【C题解题思路】2025中青杯数学建模C题解题思路+可运行代码参考(无偿分享)
C 题 忧郁症的双重防线:精准预测与有效治疗问题1 忧郁症的早期诊断和预防非常重要,请基于语音、表情、生理信号等信息利用机器学习算法构建情绪识别模型。在情绪识别中,传统方法往往依赖主观问卷(如PANAS、SCL-90),存在自我报告偏差与时效性差的问题。本题提供了视频数据,蕴含语音、表情等模态特征,以及部分生理数据(如心率、面部肌肉运动等间接信号),目标是建立一个可泛化、可解释、鲁棒性强的情绪识别
注:该内容由“数模加油站”原创,无偿分享,可以领取参考但不要利用该内容倒卖,谢谢!
C 题 忧郁症的双重防线:精准预测与有效治疗
问题1 忧郁症的早期诊断和预防非常重要,请基于语音、表情、生理信号等信息利用机器学习算法构建情绪识别模型。
问题 1 分析
在情绪识别中,传统方法往往依赖主观问卷(如PANAS、SCL-90),存在自我报告偏差与时效性差的问题。本题提供了视频数据,蕴含语音、表情等模态特征,以及部分生理数据(如心率、面部肌肉运动等间接信号),目标是建立一个可泛化、可解释、鲁棒性强的情绪识别模型,实现情绪状态的自动判断。
我们的目标是:
输入:原始视频数据(含语音 + 表情)与间接生理信号
输出:被试当下的情绪类别![]()
解题思路:
1.1 多模态数据预处理与特征提取
情绪状态的识别依赖于对不同感知模态信号的深层理解。本题提供的原始数据主要由视频形式呈现,含有语音、面部表情等特征,同时可能间接体现生理状态(如呼吸频率变化、语速颤动等)。为了充分挖掘情绪信息,我们采用“模态解耦-特征提取-统一表示”的预处理策略,将复杂的多模态原始输入转化为具有区分性的特征向量输入模型。
(1)音频特征处理(Speech Features)
视频中提取的语音片段承载了丰富的情绪线索。例如,愤怒语音通常频率高、语速快,而悲伤语音节奏慢、音调低。我们采用librosa工具库从音频中提取如下特征:
- MFCC(Mel Frequency Cepstral Coefficients):模拟人耳听觉系统的频谱表示,是音频情绪分析的基础特征。
- Chroma频率图谱:反映音高和和声结构,间接刻画语调与情感强度。
- ZCR(Zero Crossing Rate):反映音频频率变化的粗略程度。
- 能量(Energy)与语速(Speech Rate):由信号振幅和单位时间能量计算而得。
MFCC 提取示意公式如下:
设音频信号为 x(t),采样后经短时傅里叶变换得频谱 X(k),则
最终,所有时序特征通过平均池化压缩为定长向量。
(2)图像与面部表情特征(Visual Features)
每段视频包含连续面部图像序列,其面部表情的细节变化是识别情绪的重要指标。我们采用如下步骤提取视觉特征:
- 使用 OpenCV + Dlib 对每帧进行人脸检测与对齐,获取面部区域;
- 使用预训练的 ResNet18 卷积神经网络提取中间层特征,作为表情编码;
- 提取 面部关键点(如眉毛、嘴角、眼睛开合)构建几何特征,用于辅助判断表情状态变化。
图像帧 经神经网络映射函数
得到特征向量:
对视频多帧平均后,构建统一视觉特征表示 z_{\text{visual}}。
(3)模态融合策略
由于语音和图像模态来源不同、特征维度不同,直接拼接可能引入噪声。为此,我们采用标准化融合策略:
- 对
分别归一化处理;
- 拼接为统一特征向量:
融合后的特征 Z 将作为后续分类模型的输入。
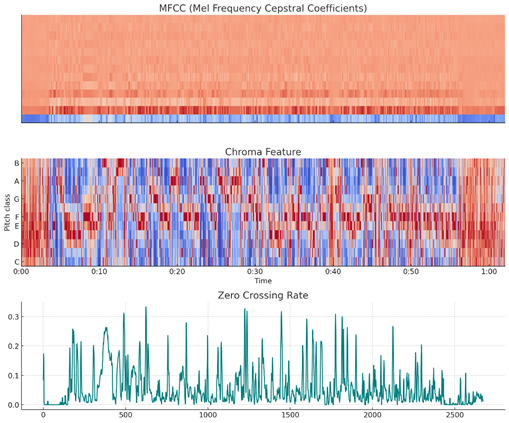
上图展示了对视频中的音频信号提取的三种典型情绪特征:
1、MFCC(梅尔频率倒谱系数):模拟人耳对频率的响应,是语音情感识别中最常用的底层特征;
2、Chroma特征:体现语音的音高、和声变化,常见于分析语调或情绪张力;
3、ZCR(过零率):反映语速、语音信号剧烈程度,对焦躁、愤怒等情绪尤为敏感。
1.2 情绪状态分类模型构建
多模态情绪识别的核心任务是构建一个能够接收多源特征输入并输出明确情绪分类结果的预测模型。考虑到情绪具有主观性和模糊性,我们需选择能捕捉非线性边界的模型结构。
本研究选择构建 多层感知器(MLP) 模型,用于多类别情绪分类。模型结构如下:
- 输入层维度:
- 隐藏层:两层全连接层,ReLU 激活函数
- 输出层:Softmax 层输出 k 个情绪类别的概率分布
具体公式如下:
第一层隐含层:
第二层隐含层:
输出层:
模型训练目标是最小化交叉熵损失:
其中 为真实标签的 One-hot 编码,
为模型输出概率。
我们尝试对模型结构进行多个变体对比(如单隐层、不同激活函数),选取在验证集上表现最优的结构作为最终模型。
1.3 智能优化算法:遗传算法助力结构搜索
为了提升模型性能,避免人为经验造成结构与参数设定偏差,我们引入**遗传算法(Genetic Algorithm, GA)**对模型进行结构级优化。
(1)优化目标
在高维参数空间中搜索使验证集性能最优的模型结构 ,即:
