机器学习新范式:Kubernetes + Kubeflow,解锁模型训练与部署的高效密码
使用Kubernetes部署PyTorch框架实现分布式训练和部署,并结合Kubeflow构建端到端的机器学习管道,是一个高效、可靠且可扩展的解决方案。它充分利用了Kubernetes的容器编排能力和Kubeflow的机器学习工具链优势,为机器学习模型的训练与部署提供了全流程的自动化支持。
1、Kubernetes在机器学习模型训练与部署中的作用
Kubernetes作为一个强大的容器编排平台,为机器学习模型的训练与部署提供了以下核心支持:
- 分布式训练支持:Kubernetes能够自动化部署和管理PyTorch等机器学习框架的分布式训练任务。通过利用多节点集群的计算资源,Kubernetes可以显著加速模型的训练过程,提高资源利用率。
- 弹性伸缩能力:根据训练任务的负载情况,Kubernetes可以自动扩展或收缩容器实例的数量。这确保了资源的高效利用,同时避免了资源浪费。
- 任务编排与管理:Kubernetes支持定义任务依赖关系和执行顺序,可以自动化执行复杂的数据处理和机器学习流程。这包括数据清洗、模型训练、评估和部署等各个环节。
- 资源调度与优化:Kubernetes能够根据资源需求(如CPU、内存、GPU)自动调度和分配计算资源,确保训练任务的高效运行。同时,它还可以优化资源使用,避免资源冲突和浪费。
2、Kubeflow的功能与优势
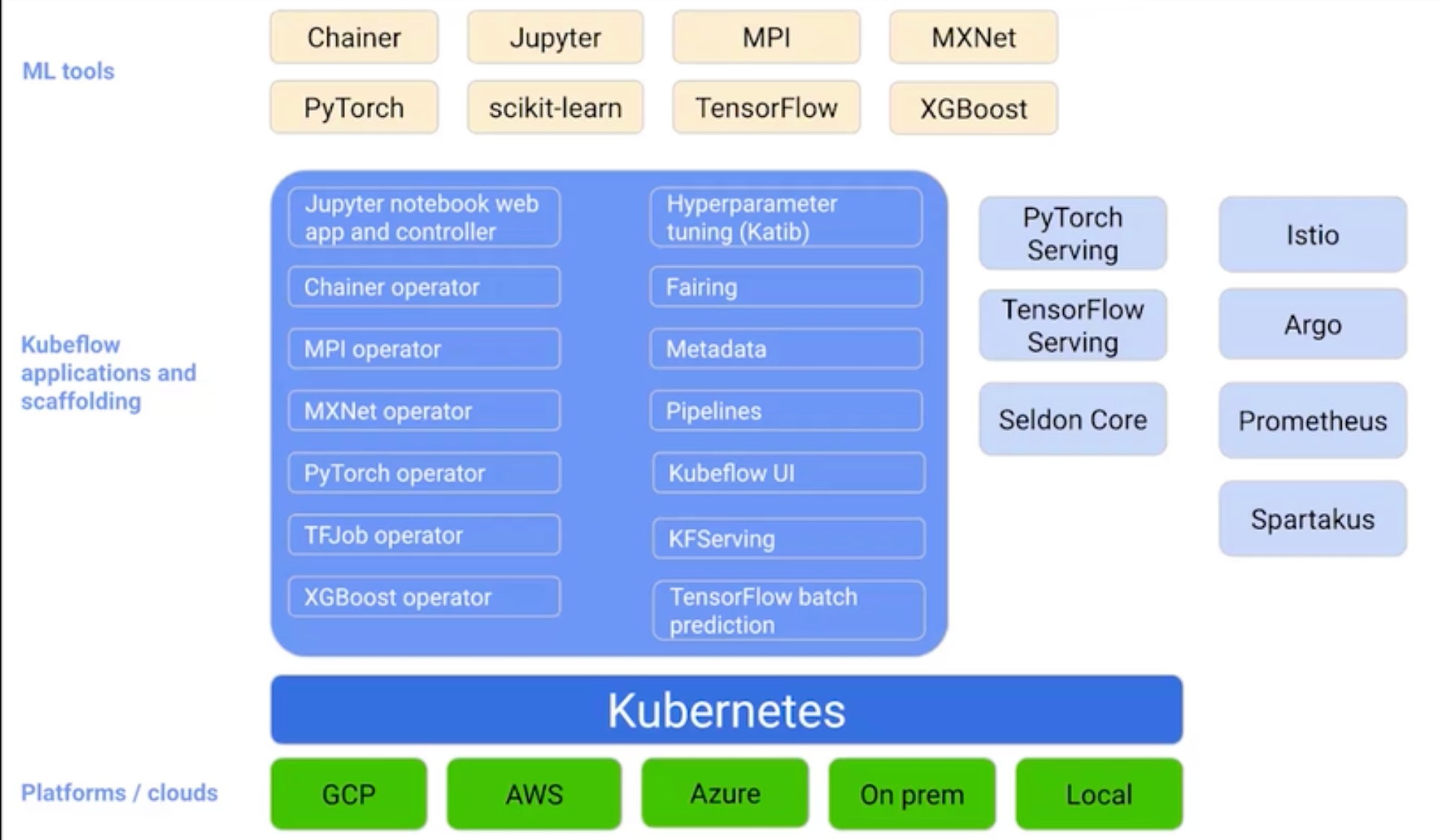
Kubeflow是一个专门为Kubernetes上的机器学习模型设计的工具包,它简化了机器学习管道的构建和管理。Kubeflow的主要功能和优势包括:
- 端到端机器学习管道:Kubeflow提供了一个端到端的平台,用于编排可重复使用的机器学习工作流。这包括数据准备、模型训练、评估和部署等各个环节,实现了全流程的自动化。
- 可重用组件:Kubeflow允许用户将机器学习工作流拆分为可重用的组件。这些组件可以是数据预处理、特征工程、模型训练或评估等任何步骤。通过组件化,用户可以轻松构建复杂的工作流,并在不同的项目中重用这些组件。
- 可视化工作流:Kubeflow提供了一个直观的用户界面,允许用户以图形化的方式设计和监控工作流。这使得团队成员可以轻松理解工作流的结构和进度,提高了协作效率。
- 实验跟踪与管理:Kubeflow内置了实验跟踪功能,允许用户比较不同运行的结果,记录参数和指标。这有助于用户更好地管理机器学习实验,提高实验的可再现性和可靠性。
- 灵活的部署选项:Kubeflow可以作为Kubeflow平台的一部分安装,也可以作为独立服务部署。这为用户提供了灵活的部署选择,满足了不同场景的需求。
3、使用Kubeflow构建端到端机器学习管道的实际案例
以下演示一个使用 Iris 数据集的完整机器学习实例,该数据集是一个经典的多类分类问题(预测鸢尾花的种类)。我们将构建一个 Kubeflow Pipeline,涵盖从数据准备、模型训练、评估到在线部署的整个流程。该示例实现了多步可重用组件的构建:每个步骤(如数据加载和模型训练)都被封装成独立的组件,便于在其他管道中重用。
3.1 总体流程概述
- 组件重用设计:使用 Kubeflow Pipelines SDK (kfp) 定义组件,每个组件基于 Docker 镜像运行,并通过 artifacts(如 CSV 文件或模型文件)传递数据。这确保组件可独立复用,例如数据准备组件可用于其他数据集。
