【机器学习】案例:探究用户对物品类别的喜好细分
案例:探究用户对物品类别的喜好细分学习目标1. 需求2. 分析3. 完整代码3.1 获取数据3.2 数据基本处理3.2.1 合并表格3.2.2 交叉表合并3.2.3 数据截取3.3 特征工程 — pca3.4 机器学习(k-means)3.5 模型评估学习目标应用pca和K-means实现用户对物品类别的喜好细分划分数据如下:order_products__prior.csv:订单与商品信息字段:
·
案例:探究用户对物品类别的喜好细分
学习目标
- 应用pca和K-means实现用户对物品类别的喜好细分划分

数据如下:
- order_products__prior.csv:订单与商品信息
- 字段:order_id, product_id, add_to_cart_order, reordered
- products.csv:商品信息
- 字段:product_id, product_name, aisle_id, department_id
- orders.csv:用户的订单信息
- 字段:order_id,user_id,eval_set,order_number,….
- aisles.csv:商品所属具体物品类别
- 字段: aisle_id, aisle
1. 需求

2. 分析
- 1.获取数据
- 2.数据基本处理
- 2.1 合并表格
- 2.2 交叉表合并
- 2.3 数据截取
- 3.特征工程 — pca
- 4.机器学习(k-means)
- 5.模型评估
- sklearn.metrics.silhouette_score(X, labels)
