神经网络语言模型
个人博客:http://www.chenjianqu.com/原文链接:http://www.chenjianqu.com/show-48.html语言模型语言模型是自然语言处理的一大利器,是NLP领域一个基本却又重要的任务。它的主要功能就是计算一个词语序列构成一个句子的概率,或者说计算一个词语序列的联合概率,这可以用来判断一句话出现的概率高不高,符不符合我们的表达...
个人博客:http://www.chenjianqu.com/
原文链接:http://www.chenjianqu.com/show-48.html
语言模型
语言模型是自然语言处理的一大利器,是NLP领域一个基本却又重要的任务。它的主要功能就是计算一个词语序列构成一个句子的概率,或者说计算一个词语序列的联合概率,这可以用来判断一句话出现的概率高不高,符不符合我们的表达习惯,它是否通顺,这句话是不是正确的。
语言模型可以用于机器翻译、语音识别、音字转换和文本校对等诸多NLP任务中,它可以从多个候选句子中选出一个最为靠谱的结果。
前面有一篇博文提到了统计语言模型《NLP-语言模型》,一个语言模型通常构建为字符串s的概率分布p(s),这里的p(s)实际上反映的是s作为一个句子出现的概率。这里的概率指的是组成字符串的这个组合,在训练语料中出现的似然,与句子是否合乎语法无关。假设训练语料来自于人类的语言,那么可以认为这个概率是的是一句话是否是人话的概率。
对于一个由T个词按顺序构成的句子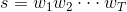 ,p(s)实际上求解的是字符串
,p(s)实际上求解的是字符串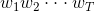 的联合概率,利用贝叶斯公式,链式分解如下:
的联合概率,利用贝叶斯公式,链式分解如下:
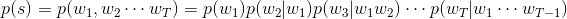
即
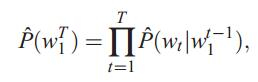
从上面可以看到,一个统计语言模型可以表示成,给定前面的的词,求后面一个词出现的条件概率。我们在求p(s)时实际上就已经建立了一个模型,这里的p(*)就是模型的参数,如果这些参数已经求解得到,那么很容易就能够得到字符串s的概率。
N-gram语言模型
上面直接计算的方法参数过多导致维度灾难。为了解决自由参数数目过多的问题,引入了马尔科夫假设:随意一个词出现的概率只与它前面出现的有限的n个词有关。基于上述假设的统计语言模型被称为N-gram语言模型。公式为:
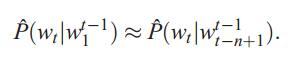
通常情况下,n的取值不能够太大,否则自由参数过多的问题依旧存在:
(1)当n=1时,即一个词的出现与它周围的词是独立,这种我们称为unigram,也就是一元语言模型,此时自由参数量级是词典大小V。
(2)当n=2时,即一个词的出现仅与它前面的一个词有关时,这种我们称为bigram,叫二元语言模型,也叫一阶马尔科夫链,此时自由参数数量级是V^2。
(3)当n=3时,即一个词的出现仅与它前面的两个词有关,称为trigram,叫三元语言模型,也叫二阶马尔科夫链,此时自由参数数量级是V^3。
一般情况下只使用上述取值,因为从上面可以看出,自由参数的数量级是n取值的指数倍。从模型的效果来看,理论上n的取值越大,效果越好。但随着n取值的增加,效果提升的幅度是在下降的。同时还涉及到一个可靠性和可区别性的问题,参数越多,可区别性越好,但同时单个参数的实例变少从而降低了可靠性。
N-gram虽然解决了参数过多的问题,但是还是存在数据稀疏的问题。假设有一个词组在训练语料中没有出现过,那么它的频次就为0。频次为零会导致该词组的概率为0,从而使整句话的概率为0,这显然是不合理的。因此N-gram需要进行数据平滑。
神经概率语言模型
上面提到的N-gram语言模型也有仍有不足之处,它没有考虑超过一两个的上下文,没考虑到单词之间的相似性,而且需要精心设计数据平滑方法。2003年,深度学习三巨头之一的Yoshua Bengio在论文《A Neural Probabilistic Language Model》中出了神经概率语言模型。主要思想是:
(1)将词表中每个词和一个分布式的词特征向量联系起来(Rm中的一个实数值的向量)。
(2)根据序列中这些单词的特征向量来表达单词序列的联合概率函数,
(3)同时学习词特征向量和该概率函数的参数。
特征向量代表单词的各个方面,每个单词都是向量空间中的一个点。相似的单词将有相似的特征向量由此模型得到泛化,概率函数是特征值的平滑函数,因此特征小的改变将不会造成概率大的改变。
神经概率语言模型其实应用了马尔可夫假设,即一个词出现的概率和前面的t个单词有关。该模型的公式如下:
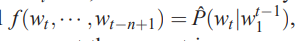
上式可以分解为两部分:
1. C是单词到分布式特征向量的映射
2. 联合概率:
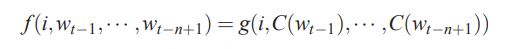
对应的神经网络模型为:
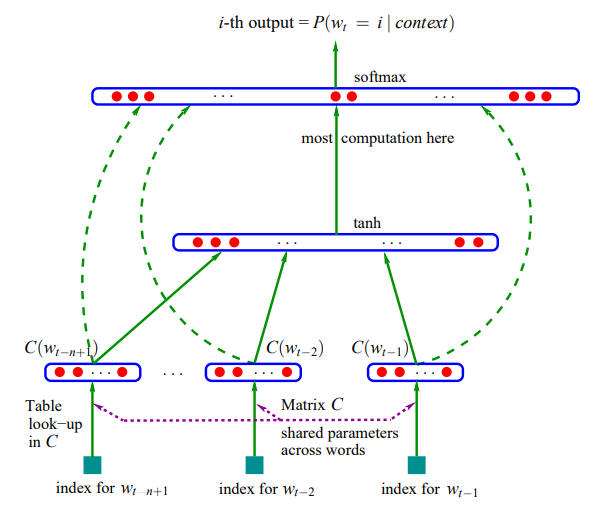
从上图可以看到,这个模型包含四个层:输入层、投影层、隐藏层和输出层。
输入层:这里就是词w的上下文,如果用N-gram的方法就是词w的前n-1个词。每一个词都作为一个长度为V的one-hot向量传入神经网络中
投影层:在投影层中,存在一个查找表C,C被表示成一个V*m的自由参数矩阵,其中V是词典的大小,而m是词向量的长度。C中每一行都作为一个词向量存在,这个词向量是每一个词的另一种分布式表示,每一个one-hot向量都经过表C的转化变成一个词向量。
