Ollama 上下文限2048的解决方案
ollama默认限制上下文的长度是2048,如果我们用ollama作为知识库基准模型,上下文超过2048直接会被阻断,提出内容不会根据上下文来回答官方提出一个解决方案那就是通过设置num_ctx的大小来设置上下文,但是如果把会话改成ollama支持的openAI的方式这个属性就无效了经过本人的测试默认qwen2.5:14b-instruct-q8_0占用17g的显存也就是限制上下文2048,但是如
1、通过增加配置
ollama默认限制上下文的长度是2048,如果我们用ollama作为知识库基准模型,上下文超过2048直接会被阻断,提出内容不会根据上下文来回答
官方提出一个解决方案那就是通过设置num_ctx的大小来设置上下文,但是如果把会话改成ollama支持的openAI的方式这个属性就无效了
经过本人的测试默认qwen2.5:14b-instruct-q8_0占用17g的显存也就是限制上下文2048,但是如果改成8192显存会直接飙升到30g左右,所以要慎重更改。或者可以使用vLLM的部署方案,经过测试长上下文显存优化会更好速度更快
import requests
url = "http://10.10.40.102:10434/api/chat"
payload = {
"model": "qwen2.5:14b-instruct-q8_0",
"stream": False,
"messages": [
{
"role": "system",
"content": """你可以根据需要修改这个系统提示""",
},
{"role": "user", "content": "如何快速创建可视化应用"},
],
"options": {"num_ctx": 8192}
}
response = requests.post(url, json=payload)
print(response.text)2、重新建立模型
还有一种方法那就是重新创建模型并修改上下文长度
导出配置文件Modelfile
ollama show --modelfile qwen2.5:14b-instruct-q8_0 > Modelfile修改Modelfile文件并配置上下文token PARAMETER num_ctx 4096
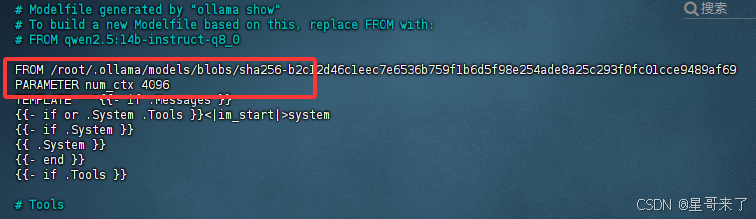
重新创建模型我直接改成了qwen2.5:14b-4096,然后你需要运行的就是这个qwen2.5:14b-4096这个模型,他的上下文限制就变成了4096
ollama create qwen2.5:14b-4096 -f Modelfile
魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)