- 计算所有样本的平均轮廓系数
- X:特征值
- labels:被聚类标记的目标值
- sklearn.metrics.silhouette_score(X, labels)
3. 完整代码
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
3.1 获取数据
order_product = pd.read_csv('./data/instacart/order_products__prior.csv')
products = pd.read_csv('./data/instacart/products.csv')
orders = pd.read_csv('./data/instacart/orders.csv')
aisles = pd.read_csv('./data/instacart/aisles.csv')
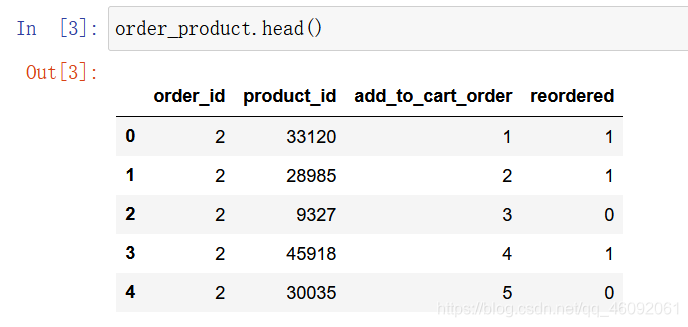
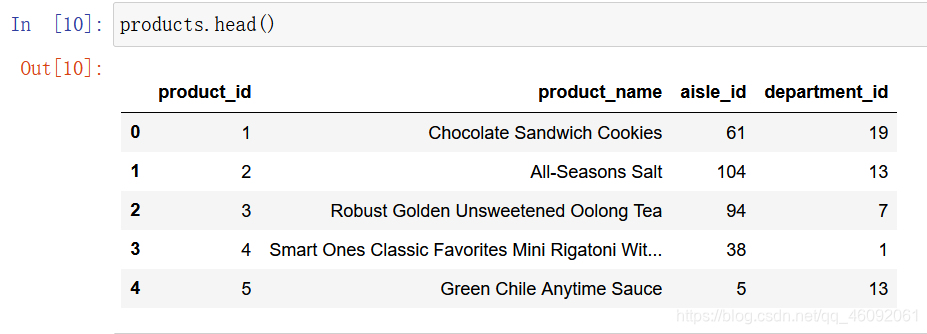
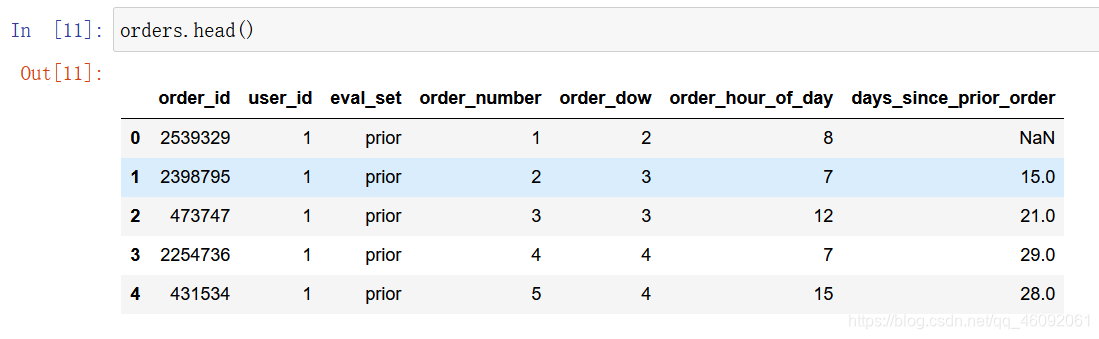
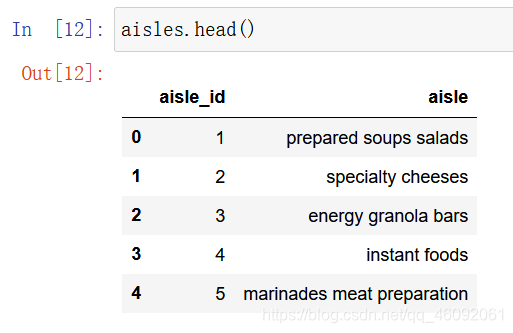
3.2 数据基本处理
3.2.1 合并表格
# 2.1 合并表格
table1 = pd.merge(order_product, products, on=["product_id", "product_id"])
table2 = pd.merge(table1, orders, on=["order_id", "order_id"])