n-1个词向量首尾相接的拼起来,转化为(n-1)m的列向量输入到下一层。
隐藏层:激活函数为tanh的非线性全连接层。
输出层:softmax层。
除了上面几个层之外,还有词向量直接连接到输出层的通路,但这并不是必要的,甚至去掉该通路结果更好。
得总的计算公式如下:
y=b+Wx+Utanh(d+Hx)
其中x是经过投影后的词向量,H是隐藏层参数,d是隐藏层偏置;U是输出层参数,b是输出层偏置。W是词向量直接连到输出通路的参数,但是矩阵并不是必要的。
论文中使用的参数优化方法是BP+SGD,W和H有权重惩罚因子而C没有。
训练上面的网络,则会得到一个基于神经网络的语言模型,即整个网络就是一个语言模型,基于n个已知单词可以预测序列的下一个单词。
训练这个网络除了得到一个语言模型之外,还得到一个表示各个单词的向量,即投影层参数矩阵C。C矩阵的每一行都是一个单词的词向量。有关词向量的更详细内容,可以参考下一篇博文《word2vec原理和实现》。
代码实现
使用中文维基百科作为数据集,网址为:https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2。
-
使用gensim库处理解压,并将数据写入txt
from gensim.corpora import WikiCorpus
input_file_name = r'D:\NLP\dataset\zhwiki-latest-pages-articles.xml.bz2'
output_file_name =r'D:\NLP\dataset\wiki.cn.txt'
input_file = WikiCorpus(input_file_name, lemmatize=False, dictionary={})
output_file = open(output_file_name, 'w', encoding="utf-8")
count = 0
#get_texts()将原文件中的文章转换为一个数组,使用for循环保存为txt文件
for text in input_file.get_texts():
output_file.write(' '.join(text) + '\n')
count = count + 1
if(count==10000):
break
output_file.close()2.维基百科多数是繁体内容,需要zhconv转换为简体内容
import zhconv
input_file_name = r'D:\NLP\dataset\wiki.cn.txt'
output_file_name = r'D:\NLP\dataset\wiki.cn.simple.txt'
input_file = open(input_file_name, 'r', encoding='utf-8')
output_file = open(output_file_name, 'w', encoding='utf-8')
lines = input_file.readlines()
count = 1
for line in lines:
output_file.write(zhconv.convert(line, 'zh-hans'))
count += 1
output_file.close()3.将原始语料分词
import jieba
input_file_name = r'D:\NLP\dataset\wiki.cn.simple.txt'
output_file_name = r'D:\NLP\dataset\wiki.cn.simple.separate.txt'
input_file = open(input_file_name, 'r', encoding='utf-8')
output_file = open(output_file_name, 'w', encoding='utf-8')
lines = input_file.readlines()
count = 1
for line in lines:
output_file.write(' '.join(jieba.cut(line.split('\n')[0].replace(' ', ''))) + '\n')
count += 1
output_file.close()4.语料中有很多英语单词和奇怪的符号,需要去除掉。通过正则表达式判断每一个词是不是符合汉字开头、汉字结尾、中间全是汉字,即“^[\u4e00-\u9fa5]+$”。
import re
input_file_name = r'D:\NLP\dataset\wiki.cn.simple.separate.txt'
output_file_name = r'D:\NLP\dataset\wiki.txt'
input_file = open(input_file_name, 'r', encoding='utf-8')
output_file = open(output_file_name, 'w', encoding='utf-8')
lines = input_file.readlines()
count = 1
cn_reg = '^[\u4e00-\u9fa5]+$'
for line in lines:
line_list = line.split('\n')[0].split(' ')
line_list_new = []
for word in line_list:
if re.search(cn_reg, word):
line_list_new.append(word)
