片表示为三层244*244的矩阵,因此,卷积的过程也是三层同时进行卷积,不是3*3组数进行计算,而是3*3*3组数进行计算,
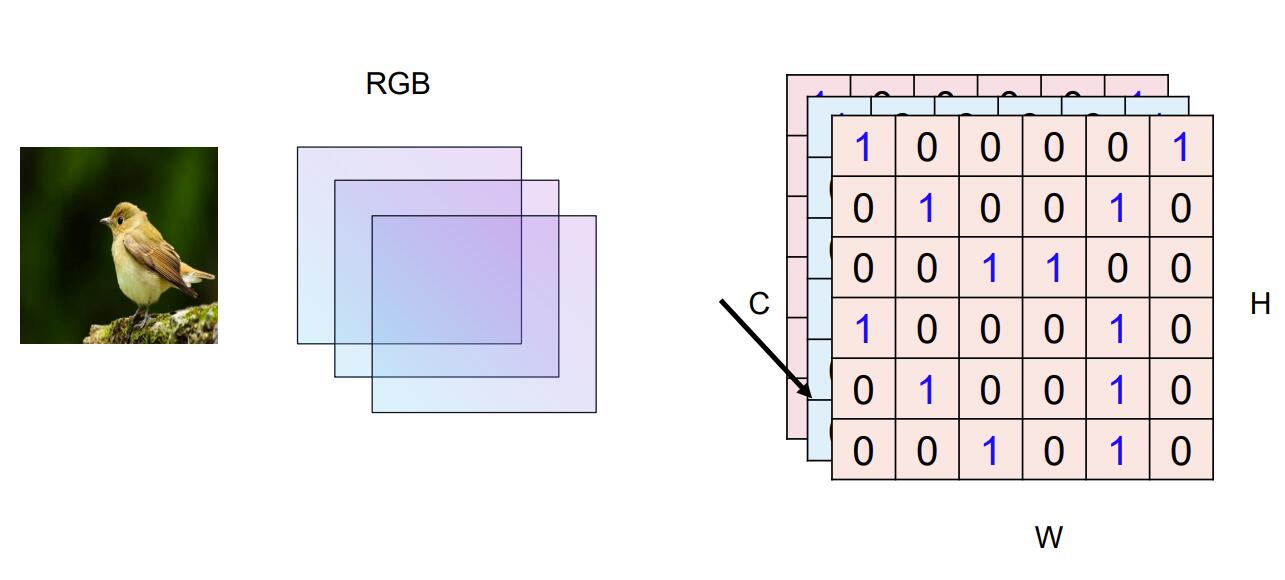
卷积核是一个小的权重矩阵。对于 RGB 图像,卷积核的维度可能是 3x3x3。卷积核的主要作用是提取输入数据中的特征。
在卷积神经网络中,有时将卷积层的输入输出数据称为特征图(feature map)。其中,卷积层的输入数据称为输入特征图(input feature map),输出 数据称为输出特征图(output feature map)
零填充(Zero-padding)
随着每次卷积的进行,特征图的尺寸不断减小,那我们应该如何保持大小不变呢?我们可以使用零填充(Zero-padding)以保持特征图的尺寸。虽然卷积减小,零填充维持,但并不相悖,详细解释请看文章最后的补充。
零填充是在卷积神经网络使用的一种技术。在进行卷积操作时,在输入数据的边缘填充零值元素。能够在深层网络中保持特征图的尺寸,这对于构建深层网络很重要。如果特征图尺寸过小,可能会丢失过多的信息,影响模型的性能,也可以减少边缘信息在网络传递过程中可能会被较快地丢失的情况。
