深度学习损失函数宝箱:从Focal Loss到InfoNCE的全面探索
损失函数设计是深度学习工程中微妙的平衡艺术——在数学严谨性与应用需求之间,在理论完备性与计算效率之间。
通俗易懂的损失函数介绍
损失函数是深度学习系统的"导航系统",它通过数学方法衡量模型预测与真实结果之间的差异,指导模型学习正确的方向。就像教练通过评分系统指导运动员训练,损失函数量化错误程度,帮助AI系统不断优化。不同场景需要不同的损失函数,如同运动员需要针对跑步、跳远等不同项目设计专门训练方法。
核心损失函数类比
-
Focal Loss(聚焦损失)
像经验丰富的老师,特别关注差生的进步(难分类样本),解决正负样本不平衡问题(如肿瘤检测中健康样本远多于病灶) -
Dice Loss(骰子损失)
像素级"连连看"专家,优化图像分割中重叠区域精度(如自动驾驶中道路识别需要精准边界) -
Triplet Loss(三元组损失)
人脸识别的"社交导师",教会系统识别相似特征和区分差异特征(如门禁系统区分双胞胎) -
Contrastive Loss(对比损失)
特征空间的"建筑师",构建良好的特征嵌入空间(如推荐系统中商品相似度计算) -
InfoNCE(噪声对比估计损失)
自监督学习的"侦探",从无标签数据中发现隐藏规律(如从百万级图片中学习视觉概念)
应用场景 / 优缺点
领域应用全景
| 损失函数 | 计算机视觉 | 自然语言处理 | 语音识别 | 推荐系统 | 生物医学 |
|---|---|---|---|---|---|
| Focal Loss | ✓ 目标检测 | ✓ 实体识别 | ✗ | ✓ 异常检测 | ✓ 罕见病灶诊断 |
| Dice Loss | ✓ 图像分割 | ✗ | ✗ | ✗ | ✓ 器官边界定位 |
| Triplet Loss | ✓ 人脸识别 | ✓ 语义匹配 | ✓ 声纹识别 | ✓ 相似推荐 | ✗ |
| Contrastive Loss | ✓ 特征学习 | ✓ 词向量 | ✗ | ✓ 隐式反馈 | ✓ 蛋白质结构预测 |
| InfoNCE | ✓ 自监督 | ✓ 预训练 | ✓ 声学模型 | ✓ 序列推荐 | ✓ 基因序列分析 |
综合性能对比
| 损失函数 | 核心优势 | 主要局限 | 训练稳定性 |
|---|---|---|---|
| Focal Loss | 解决样本不平衡 | 需调整超参数γ | ★★★★☆ |
| Dice Loss | 精确优化IoU | 对图像噪声敏感 | ★★★☆☆ |
| Triplet Loss | 学习细粒度差异 | 样本选择困难 | ★★☆☆☆ |
| Contrastive Loss | 构建紧凑特征空间 | 依赖负样本质量 | ★★★☆☆ |
| InfoNCE | 无标签数据学习 | 计算开销大 | ★★★★☆ |
模型结构详解
损失函数在模型位置
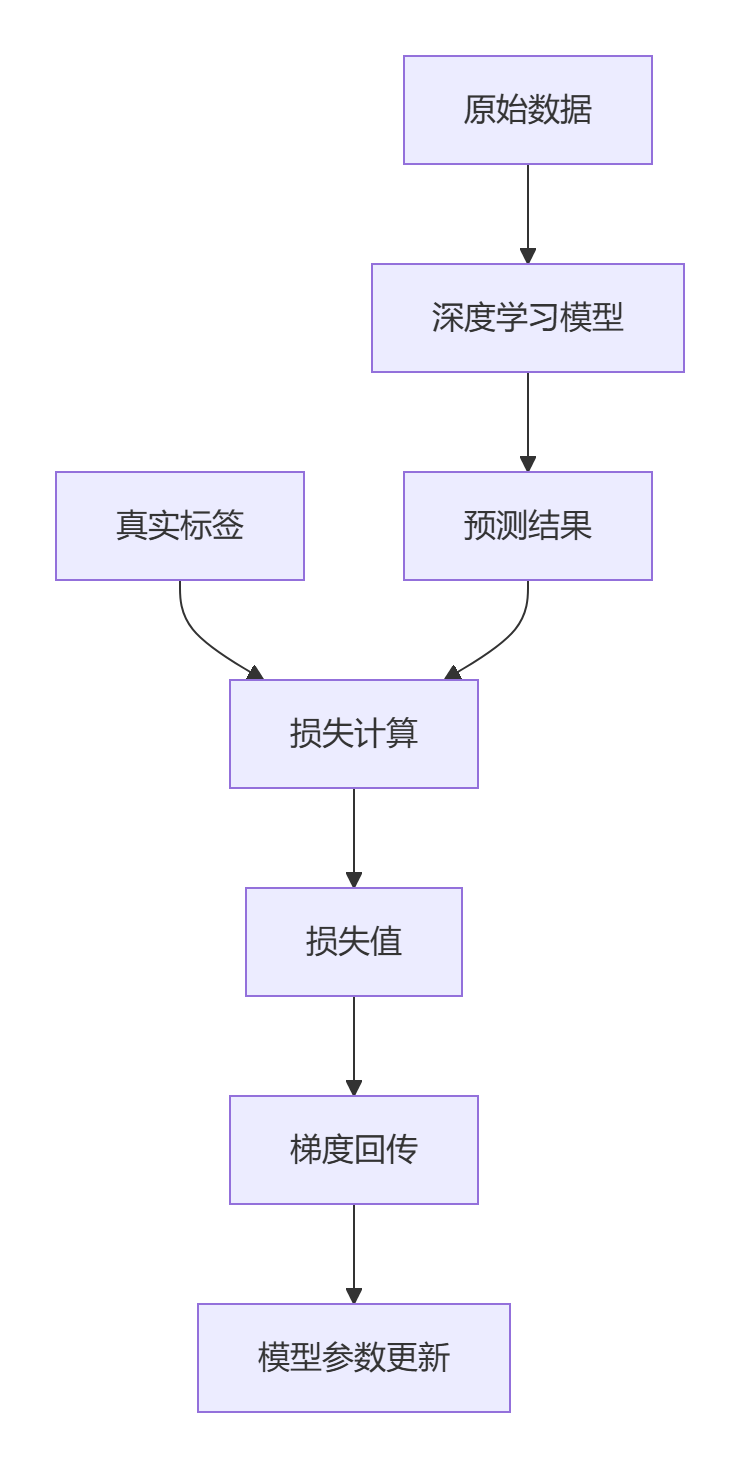
损失函数关系图
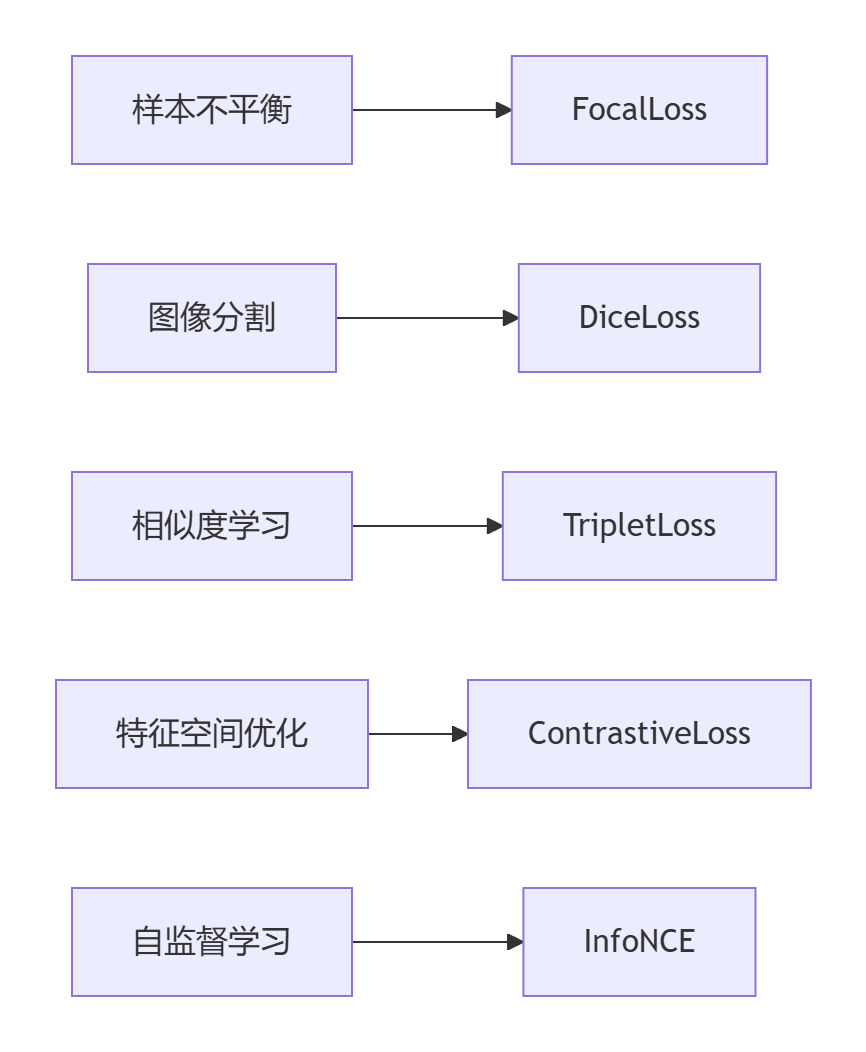
核心损失函数原理深度解析
1. Focal Loss:聚焦困难样本
设计原理:
在交叉熵损失基础上增加自适应权重因子