#print(line_list_new)
output_file.write(' '.join(line_list_new) + '\n')
count += 1
if(count%1000==0):
print(count)
output_file.close()5.将字符串映射到数字序列
import tqdm
datafile=r'D:\NLP\dataset\wiki.txt'
with open(datafile,'r',encoding='utf-8') as f:
data=[]
raw_data=f.readlines()
for line in tqdm.tqdm(raw_data):
data.append(line.split())
print(len(data))from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
import numpy as np
import jieba
MAX_WORDS=10000#出于训练速度的考虑,这里只使用了前10000个单词
tokenizer=Tokenizer(num_words=MAX_WORDS-1)
tokenizer.fit_on_texts(texts=data)
word_index=tokenizer.word_index
re_word_index = dict([(i, t) for t, i in word_index.items()])
print(len(word_index))
seqList=tokenizer.texts_to_sequences(texts=data)6.定义网络
from keras.models import Sequential
from keras.layers import *
model=Sequential()
model.add(Embedding(MAX_WORDS, 100, input_length=6))#相当于6元模型
model.add(Flatten())
model.add(Dense(512,activation='tanh')) #隐层参数为512
model.add(Dense(MAX_WORDS, activation='softmax'))
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.summary()
7.训练模型
定义一个数据生成器,滑动窗口大小为wlen
def data_generator(wlen,batch_size=64):
while True:
x,y=[],[]
for sen in seqList:
for i in range(len(sen)-wlen-1):
x.append(sen[i:i+wlen])
y.append(sen[i+wlen])
if(len(x)==batch_size):
x= np.array(x)
yn=np.zeros((batch_size,MAX_WORDS))
for i,index in enumerate(y):
yn[i,index]=1
yield x,yn
x,y=[],[]
model.fit_generator(data_generator(6,batch_size=256),
steps_per_epoch =100000,
verbose=1,
epochs=2)8.模型测试
这里取出向量空间的中靠近的词向量作为测试结果。
#获取embeding的权重,也就是词向量
embeddings = model.get_weights()[0]
#向量标准化
normalized_embeddings = embeddings / (embeddings**2).sum(axis=1).reshape((-1,1))**0.5
def most_similar(w):
v = normalized_embeddings[word_index[w]]
#向量标准化之后分母就是1,所以直接相乘就好
sims = np.dot(normalized_embeddings, v)
sort = sims.argsort()[::-1]
sort = sort[sort > 0]
#如果是占位符则不输出
return [(re_word_index[i],sims[i]) for i in sort[:10] if i in re_word_index]
for sim in most_similar(u'美丽'):
print(sim[0],sim[1])测试结果:
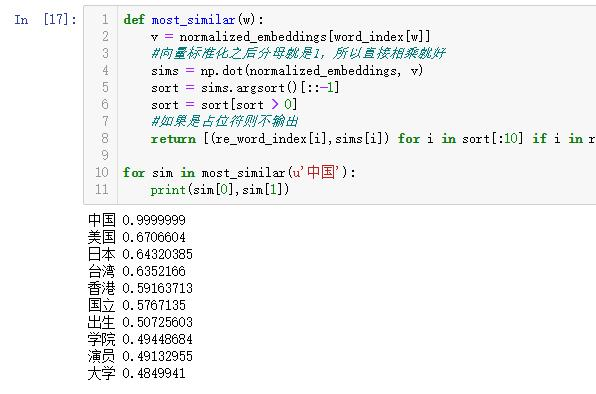
虽然训练的数据集小而且只训练两轮,但是还是看得出效果的。
个人博客:http://www.chenjianqu.com/
原文链接:http://www.chenjianqu.com/show-48.html
参考文献
[1]凌霄文强.基于word2vec使用中文wiki语料库训练词向量.https://www.jianshu.com/p/e21dd72e391e.2019-01-19
[2]就是杨宗.神经概率语言模型.https://www.jianshu.com/p/3f22fc76a9e5.2017-09-26
[3]Soyoger.自然语言处理之语言模型(LM).https://blog.csdn.net/qq_36330643/article/details/80143960. 2018-4-29

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)