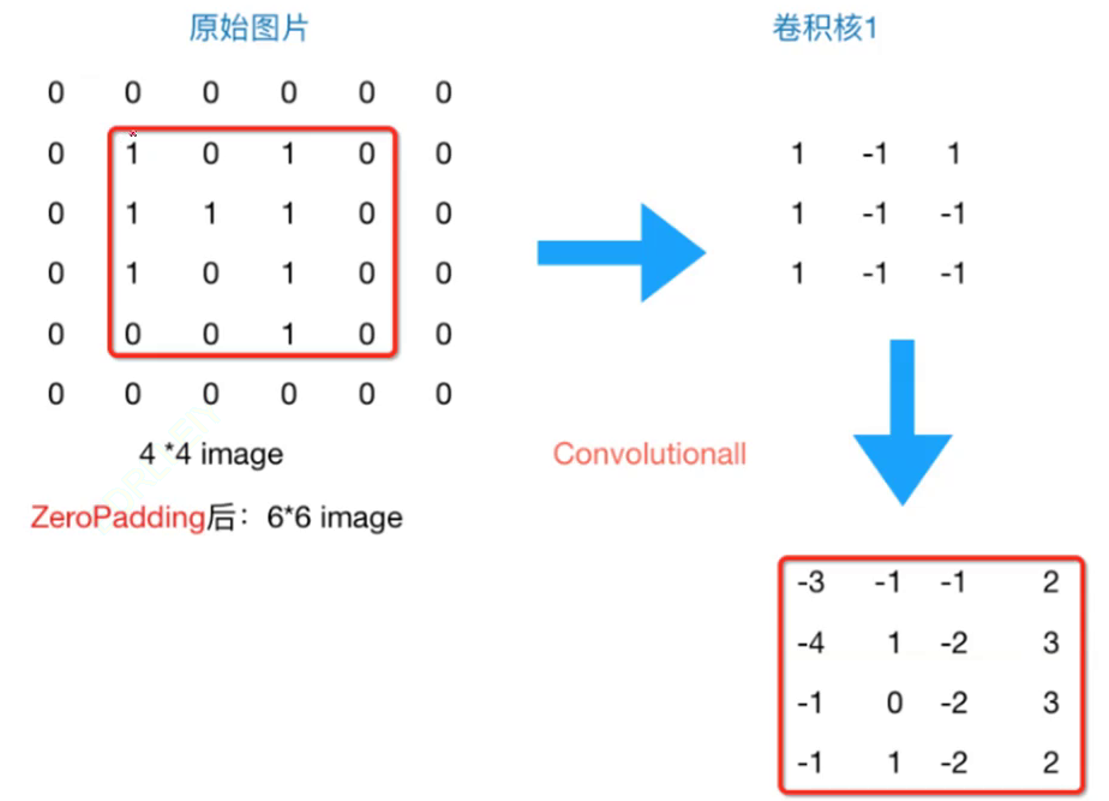
如图所示,原本4*4的特征图,在经过Padding(1)后,变为6*6的特征图,此时经过卷积操作后,得到的新特征图,仍为4*4大小
更大的卷积核和更多的卷积核层数
更大的卷积核,让我们从拥有更大的感受野,如同使用广角镜头,能够捕获更多的景色;会让我们提取特征更高效,如同用大网捕鱼;对噪声的健壮性更好,如同用更大的盾牌化解攻击。
更多的卷积核层数,意味着网络能够提取到更抽象、更高级的特征。
每个卷积核都会对特征图进行卷积操作并得到一个新的特征图,如果此时我们想继续进行卷积操作,那么我们可以将这5张特征图叠到一起,并再次进行卷积,但原本的卷积核为三维,显然新特征图的维度不符合,我们新的卷积核的维度应该与特征图的维度匹配(五维)。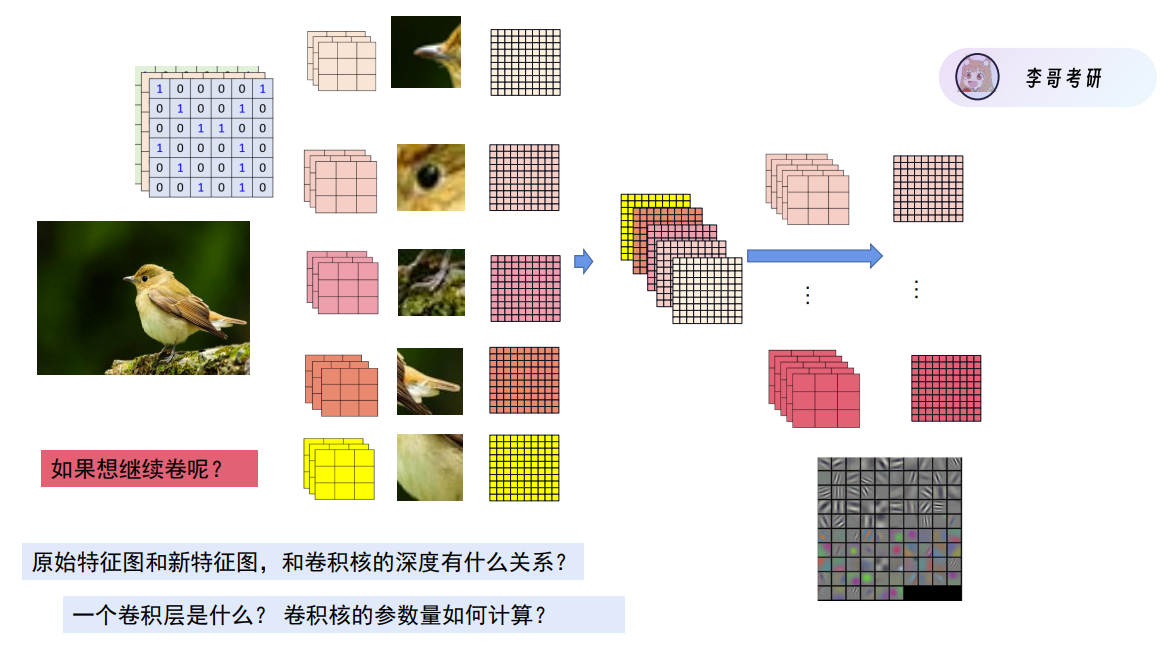
1、原始特征图和卷积核的深度有什么关系?