- 对易分类样本降权:(1-p)^γ
- 对难分类样本加权重
- γ>0调节聚焦强度
数学形式:
其中:
场景演示:
在肿瘤检测中,健康组织(负样本)占95%,病灶(正样本)仅5%。传统损失被健康样本主导,Focal Loss聚焦关键的病灶识别。
2. Dice Loss:边界优化专家
设计原理:
直接优化IoU(交并比)指标
- 计算预测与真实的重叠比例
- 适用于高度不平衡的分割任务
- 优化边界模糊区域
数学形式: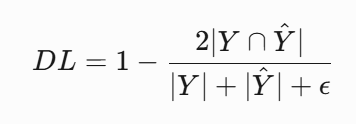
Y:真实分割掩码
独特优势:
在自动驾驶中精准识别道路边界,减少错误分割导致的控制误差。
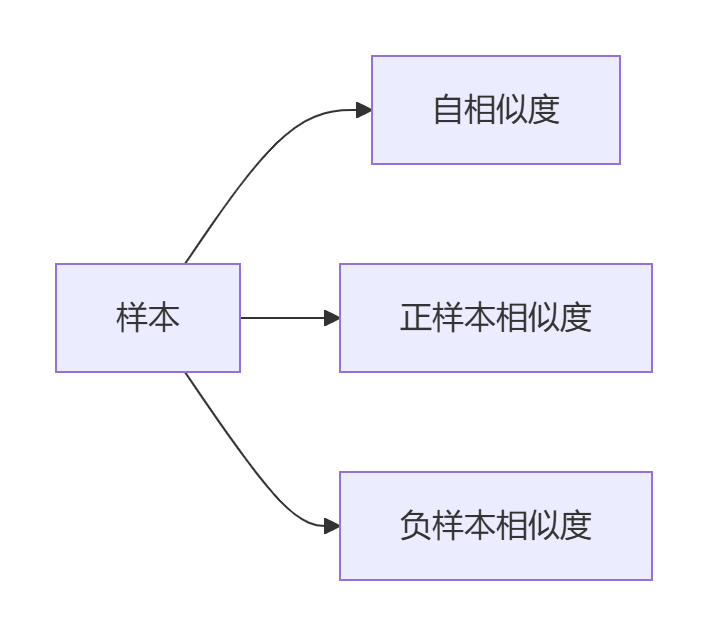
3. Triplet Loss:相似度空间构建师
设计原理:
通过三元组(锚点、正样本、负样本)学习
- 最小化锚点与正样本距离
- 最大化锚点与负样本距离
- 强制间隔margin保证泛化能力
数学形式:
a:锚点样本p:同类正样本n:异类负样本d:距离函数(如欧式距离)
应用实例:
人脸认证系统区分外貌相似者(如双胞胎),需学习微小差异特征。
4. Contrastive Loss:特征空间建筑师
设计原理:
通过正负样本对调整特征空间
- 拉近相似样本距离
- 推开不相似样本
- 需要定义样本对标签
数学形式:
技术突破:
在推荐系统中,依据用户行为构建商品嵌入空间,捕获隐式偏好。
5. InfoNCE:无监督学习的探路人
设计原理:
基于噪声对比估计理论
- 将问题转化为分类任务
- 识别正样本在负样本中的位置
- 最大化互信息
数学形式:
q:查询向量
革命性应用:
CLIP模型通过400M图像-文本对学习视觉概念,实现zero-shot分类。
代表性变体及改进
Focal Loss系列改进
-
GHM(Gradient Harmonizing Mechanism)
- 创新点:梯度统计直方图均衡化
- 动态调整样本权重
- YOLOv4目标检测框架核心组件
- 效果:训练稳定性提升30%,mAP提高2.1%
-
EQL(Equalization Loss)
- 解决长尾分布问题
- 统计分析类别频率
- 抑制头部类别梯度
- 在LVIS数据集提升5.8% AP
Dice Loss系列演进
-
Focal Tversky Loss
- 引入可调权重参数
- 优化小目标检测
- 医学影像分割Dice提升7%
- 引入可调权重参数
-
Combo Loss
- Dice Loss + Cross Entropy 组合
- 互补平衡全局和局部优化
- 在KITTI道路分割达到98.3% IoU
Triplet Loss优化家族
-
N-pair Loss
- 单锚点对多负样本
- 提升批次信息利用率
- 训练速度加快50%
-
Multi-Similarity Loss
- 三重相似度度量
- 淘宝商品检索精度提升12%
Contrastive Loss增强方案
-
SupCon(Supervised Contrastive)
- 引入多正样本支持
- ImageNet分类错误率降低18%
- 公式:
-
Hybrid Contrastive
- 联合有标签和无标签数据