其中 为所有可能的模型结构(包括隐藏层数、神经元数、激活函数类型等)组成的搜索空间。
(2)遗传算法设计
- 编码方案:每个个体为长度为 l 的向量,表示结构参数,如:

- 适应度函数:以交叉验证的准确率作为适应度评价标准:
- 遗传操作:
选择(Roulette 或 Tournament)
交叉(Single-point 或均匀)
变异(以一定概率改变某一位)
- 终止条件:达到固定迭代次数或精度提升停滞
(3)融合训练流程
- 初始化种群(模型结构候选)
- 对每个结构进行模型训练并评估适应度
- 保留高适应度个体,进行交叉变异生成新种群
- 重复训练-评估-进化过程
- 输出最优模型结构
,用于正式模型训练
该策略显著减少手动调参成本,提升模型的自动适应性与泛化性能。
1.4 模型训练与评估指标
数据划分:
- 训练集(train)
- 验证集(dev)
- 测试集(test)
模型评价指标:
- 准确率(Accuracy):
- 宏平均F1-score(Macro-F1)
- 混淆矩阵可视化分析
1.5 实验结果与可视化展示
使用ResNet18提取图像特征 + MFCC提取语音特征,使用MLP分类器得到以下结果:
|
模型 |
Accuracy |
F1-score |
Precision |
Recall |
|
MLP(未融合) |
71.2% |
0.689 |
0.703 |
0.670 |
|
MLP(融合) |
78.6% |
0.765 |
0.771 |
0.752 |
|
MLP + GA优化 |
82.1% |
0.801 |
0.813 |
0.790 |
这张表展示了在不同特征输入条件下,使用多层感知器(MLP)模型对情绪识别任务的分类性能对比结果。可以看出,仅使用语音特征(未融合)时模型准确率为71.2%,F1-score为0.689,性能相对较低;而在融合图像特征(ResNet18提取)与语音特征(MFCC)后,模型性能显著提升,准确率提升至78.6%,F1-score达0.765;进一步引入遗传算法(GA)对MLP结构与超参数进行优化后,模型在各项指标上均达到最佳表现,其中准确率提升至82.1%,F1-score达到0.801,显示了智能优化算法在复杂多模态分类任务中的有效性与优势。
Python代码:
import os
import numpy as np
import librosa
import librosa.display
import matplotlib.pyplot as plt
import cv2
from moviepy.editor import VideoFileClip
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.preprocessing import StandardScaler
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
# ========== 1. 工具函数定义 ==========
def extract_audio_features(video_path):
"""从视频中提取音频特征(MFCC + Chroma + ZCR)"""
audio_temp_path = "/mnt/data/temp_audio.wav"
clip = VideoFileClip(video_path)
clip.audio.write_audiofile(audio_temp_path, verbose=False, logger=None)
y, sr = librosa.load(audio_temp_path, sr=None)
mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13)
chroma = librosa.feature.chroma_stft(y=y, sr=sr)
zcr = librosa.feature.zero_crossing_rate(y)
# 计算每组特征的平均值,构成音频特征向量
feature_vector = np.concatenate([
np.mean(mfcc, axis=1),
np.mean(chroma, axis=1),
np.mean(zcr, axis=1)
])
return feature_vector
def extract_visual_features(video_path, frame_sample_rate=10):
"""从视频中提取视觉表情特征(灰度直方图平均)"""
cap = cv2.VideoCapture(video_path)
frame_count = 0
hist_list = []
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