在卷积神经网络中,卷积核的深度是指卷积核在通道方向上的维度,深度为3=维度为3。
原始特征图有多深,卷积核必须有同样深度。否则没法进行卷积操作。
新的特征图的深度与卷积核的数量有关,每个卷积核卷积产生一个特征图,新的特征图是由这些产生的特征图叠加而来。
2、一个卷积层是什么
一个卷积层(一层卷积),代表着卷积核对旧特征图进行卷积操作,得到新特征图的过程。以上图为例,上图共两层卷积层,小箭头左侧部分为一层,右侧部分为一层。
3、卷积层的参数量如何计算
计算卷积核的参数量,只需要关注卷积核的数量(5)和大小(3*3*3),上图的卷积层·参数为5*3*3*3(忽略bias)
步长&池化
在填充后,当我们需要对特征图进行降维时(让特征图变小),仅依靠卷积每次减少几行,这种方式可行吗?不太可行,这实在是太慢,而且再卷积的过程中会产生大量参数,因此我们需要对数据进行降采样(Subsampling),指通过某种方式减少数据的样本数量,从而降低数据的维度。在图像中,这通常表现为减少图像的像素数量,使得图像尺寸变小。间隔采样和池化是降采样中的两个方法。
1、间隔采样(Strided Sampling)
间隔采样指按照一定的间隔从原始数据中选取样本。而步长(stride)是一个重要的参数。它指的是卷积核或者池化窗口在每次滑动时移动的像素数,若步长为2,则每间隔2个单位,进行一次取样。
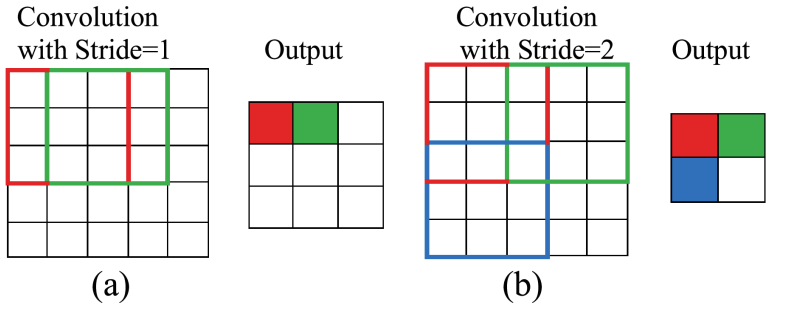
卷积尺寸计算公式: O = ( I − K + 2 P ) / S + 1 O = (I-K+2P)/S + 1 O=(I−K+2P)/S+1(忽略了bias)
其中 O O O代表输出特征图的尺寸, I I I代表输入特征图的尺寸, K K K代表卷积核的大小, P P P代表填充的大小, S S S代表步长。
2、池化(Pooling)
最大池化(Max Pooling)是一种下采样操作。它通过在输入的特征图(例如在卷积神经网络中的卷积层输出)上滑动一个固定大小的池化窗口(如 2×2、3×3 等),然后在每个窗口内选取最大值作为输出。
平均池化(Average Pooling)是一种下采样操作。它也是通过在输入特征图上滑动池化窗口,但是它在每个窗口内计算所有元素的平均值作为输出。
自适应池化(Adaptive Pooling)包括自适应最大池化和自适应平均池化,它的关键在于能够根据输入特征图的大小自动调整池化策略,以输出指定大小的特征图。
Pool(2,1)就代表,池化窗口大小为2*2,步长为1
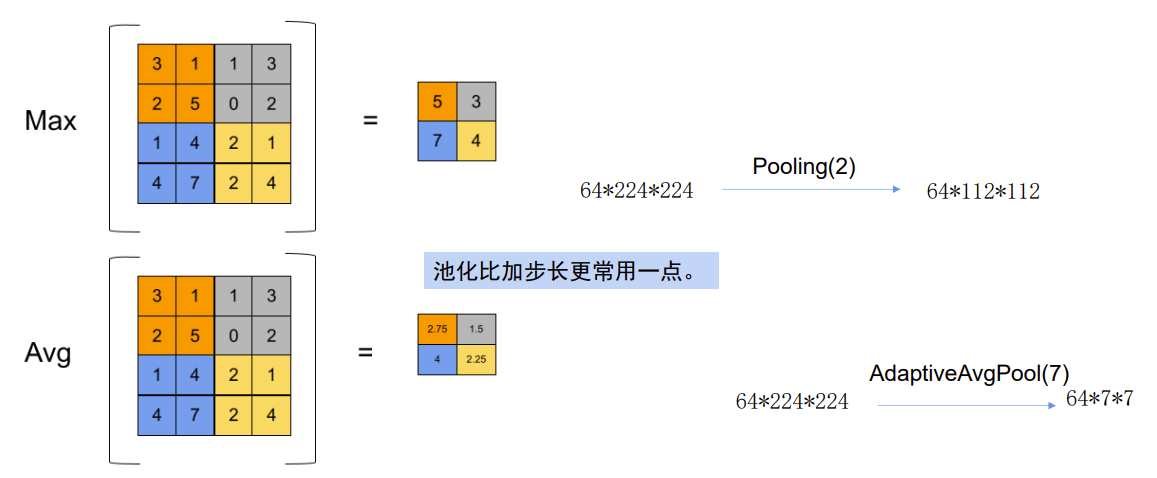
在神经网络中,尤其是深度神经网络,数据量的减少意味着后续层的计算量大幅降低,可以显著节省计算资源,同时减少数据维度在一定程度上有助于防止过拟合。
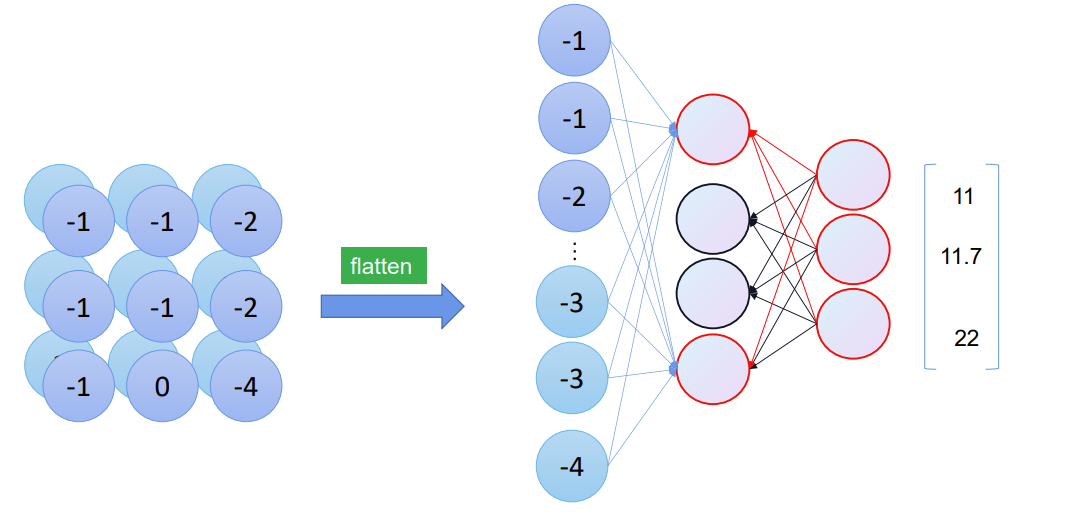
卷积到全连接
这种多维的矩阵,如何才能卷积,卷成几个类别呢?我们可以将他拉直,最初由于特征图太大,参数太多,需要进行卷积。将其拉直后,再进行全连接。