- 管道构建:管道以 Python 代码形式定义,编译成 YAML 文件,然后上传到 Kubeflow 仪表板执行。
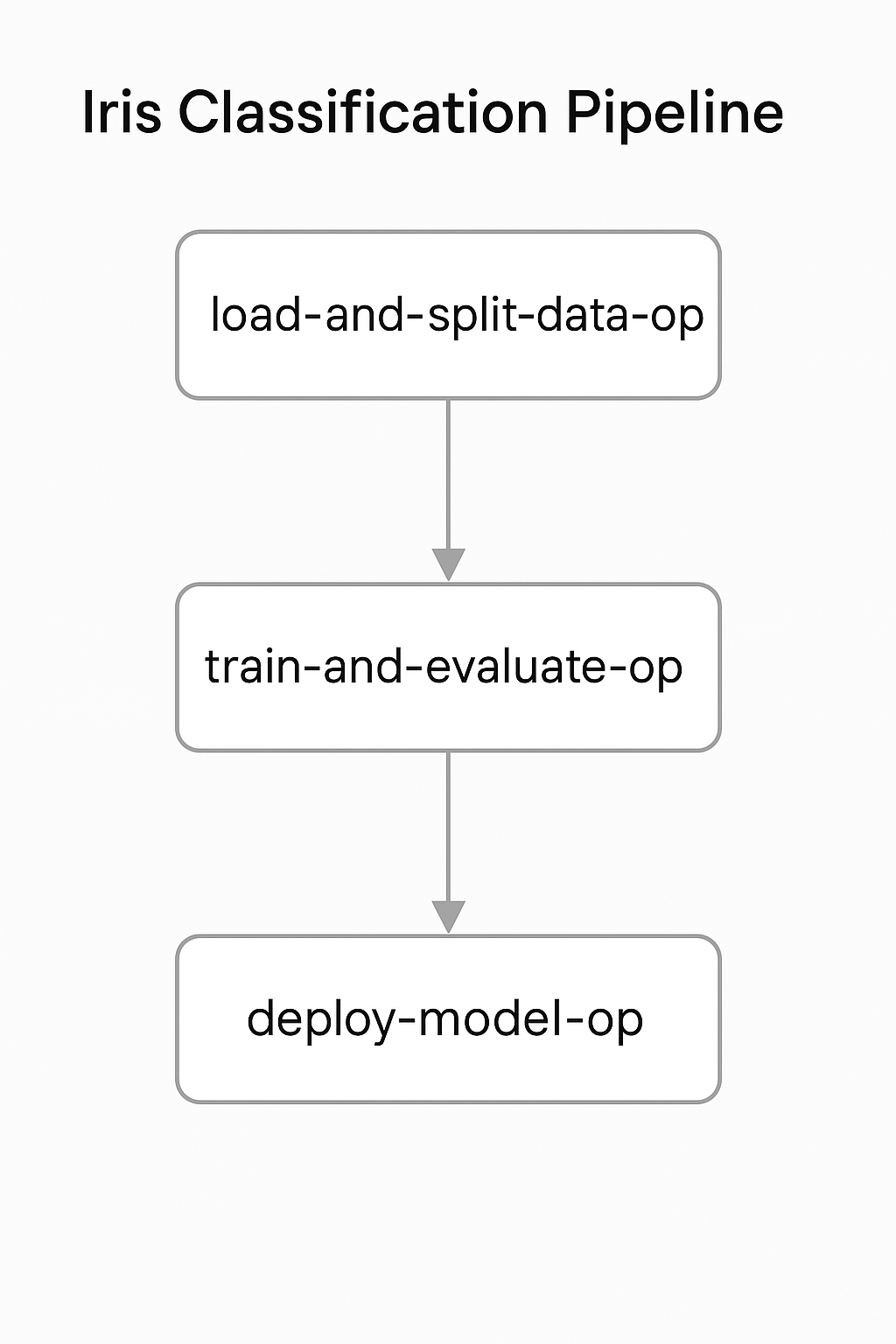
3.2 详细步骤
- 安装和导入 SDK(假设在本地环境):
pip install kfp # Kubeflow Pipelines SDK import kfp from kfp import dsl - 定义可重用组件:
- 数据准备组件:加载 Iris 数据集,拆分成训练集和测试集,并保存为 artifacts。
@dsl.component def load_and_split_data_op(output_train: dsl.OutputPath(str), output_test: dsl.OutputPath(str)): from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split import pandas as pd iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['target'] = iris.target train, test = train_test_split(df, test_size=0.2) train.to_csv(output_train, index=False) test.to_csv(output_test, index=False) - 模型训练和评估组件:加载数据,训练随机森林模型,评估准确率,并输出模型 artifact。
@dsl.component def train_and_evaluate_op(train_path: dsl.InputPath(str), test_path: dsl.InputPath(str), model_output: dsl.OutputPath(str)): import pandas as pd from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score import joblib train = pd.read_csv(train_path) test = pd.read_csv(test_path) X_train, y_train = train.drop('target', axis=1), train['target'] X_test, y_test = test.drop('target', axis=1), test['target'] model = RandomForestClassifier() model.fit(X_train, y_train) predictions = model.predict(X_test) accuracy = accuracy_score(y_test, predictions) print(f"Accuracy: {accuracy}") joblib.dump(model, model_output) - 部署组件:使用 Kubeflow 的服务组件(如 KFServing 或 Seldon)将模型部署为在线服务。这里简化为上传模型到存储并创建推理服务。
@dsl.component def deploy_model_op(model_path: dsl.InputPath(str)): # 模拟部署:实际中集成 KFServing print(f"Model deployed from {model_path}") # 在实际环境中,使用 kserve 或类似工具创建 InferenceService