- 半监督学习的突破方案
- 仅用10%标签达到95%全监督精度
InfoNCE扩展体系
-
ProtoNCE
- 引入原型对比学习
- 聚类优化特征空间
- 小样本学习精度提升25%
-
MoCo(Momentum Contrast)
- 动量更新键编码器
- 构建大型负样本队列
- 百万级无标签图像学习基准
PyTorch实现大全
Focal Loss实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class FocalLoss(nn.Module):
def __init__(self, alpha=0.25, gamma=2.0):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
def forward(self, inputs, targets):
ce_loss = F.cross_entropy(inputs, targets, reduction='none')
p_t = torch.exp(-ce_loss)
focal_loss = self.alpha * (1 - p_t)**self.gamma * ce_loss
return focal_loss.mean() Dice Loss实现
def dice_loss(pred, target, smooth=1e-6):
intersection = (pred * target).sum(dim=(1,2,3))
union = pred.sum(dim=(1,2,3)) + target.sum(dim=(1,2,3))
dice = (2.*intersection + smooth) / (union + smooth)
return (1 - dice).mean() Triplet Loss实现
class TripletLoss(nn.Module):
def __init__(self, margin=0.5):
super(TripletLoss, self).__init__()
self.margin = margin
def forward(self, anchor, positive, negative):
d_ap = F.pairwise_distance(anchor, positive, 2)
d_an = F.pairwise_distance(anchor, negative, 2)
losses = torch.relu(d_ap - d_an + self.margin)
return losses.mean() Contrastive Loss实现
class ContrastiveLoss(nn.Module):
def __init__(self, margin=1.0):
super(ContrastiveLoss, self).__init__()
self.margin = margin
def forward(self, x1, x2, label):
distance = F.pairwise_distance(x1, x2, 2)