交叉熵损失(CrossEntropy Loss)
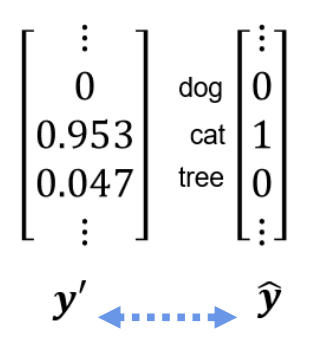
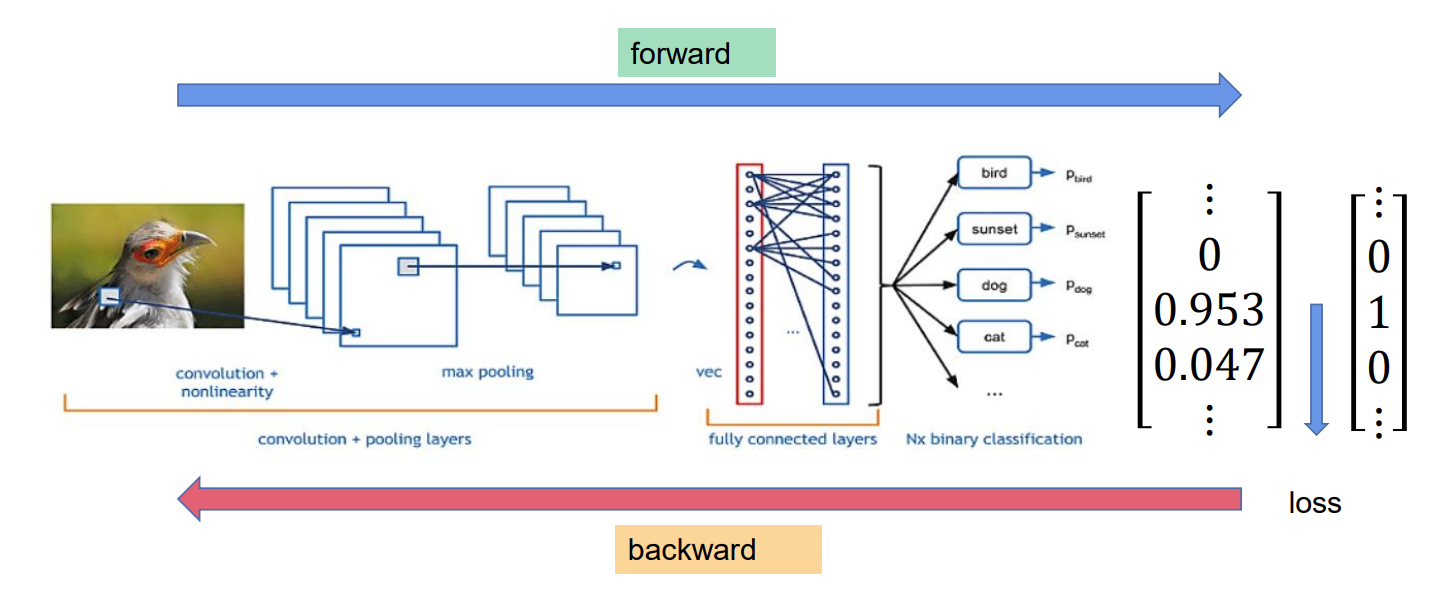
整个流程已经打通了,接下来计算Loss。在计算Loss之前,我们先对输出值进行一次转换。
我们的真实值,代表的是概率,即是cat的概率为1,而预测值的数字并非如此,我们需要将其转换成概率的形式,此时我们借助Softmax函数,我们一般将softmax的输出视作模型预测的概率分布。
S o f t m a x ( y ) = y i = e y i ∑ j = 1 n e y i Softmax(y)=y_{i} = \frac{e^{y_{i}}}{\sum_{j=1}^{n}e^{y_{i}}} Softmax(y)=yi=∑j=1neyieyi
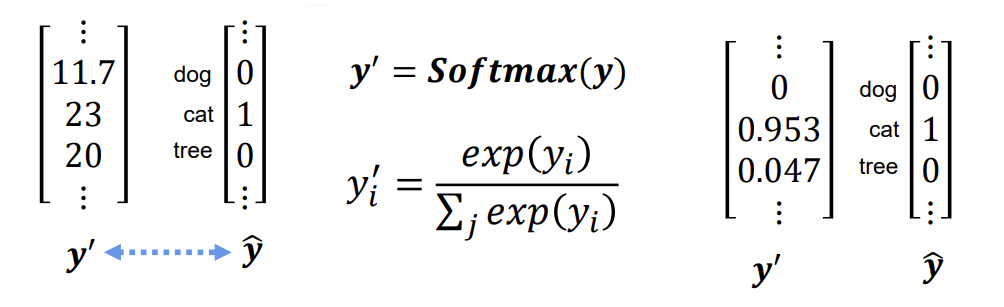
这个公式的核心是通过指数函数将输入值放大,然后通过除以所有指数值的和来进行归一化,使得输出向量的所有数值之和为1,同时数值也是对应类别的概率。
例如上图,计算得:
y d o g = e 11.7 e 11.7 + e 23 + e 20 ≈ 0 y c a t = e 23 e 11.7 + e 23 + e 20 ≈ 0.953 y t r e e = e 20 e 11.7 + e 23 + e 20 ≈ 0.047 y_{dog} = \frac{e^{11.7}}{e^{11.7}+e^{23}+e^{20}} \approx 0 \\\quad\\ y_{cat} = \frac{e^{23}}{e^{11.7}+e^{23}+e^{20}} \approx 0.953 \\ \quad\\ y_{tree} = \frac{e^{20}}{e^{11.7}+e^{23}+e^{20}} \approx 0.047 ydog=e11.7+e23+e20e11.7≈0ycat=e11.7+e23+e20e23≈0.953ytree=e11.7+e23+e20e20≈0.047
当输出值转换结束后,我们就可以开始计算Loss值了
分类任务的Loss损失函数与回归任务中的有所不同,我们选用交叉熵损失函数(CrossEntropy Loss),具体公式如下:
二分类: L = − [ y ^ l o g ( y ′ ) + ( 1 − y ^ ) l o g ( 1 − y ′ ) ] L=-[\hat{y}log(y^{\prime}) +(1-\hat{y})log(1-y^{\prime})] L=−[y^log(y′)+(1−y^)log(1−y′)]
多分类: L = 1 N ∑ i = 1 n L i = − 1 N ∑ i = 1 n ∑ c = 1 M y i c l o g ( p i c ) L=\frac{1}{N}\sum_{i=1}^{n}L_{i}=-\frac{1}{N}\sum_{i=1}^{n}\sum_{c=1}^{M}y_{ic}log(p_{ic}) L=N1∑i=1nLi=−N1∑i=1n∑c=1Myiclog(pic)