- 数据准备组件:加载 Iris 数据集,拆分成训练集和测试集,并保存为 artifacts。
- 构建管道:
@dsl.pipeline(name='Iris Classification Pipeline') def iris_pipeline(): data_op = load_and_split_data_op() train_op = train_and_evaluate_op(train_path=data_op.outputs['output_train'], test_path=data_op.outputs['output_test']) deploy_op = deploy_model_op(model_path=train_op.outputs['model_output']) # 编译管道为 YAML kfp.compiler.Compiler().compile(iris_pipeline, 'iris_pipeline.yaml') - 执行和部署:
- 将 iris_pipeline.yaml 上传到 Kubeflow 仪表板。
- 在 UI 中可视化 DAG 图,运行管道。
- 管道执行后,模型被部署为在线端点,可通过 API 调用预测(如 POST 请求发送花瓣数据)。
上面的代码等下如下yaml文件
pipelineSpec: # 这部分定义了整个管道的规范,包括组件、部署、根DAG等
components: # 定义管道中的组件,对应Python代码中的@dsl.component函数
comp-deploy-model-op: # 对应deploy_model_op组件
executorLabel: exec-deploy-model-op
inputDefinitions: # 输入定义
artifacts: # 组件的输入artifacts
model_path: # 对应model_path输入参数
artifactType:
instanceSchema: |-
title: kfp.Artifact
type: object
properties: {}
comp-load-and-split-data-op: # 对应load_and_split_data_op组件
executorLabel: exec-load-and-split-data-op
outputDefinitions: # 输出定义
artifacts: # 组件的输出artifacts
output_test: # 对应output_test输出路径
artifactType:
instanceSchema: |-
title: kfp.Artifact
type: object
properties: {}
output_train: # 对应output_train输出路径
artifactType:
instanceSchema: |-
title: kfp.Artifact
type: object
properties: {}
comp-train-and-evaluate-op: # 对应train_and_evaluate_op组件
executorLabel: exec-train-and-evaluate-op
inputDefinitions: # 输入定义
artifacts: # 组件的输入artifacts