table = pd.merge(table2, aisles, on=["aisle_id", "aisle_id"])
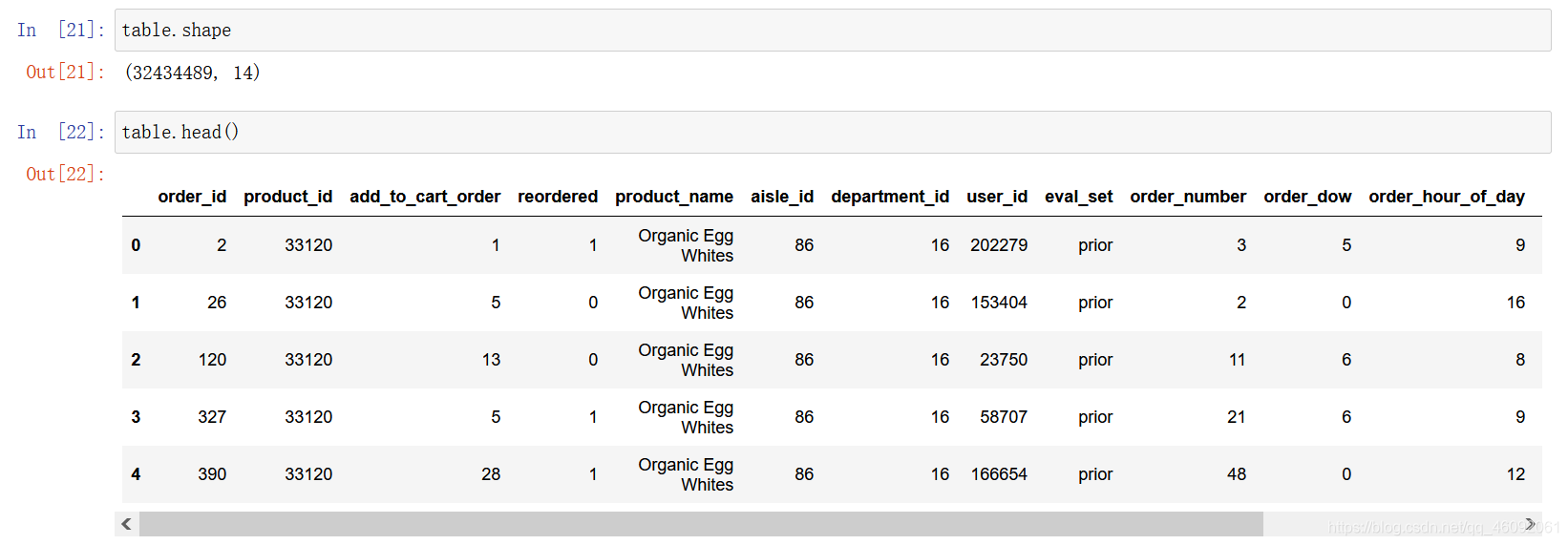
3.2.2 交叉表合并
table = pd.crosstab(table["user_id"], table["aisle"])
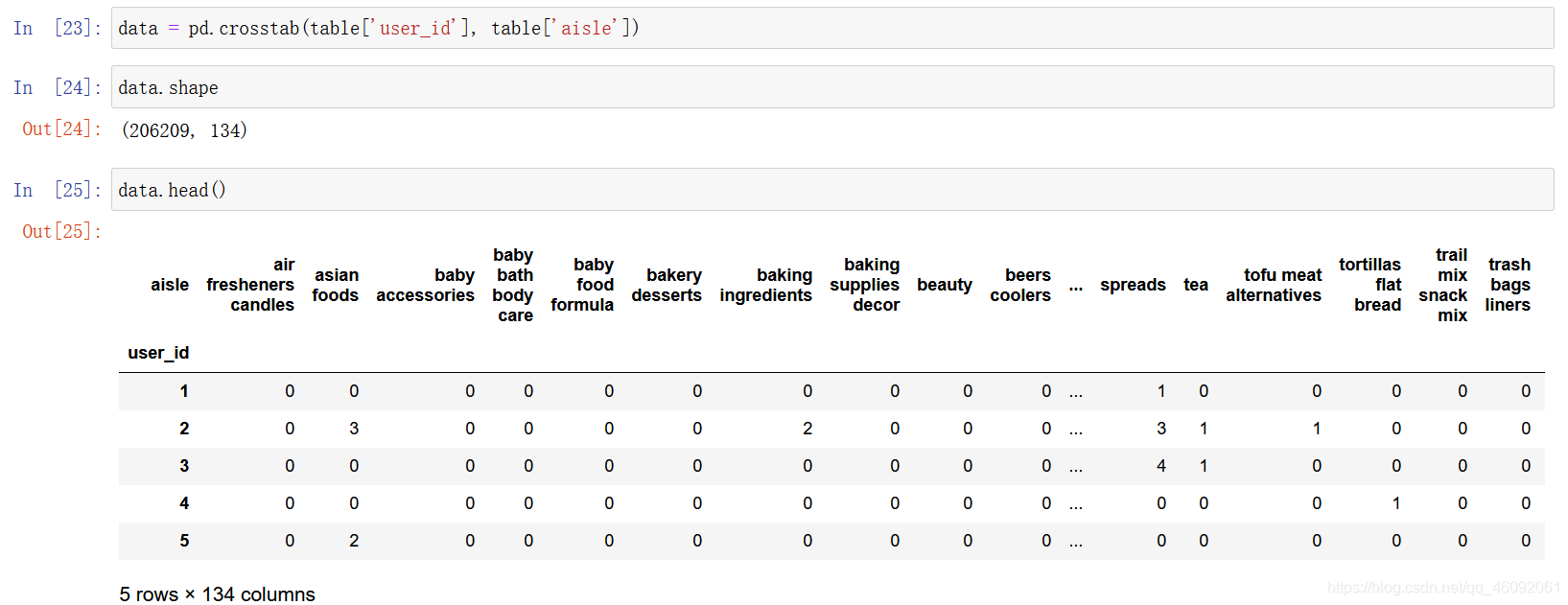
3.2.3 数据截取
table = table[:1000]
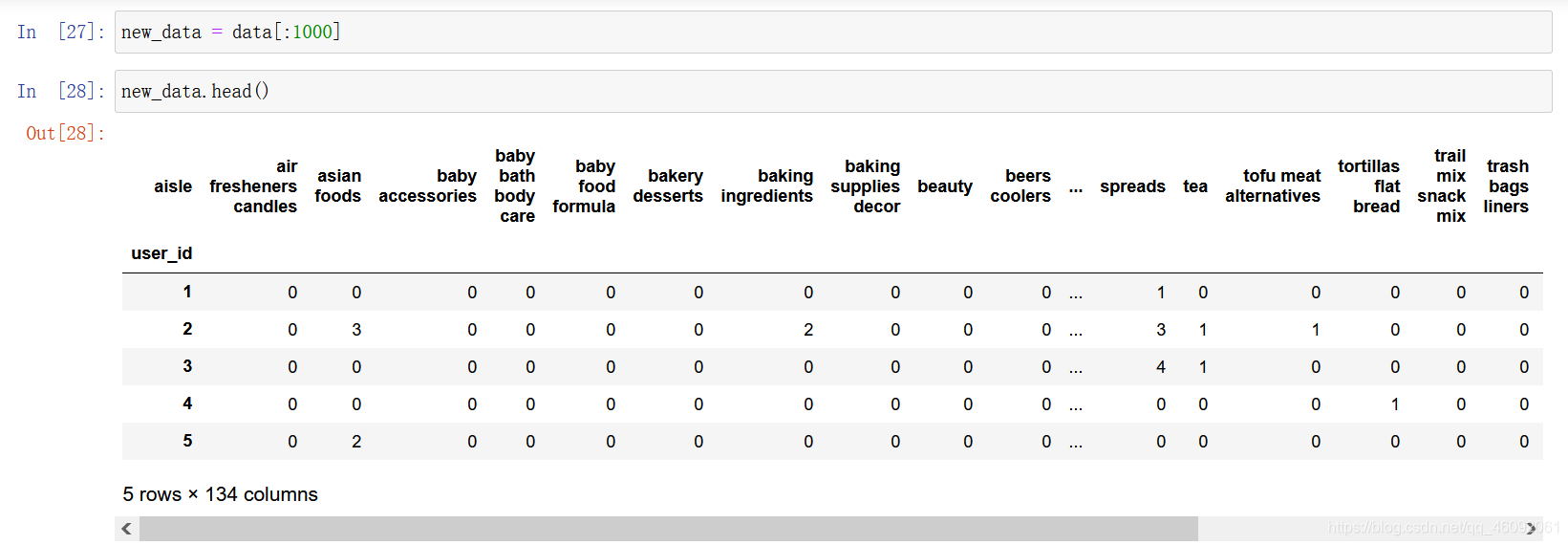
3.3 特征工程 — pca
transfer = PCA(n_components=0.9)
trans_data = transfer.fit_transform(new_data)
数据降维,减小复杂度,保留%90的数据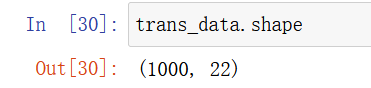
3.4 机器学习(k-means)
estimator = KMeans(n_clusters=5)
y_pre = estimator.fit_predict(trans_data)

3.5 模型评估
silhouette_score(trans_data, y_pre) # 越渐进

加油!
感谢!
努力!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 6
6 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)