实际上,二分类是N=2情况下的多分类。
我们可以借助下图理解公式。
总结流程
模型领域发展
Sota
Sota 通常是 “State-of-the-Art” 的缩写,意为 “最前沿的”“最先进的”。在机器学习、计算机视觉、自然语言处理等领域中,Sota 通常用来描述在特定任务中目前表现最好的方法或模型。AlexNet,VGGNet,ResNet都曾经是Sota。
AlexNet
AlexNet 是 2012 年在 ImageNet 图像识别挑战赛中大放异彩的卷积神经网络,它的出现是深度学习发展历程中的一个关键里程碑。在 2012 年的比赛中,AlexNet 以 15.3% 的 top - 5 错误率大幅超越了当时的亚军。 AlexNet有6亿个参数和650,000个神经元,包 含5个卷积层,有些层后面跟了max-pooling层,3个全连接层
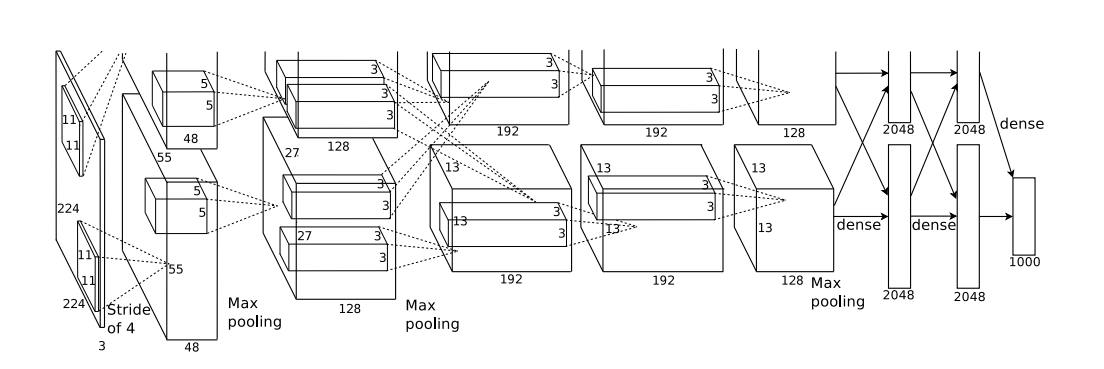
我们可以通过直接打印alexnet模型来理解他的结构。
import torchvision.models as model
test_alexNet = model.alexnet()
print(test_alexNet)
# 以下为控制台输出结果
AlexNet(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace=True)
(8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace=True)
(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(6, 6))
(classifier): Sequential(
(0): Dropout(p=0.5, inplace=False)
(1): Linear(in_features=9216, out_features=4096, bias=True)
(2): ReLU(inplace=True)
(3): Dropout(p=0.5, inplace=False)
(4): Linear(in_features=4096, out_features=4096, bias=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
其创新点在于:
- 使用了Relu激活函数
- 采用了Dropout正则化技巧
- 采用重叠池化
- 使用局部响应归一化(LRN)
Dropout 和 归一化
Dropout 是一种在神经网络训练过程中使用的正则化技术。在每次训练迭代时,以一定的概率(例如)随机地将神经网络中的神经元(包括其输入连接和输出连接)设置为 “停用” 状态,就好像这些神经元从网络中 “消失” 了一样。而那些未被停用的神经元则继续进行前向传播和反向传播更新权重。Dropout 通过随机停用神经元,使得网络不能依赖于某些特定神经元的固定组合来进行预测,从而减少对训练数据中特定模式的过度拟合。
