爬虫-百度翻译爬虫
目标,完成百度翻译的爬虫输 入英文,可以得到中文的翻译内容第 一 步,寻找接口要找 到一个可以给我满意结果的网址1,进入目标网站开启调试模式关掉干拢的一些信息2 发 起一 个请求,激发一些接口的调用在xhr中接口出 现的 机会更 大一些3在众多接 口中寻找可能的一个通过比对我 们想要的内容 ,与接 口的 response的内容找到最 相近 的一个接口...
·
目标,完成百度翻译的爬虫
输 入英文,可以得到中文的翻译内容
第 一 步,寻找接口
要找 到一个可以给我满意结果的网址
1,进入目标网站
开启调试模式
关掉干拢的一些信息
2 发 起一 个请求,激发一些接口的调用
在xhr中接口出 现的 机会更 大一些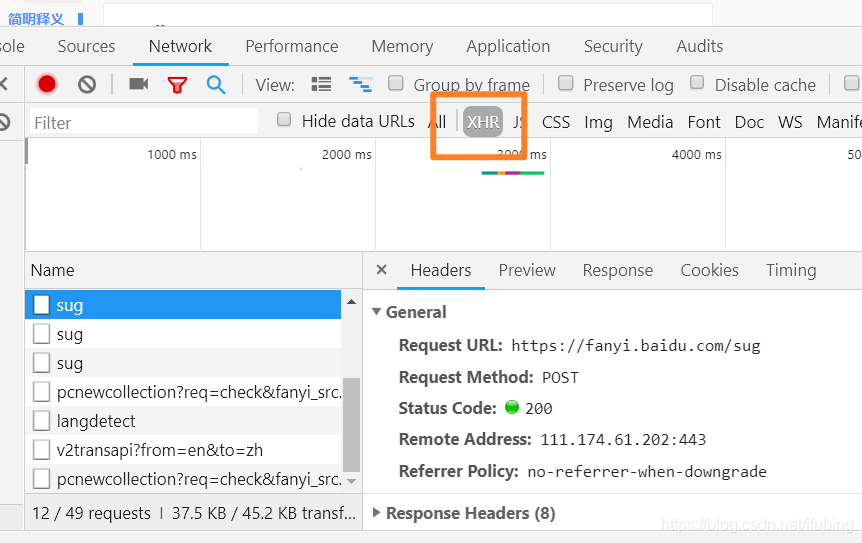
3 在众多接 口中寻找可能的一个
通过比对我 们想要的内容 ,与接 口的 response的内容
找 到最 相近 的一个接口
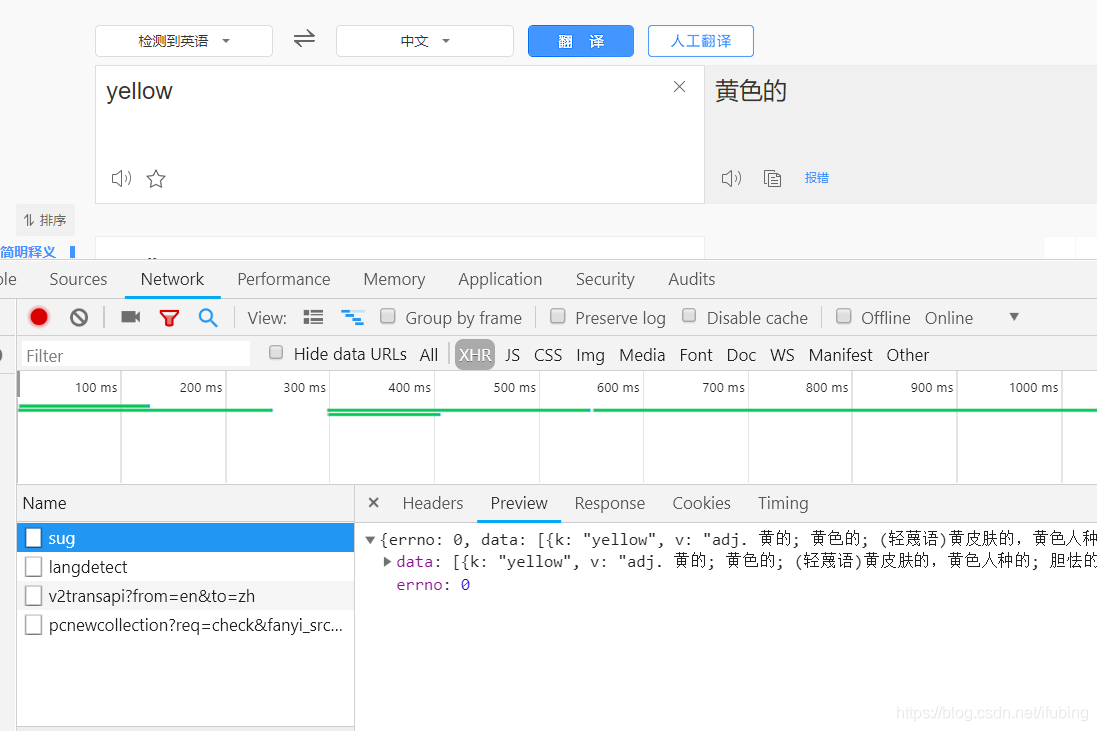
开始爬取数据,代码如下
import requests
import json
class Fanyi:
def __init__(self):
# 起始的网址
self.start_url = "https://fanyi.baidu.com/sug"
self.key = None
def run(self):
"""开始爬取数据"""
# 获取搜索关键词,让使用者来输入
self.key = input("请输入要搜索的单词:")
# 发起请求,获取响应
con = self.parse_url(self.start_url)
# 提取数据
res,xl_res = self.get_res(con)
# 打 印 数 据
print("{}的翻译结果是{}".format(self.key,res['v']))
print('相近的单词有:')
for r in xl_res:
print(r['k'],r['v'])
def parse_url(self, start_url):
data = {"kw": self.key}
tou = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36user-agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"}
response = requests.post(start_url, params=data, headers=tou)
con = response.content.decode()
print('con', con)
return con
def get_res(self, con):
"""提取翻译的结果"""
con_dict = json.loads(con)
data_list = con_dict["data"]
res = data_list[0]
lx_res = data_list[1:]
return res,lx_res
fy = Fanyi()
fy.run()

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)