02 requests参数请求 & 贴吧爬虫示例
requests获取响应# coding=utf-8import requestsfrom urllib import parseheaders = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:79.0) Gecko/20100101 Firefox/79.0"}p = {"wd": "太阳"}url = "https:
·
requests获取响应
# coding=utf-8 import requests from urllib import parse headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:79.0) Gecko/20100101 Firefox/79.0" } p = {"wd": "太阳"} url = "https://www.baidu.com/s?" r = requests.get(url=url, headers=headers, params=p) print(r.status_code) print(r.request.url) # 获得编码字符串 print(parse.unquote(r.request.url)) # 获得解码字符串运行结果:

实例应用
要求: 实现任意贴吧的爬虫,保存网页到本地!
我们以爬取lol贴吧为例, 爬取内容;
程序:
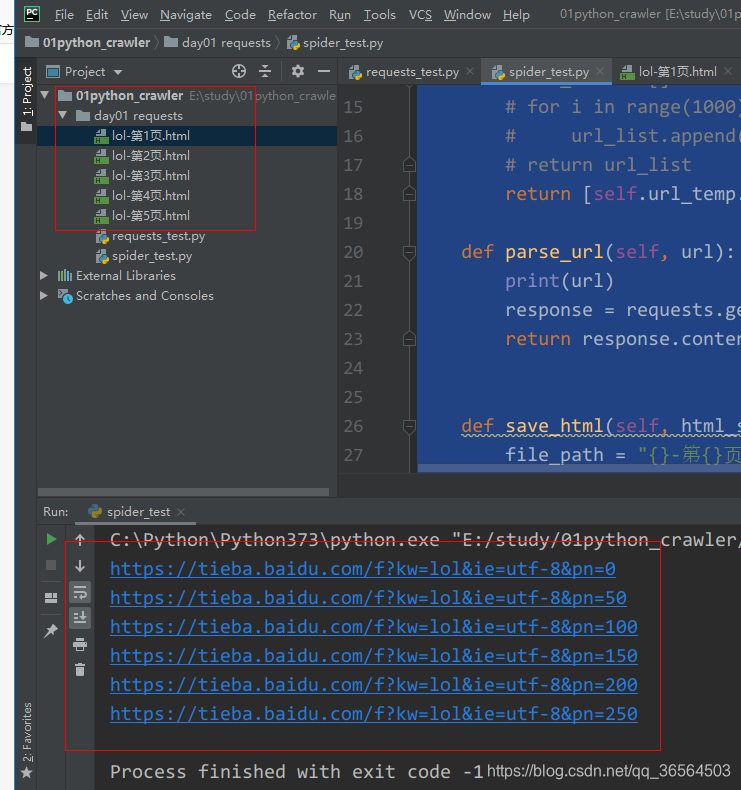
# coding=utf-8 # 爬取百度贴吧的内容 import requests class TieBaSpider: def __init__(self, tieba_name): self.tieba_name = tieba_name self.url_temp = "https://tieba.baidu.com/f?kw=" + tieba_name + "&ie=utf-8&pn={}" self.headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"} def get_url_list(self): # 构造url列表 # url_list = [] # for i in range(1000): # url_list.append(self.url_temp.format(i*50)) # 该贴吧页码是50的倍数 # return url_list return [self.url_temp.format(i * 50) for i in range(1000)] def parse_url(self, url): # 发送请求获取响应 print(url) response = requests.get(url, headers=self.headers) return response.content.decode() def save_html(self, html_str, page_num): # 保存 html字符串 file_path = "{}-第{}页.html".format(self.tieba_name, page_num) with open(file_path, "w", encoding="utf-8") as f: # '李毅-第一页.html' f.write(html_str) def run(self): # 实现主要逻辑 # 1.构造url列表 url_list = self.get_url_list() # 2.遍历,发送请求,获取响应 for url in url_list: html_str = self.parse_url(url) # 3.保存 page_num = url_list.index(url) + 1 # 页码数 self.save_html(html_str, page_num) if __name__ == '__main__': tieba = TieBaSpider("lol") tieba.run()运行结果:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)