归一化可以在深度学习的各个角落看到。 它可以让模型关注数据的分布,而不受数据量纲的影响。 归一化可以保持学习有效性,缓解梯度消失和梯度爆炸。 前面章节介绍过,便不再赘述。
BatchNorm(Batch Normalization)即批标准化,是一种对神经网络中间层的输入进行归一化的技术。在神经网络的训练过程中,对于一个批次(batch)的数据,它会分别对每个特征维度进行归一化。
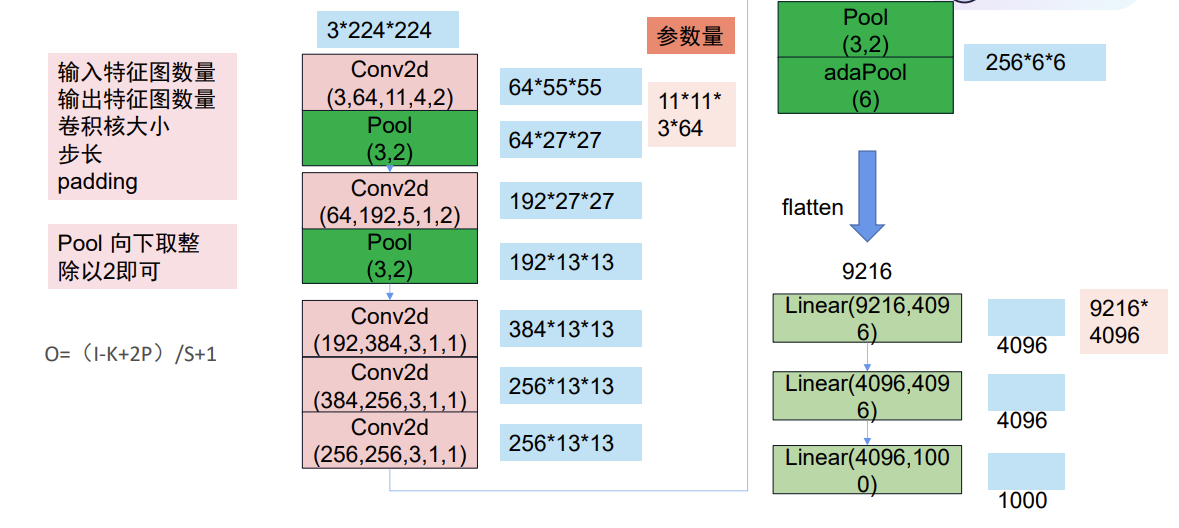
AlexNet代码
Conv2d(3, 64, 11, 4, 2)分别对应了,输入图像的通道数、卷积生成的输出通道数、卷积核的大小、步长、paddingPool(3, 2)对应了 第一个是大小,第二个是步长x = x.view(x.size()[0], -1)为了将前面多维度的tensor展平成一维,以便进行全连接get_parameter_number(model) 用于获取某一层的参数数量
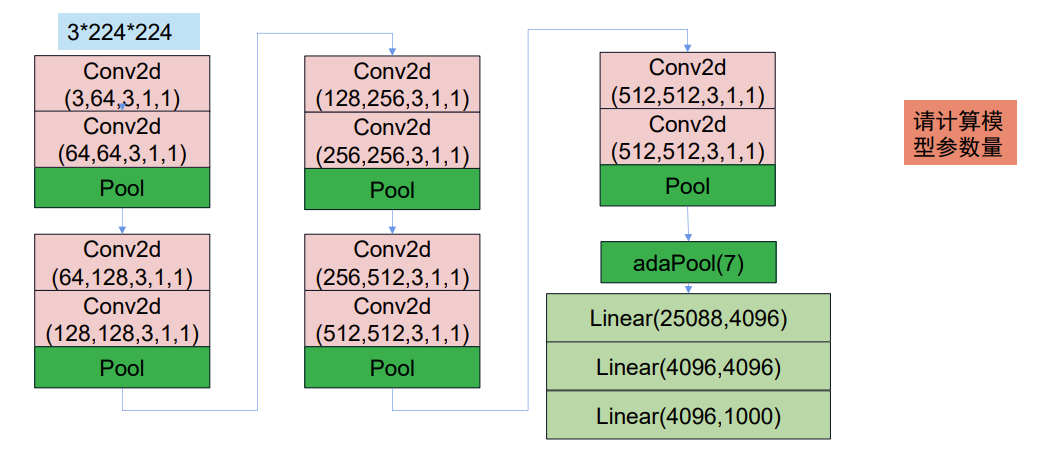
VGGNet
2014年,VGG网络被提出,其在AlexNet的基础上, 运用了更小的卷积核,并且加深了网络, 达到了更好的效果,直到今天,在某些场合,我们仍在使用VGG
结构简洁 :卷积层均采用较小的卷积核(如 3x3),通过堆叠多个这样的小卷积核来增加网络的深度。
深度较深:通常有 16 层或 19 层等不同的版本,深度的增加使得网络能够学习到更复杂的特征表示,从而在图像分类等任务上取得较好的效果。

我们可以通过直接打印VGGNet模型来理解他的结构。
import torchvision.models as model
VGGNet = model.vgg13()
print(VGGNet)
# 以下为控制台输出结果
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(15): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(16): ReLU(inplace=True)
(17): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(20): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(21): ReLU(inplace=True)
(22): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(23): ReLU(inplace=True)
(24): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
代码
import torchvision.models as models
import torch.nn as nn
class vggLayer(nn.Module):
