ollama 运行和部署(大模型转换为 GGUF)
个人学习记录
·
1.创建自己虚拟环境llama.cpp
conda create --name llama.cpp python=3.10
conda activate llama.cpp2.下载克隆llama.cpp仓库和安装相关包
git clone https://github.com/ggerganov/llama.cpp.git
pip install -r llama.cpp/requirements.txt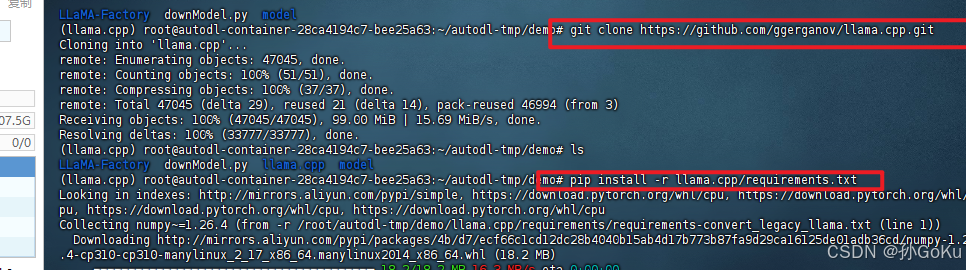 3.将hf模型转换为GGUF
3.将hf模型转换为GGUF
# 如果不量化,保留模型的效果
python llama.cpp/convert_hf_to_gguf.py /root/autodl-tmp/demo/model/Qwen/Qwen2.5-1.5B-Instruct_merged --outtype f16
--verbose --outfile /root/autodl-tmp/demo/model/Qwen/Qwen2.5-1.5B-Instruct_merged/Qwen2.5-1.5B-Instruct_merged-gguf.gguf
python llama.cpp/convert_hf_to_gguf.py 自己模型路径 --outtype f16 --verbose --outfile 自己定义模型gguf文件名