test_path: # 对应test_path输入路径
artifactType:
instanceSchema: |-
title: kfp.Artifact
type: object
properties: {}
train_path: # 对应train_path输入路径
artifactType:
instanceSchema: |-
title: kfp.Artifact
type: object
properties: {}
outputDefinitions: # 输出定义
artifacts: # 组件的输出artifacts
model_output: # 对应model_output输出路径
artifactType:
instanceSchema: |-
title: kfp.Artifact
type: object
properties: {}
deploymentSpec: # 定义执行器的部署规格,对应每个组件的运行环境
executors: # 执行器列表
exec-deploy-model-op: # 对应deploy_model_op的执行器
container: # 容器配置
command: # 启动命令,用于运行组件代码
- python3
- -m
- kfp.dsl.executor_main
- --component_module_base64
- <base64 encoded deploy_model_op Python function code> # 这里是base64编码的deploy_model_op函数代码(实际编译时替换)
image: python:3.9-slim # Docker镜像,对应组件运行环境
exec-load-and-split-data-op: # 对应load_and_split_data_op的执行器
container:
command:
- python3
- -m
- kfp.dsl.executor_main
- --component_module_base64
- <base64 encoded load_and_split_data_op Python function code> # base64编码的load_and_split_data_op函数代码
image: python:3.9-slim
exec-train-and-evaluate-op: # 对应train_and_evaluate_op的执行器
container:
command:
- python3
- -m
- kfp.dsl.executor_main
- --component_module_base64
- <base64 encoded train_and_evaluate_op Python function code> # base64编码的train_and_evaluate_op函数代码
image: python:3.9-slim
pipelineInfo: # 管道元信息
name: Iris Classification Pipeline # 对应@dsl.pipeline(name='Iris Classification Pipeline')
root: # 管道的根结构,包括DAG
dag: # 有向无环图,定义任务依赖
tasks: # 任务列表,对应管道中的步骤
deploy-model-op: # 对应deploy_op = deploy_model_op(...)