def __init__(self, in_, mid_, out_):
super(vggLayer, self).__init__()
self.relu = nn.ReLU()
self.conv1 = nn.Conv2d(in_, mid_, 3, 1, 1)
self.conv2 = nn.Conv2d(mid_, out_, 3, 1, 1)
self.maxPool = nn.MaxPool2d(2, 2)
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.relu(x)
x = self.maxPool(x)
return x
class myVGG(nn.Module):
def __init__(self):
super(myVGG, self).__init__()
self.relu = nn.ReLU()
self.drop = nn.Dropout(p=0.5)
self.adaPool = nn.AdaptiveAvgPool2d(7)
self.layer1 = vggLayer(3, 64, 64)
self.layer2 = vggLayer(64, 128, 128)
self.layer3 = vggLayer(128, 256, 256)
self.layer4 = vggLayer(256, 512, 512)
self.layer5 = vggLayer(512, 512, 512)
self.fc1 = nn.Linear(25088, 4096)
self.fc2 = nn.Linear(4096, 4096)
self.fc3 = nn.Linear(4096, 1000)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x = self.adaPool(x)
x = x.view(x.size()[0], -1)
x = self.fc1(x)
x = self.relu(x)
x = self.drop(x)
x = self.fc2(x)
x = self.relu(x)
x = self.drop(x)
x = self.fc3(x)
return x
import torch
myVgg = myVGG()
#
img = torch.zeros((1, 3, 224,224))
out = myVgg(img)
print(out.size())
def get_parameter_number(model):
total_num = sum(p.numel() for p in model.parameters())
trainable_num = sum(p.numel() for p in model.parameters() if p.requires_grad)
return {'Total': total_num, 'Trainable': trainable_num}