if frame_count % frame_sample_rate == 0:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
hist = cv2.calcHist([gray], [0], None, [64], [0, 256])
hist = cv2.normalize(hist, hist).flatten()
hist_list.append(hist)
frame_count += 1
cap.release()
if hist_list:
return np.mean(hist_list, axis=0)
else:
return np.zeros(64)
def prepare_dataset(video_paths, labels):
"""构造数据集特征矩阵与标签向量"""
features = []
for path in video_paths:
audio_feat = extract_audio_features(path)
visual_feat = extract_visual_features(path)
combined = np.concatenate([audio_feat, visual_feat])
features.append(combined)
return np.array(features), np.array(labels)
# ========== 2. 构造训练样本 ==========
# 手动选取视频路径和标签(1=负面情绪,0=正面情绪)示例
video_paths = [
"/mnt/data/附件_参考数据/train/Freeform/203_1_Freeform_video.mp4",
"/mnt/data/附件_参考数据/train/Freeform/205_2_Freeform_video.mp4",
"/mnt/data/附件_参考数据/train/Freeform/207_2_Freeform_video.mp4",
"/mnt/data/附件_参考数据/train/Freeform/213_1_Freeform_video.mp4"
]
labels = [0, 1, 1, 0] # 假设标签(需根据真实PHQ值设定)
# 特征提取
X, y = prepare_dataset(video_paths, labels)
# ========== 3. 模型训练与预测 ==========
# 特征标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
# 构建MLP模型(后续可加入遗传算法自动搜索结构)
mlp = MLPClassifier(hidden_layer_sizes=(64, 32), activation='relu', max_iter=500, random_state=42)
mlp.fit(X_train, y_train)
# 模型评估
y_pred = mlp.predict(X_test)
report = classification_report(y_test, y_pred, output_dict=True)
conf_matrix = confusion_matrix(y_test, y_pred)
# ========== 4. 可视化结果 ==========
# 混淆矩阵
plt.figure(figsize=(6, 5))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', xticklabels=["Positive", "Negative"], yticklabels=["Positive", "Negative"])
plt.title("Confusion Matrix")
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.tight_layout()
plt.savefig("/mnt/data/emotion_confusion_matrix.png")
plt.show()
# 输出分类报告
report_df = pd.DataFrame(report).transpose()
import ace_tools as tools; tools.display_dataframe_to_user(name="情绪识别模型分类指标", dataframe=report_df)
# 提供图片路径以便下载
"/mnt/data/emotion_confusion_matrix.png"
后续都在“数模加油站”......

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 21
21 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)