//可以选择量化(加速并有损效果)
--outtype q8_0
fp16 和 f32: 不量化,保留原始精度。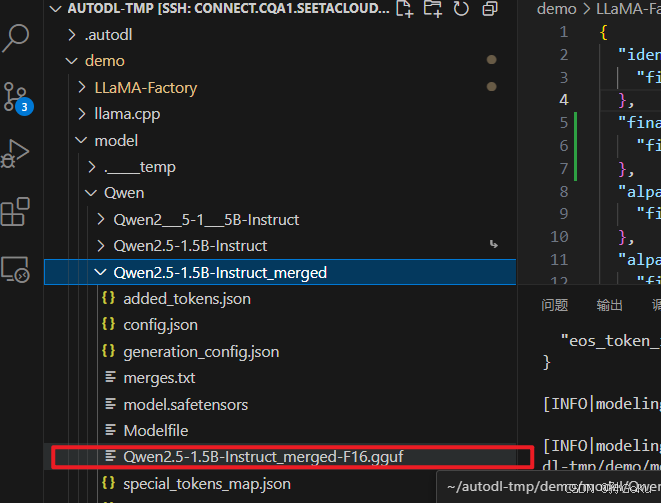
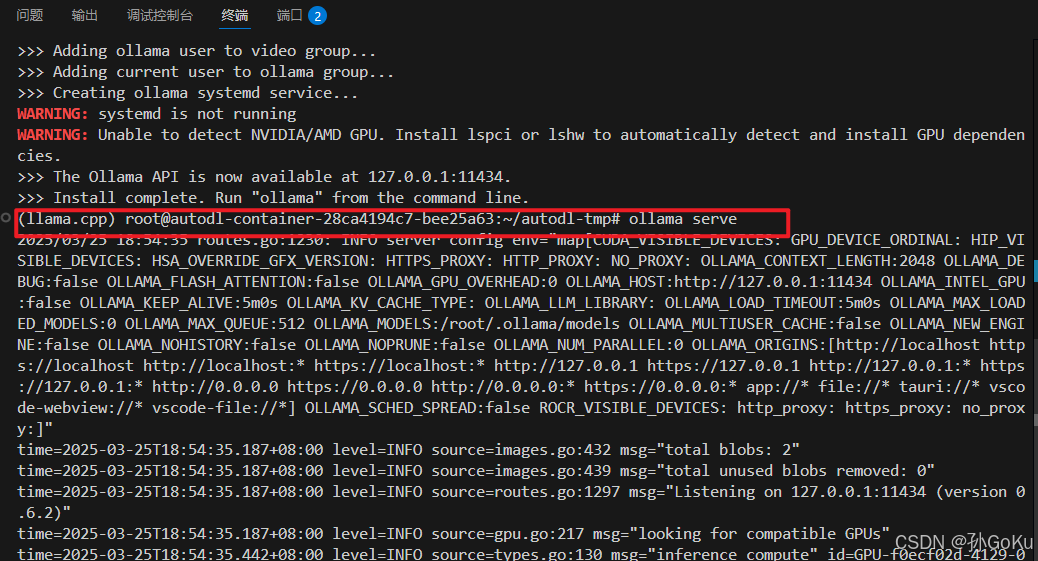
4.使用ollama运行gguf,先进行安装,启动ollama服务,不要进行关闭,重开一个端口
curl -fsSL https://ollama.com/install.sh | sh
ollama serve
5.创建ModelFile
#GGUF文件路径
FROM /root/autodl-tmp/demo/model/Qwen/Qwen2.5-1.5B-Instruct_merged/Qwen2.5-1.5B-Instruct_merged-F16.gguf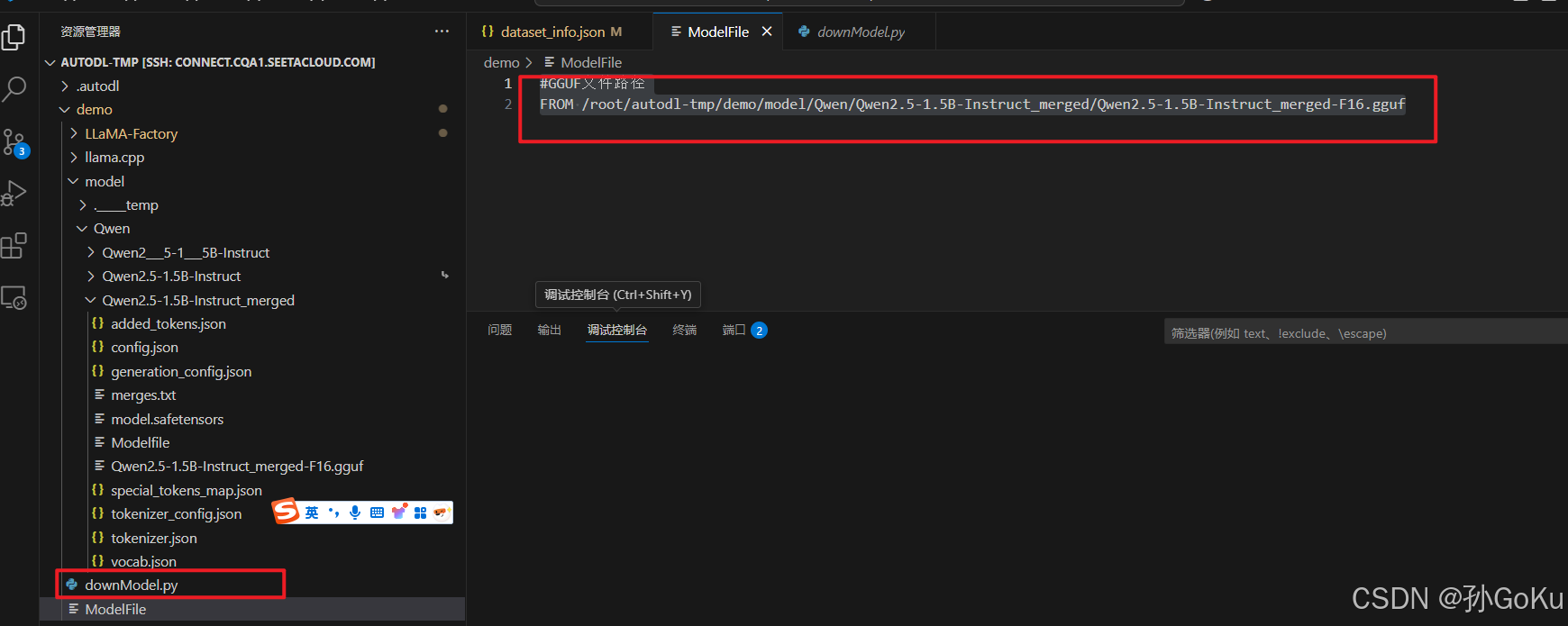
6.使用ollama create命令创建自定义模型
ollama create llama-Qwen-1.5B-merged --file ./ModelFile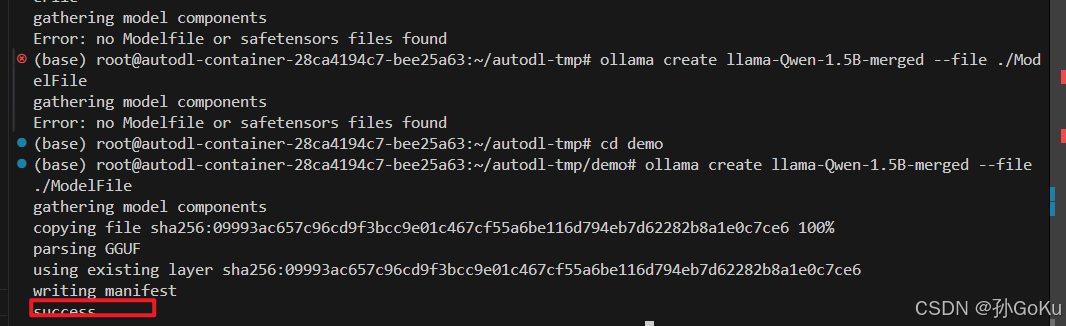
7.运行自定义模型,进行验证
ollama list
ollama run llama-Qwen-1.5B-merged:latest

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)