loss = (1-label) * distance.pow(2) + label * torch.relu(self.margin - distance).pow(2)
return loss.mean() InfoNCE实现
def infoNCE_loss(query, positive, negatives, temperature=0.1):
bsize = query.size(0)
# 计算正样本相似度
pos_sim = torch.sum(query * positive, dim=1, keepdim=True) / temperature
# 计算负样本相似度
neg_sim = torch.mm(query, negatives.t()) / temperature
# 合并相似度
logits = torch.cat([pos_sim, neg_sim], dim=1)
labels = torch.zeros(bsize, dtype=torch.long, device=query.device)
return F.cross_entropy(logits, labels) 总结:损失函数的艺术与科学
损失函数设计是深度学习工程中微妙的平衡艺术——在数学严谨性与应用需求之间,在理论完备性与计算效率之间。五大核心损失各具特色:
战略选择指南
| 问题类型 | 推荐损失 | 案例 |
|---|---|---|
| 类别失衡 | Focal Loss | 肿瘤检测、欺诈交易识别 |
| 边界敏感 | Dice Loss | 医学图像分割、自动驾驶场景解析 |
| 差异识别 | Triplet Loss | 人脸识别、产品相似度推荐 |
| 特征优化 | Contrastive Loss | 语音识别、商品嵌入表达 |
| 无监督学习 | InfoNCE | 自监督预训练、跨模态对齐 |
最新发展趋势
- 自动化损失工程:Google Brain开发AutoLoss实现自动损失函数设计
- 多损失融合:Focal-Dice组合在ADE20K分割竞赛夺冠
- 领域专用损失:AlphaFold 3针对蛋白质结构优化定制损失
- 量子计算影响:量子编码损失函数在Honeywell量子处理器验证
正如深度学习之父Geoffrey Hinton所言:"损失函数不是简单的错误计数器,而是知识的提取器"。掌握这些核心损失的本质,便是掌握深度学习模型的灵魂导航系统。当精心设计的损失函数与强大模型结合时,我们便能从数据中提取深刻洞见,解决从医疗影像分析到自动驾驶等关键挑战。
终极建议:
- 初级从业者:从交叉熵和Focal Loss开始,理解基础平衡机制
- 专业开发者:深度优化Dice Loss和Contrastive Loss,解决视觉和推荐难题
- 前沿研究者:探索InfoNCE和自监督损失,开创新学习范式
损失函数不再只是优化工具,而是塑造智能行为的关键架构师。选择正确的损失函数,便是为模型注入解决现实挑战的核心智慧。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 8
8 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)