print(get_parameter_number(myVgg))
print(get_parameter_number(myVgg.layer1))
print(get_parameter_number(myVgg.layer1.conv1))
print(get_parameter_number(myVgg))
print(get_parameter_number(myVgg.layer1))
print(get_parameter_number(myVgg.layer1.conv1))
ResNet
ResNet(Residual Network,残差网络)由微软研究院的何恺明等人提出。它的出现主要是为了解决深度神经网络随着层数增加而出现的性能退化问题,
残差链接:是 ResNet中的核心结构。它的基本思想是在网络的某些层之间建立直接的连接,使得输入信息能够直接传递到后续层,而不仅仅依赖于传统的卷积层堆叠所产生的变换。
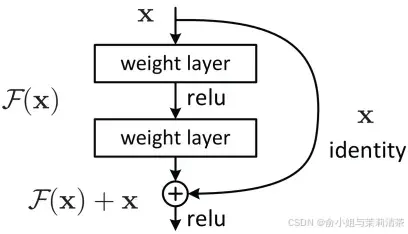
减小梯度消失和梯度爆风险:残差连接为梯度的反向传播提供了一条直接的通道,使得梯度能够更有效地从深层网络传播到浅层网络。在计算梯度时,由于输入可以直接传递到输出并参与损失函数的计算,梯度可以沿着这条残差路径顺利传播,减少了梯度消失和梯度爆炸的风险。
残差网络架构
我们可以通过直接打印ResNet模型来理解他的结构
import torchvision.models as model
ResNet = model.resnet18()
print(ResNet)
# 以下为控制台输出结果,
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)

补充
手撕卷积神经网络
- 现有特征图100100. 卷积核大小为3,padding1, 卷出来的特征图多大。 (100100)
- 特征图88. 卷积核 7, 问卷出来的特征图多大。这个卷积核的参数量多少? (22 7*7)
- 特征图64224224. 卷积核6433, padding=1,卷积核数量128 卷出来特征图多大。这套卷积核的参数量多少? (128224224 3364*128)
卷积操作和Zerp-Padding操作是否相悖
不相悖
二者目的的具有兼容性:卷积操作缩小特征图尺寸和 Zero Padding 维持特征图尺寸,本质上都是为了更好地完成网络的任务,只是在不同的场景下有不同的侧重点。在需要减少数据量、扩大感受野的情况下,我们利用卷积操作的缩小特性;而在需要保持特征图尺寸以防止信息过快丢失的情况下,我们采用 Zero Padding。
二者协同工作:在实际的卷积神经网络设计中,这两种操作是可以协同工作的。灵活的运用体现了它们在功能上是互补的,而不是相互矛盾的。网络架构师可以根据具体的任务需求(如分类精度、计算资源等)来决定在何时何地使用卷积缩小特征图,何时使用 Zero Padding 来维持尺寸。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)