Dify工作流中通过HTTP请求节点卸载模型,清除Ollama后台的内存和显存占用
博主希望在同一台主机上部署Dify+Ollama+Deepseek和AI绘图ComfyUI,在编写Dify文生图工作流中,Deepseek生成文本后立刻执行AI绘图。此时Ollama并未卸载Deepseek模型,内存和显存依旧有占用,这会影响AI绘图速度,所以通过HTTP请求的方式联系Ollama卸载模型。因为博主的Dify是在docker容器中运行,所以Ollama地址要用host.docker
·
背景需求:博主希望在同一台主机上部署Dify+Ollama+Deepseek和AI绘图ComfyUI,在编写Dify文生图工作流中,Deepseek生成文本后立刻执行AI绘图。此时Ollama并未卸载Deepseek模型,内存和显存依旧有占用,这会影响AI绘图速度,所以通过HTTP请求的方式联系Ollama卸载模型
具体实现:
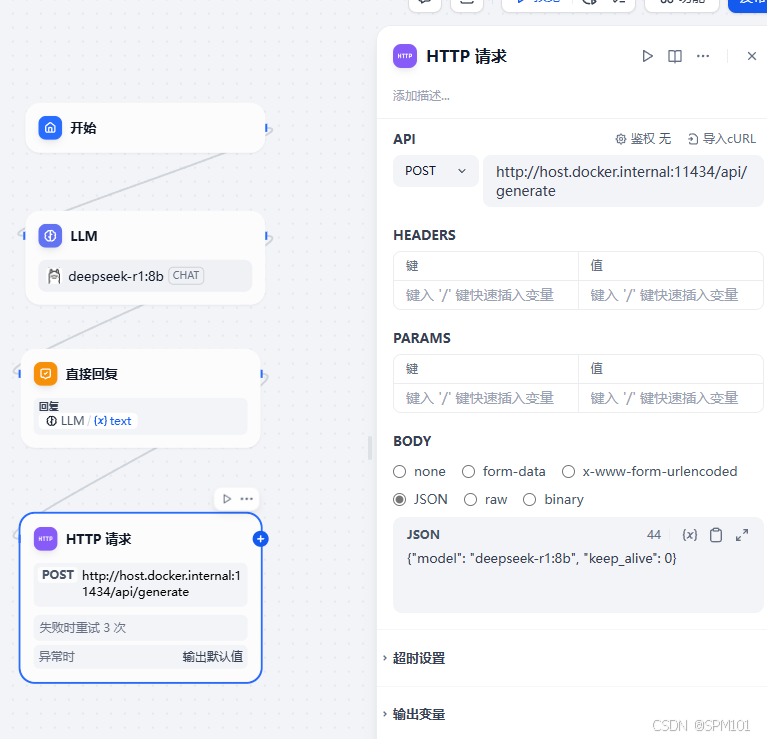
1.请求地址:http://Ollama地址:端口/api/generate
因为博主的Dify是在docker容器中运行,所以Ollama地址要用host.docker.internal
2.请求方式:POST
3.请求体:JSON
{"model": "deepseek-r1:8b", "keep_alive": 0}model:目标模型名称
keep_alive:0立即卸载,-1永不卸载

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)