cachingOptions:
enableCache: true # 启用缓存
componentRef:
name: comp-deploy-model-op # 引用组件
dependentTasks: # 依赖的任务
- train-and-evaluate-op # 依赖train-and-evaluate-op,对应Python中的deploy_op依赖train_op
inputs: # 输入
artifacts:
model_path: # 输入artifact
taskOutputArtifact: # 来自上游任务的输出
outputArtifactKey: model_output # 来自model_output
producerTask: train-and-evaluate-op # 来自train-and-evaluate-op
taskInfo:
name: deploy-model-op # 任务名称
load-and-split-data-op: # 对应data_op = load_and_split_data_op()
cachingOptions:
enableCache: true
componentRef:
name: comp-load-and-split-data-op
taskInfo:
name: load-and-split-data-op
train-and-evaluate-op: # 对应train_op = train_and_evaluate_op(...)
cachingOptions:
enableCache: true
componentRef:
name: comp-train-and-evaluate-op
dependentTasks: # 依赖的任务
- load-and-split-data-op # 依赖load-and-split-data-op,对应Python中的train_op依赖data_op
inputs: # 输入
artifacts:
test_path: # 输入artifact
taskOutputArtifact:
outputArtifactKey: output_test # 来自output_test
producerTask: load-and-split-data-op # 来自load-and-split-data-op
train_path: # 输入artifact
taskOutputArtifact:
outputArtifactKey: output_train # 来自output_train
producerTask: load-and-split-data-op # 来自load-and-split-data-op
taskInfo:
name: train-and-evaluate-op
schemaVersion: 2.1.0 # KFP schema版本
sdkVersion: kfp-2.0.0 # SDK版本,对应使用的kfp版本在这个实例中,由于 Iris 数据集简单,准确率通常达 95% 以上(示例中可能达 100%)。组件的重用体现在:数据准备组件可复用于其他分类任务,训练组件可换成其他算法。
4、PyTorch分布式训练在Kubernetes上的实现
在Kubernetes上部署PyTorch实现分布式训练,可以使用Kubeflow提供的PytorchJob资源。PytorchJob是一种原生Kubernetes资源类型,用于在Kubernetes集群中部署和管理PyTorch训练任务。以下是一个简单的
4.1 PytorchJob YAML文件示例
# apiVersion 指定了要创建的 Kubernetes 对象的 API 版本。
# 对于 Kubeflow 的 PyTorchJob,通常使用 kubeflow.org/v1。
apiVersion: kubeflow.org/v1
# kind 指定了要创建的 Kubernetes 对象的类型。
# 这里我们创建的是一个 PyTorchJob。
kind: PyTorchJob
# metadata 包含了关于该对象的元数据,例如名称和命名空间。
metadata:
# name 是此 PyTorchJob 在指定命名空间内的唯一标识符。
name: pytorch-job-example
# namespace 指定了此 Job 将在哪个 Kubernetes 命名空间中创建和运行。
# 如果省略,则使用默认的命名空间(通常是 'default')。
namespace: default
# spec 定义了 PyTorchJob 的期望状态和配置。
spec:
# cleanPodPolicy 定义了 Job 完成(成功或失败)后如何处理其创建的 Pod。
# 'None' 表示 Job 完成后保留 Pod,便于调试和查看日志。
# 其他可选值包括 'Running'(只删除正在运行的 Pod)和 'All'(删除所有 Pod)。
cleanPodPolicy: None
# pytorchReplicaSpecs 定义了分布式 PyTorch 训练中不同角色的配置。
# 对于 PyTorchJob,通常需要定义 'Master' 和 'Worker' 角色。
pytorchReplicaSpecs:
# Master 定义了 Master 角色的配置。Master 通常负责协调训练过程。
Master:
# replicas 指定了要创建的 Master Pod 的数量。对于 PyTorch 分布式训练,通常只需要一个 Master。
replicas: 1
# restartPolicy 定义了当 Pod 中的容器退出时,Kubernetes 应采取的操作。
# 'OnFailure' 表示只有在容器以非零状态码退出(即失败)时才尝试重启容器。
# 其他常用值: 'Never'(从不重启),'Always'(总是重启)。
restartPolicy: OnFailure
# template 定义了用于创建 Master Pod 的 Pod 模板。这是一个标准的 Kubernetes PodTemplateSpec。
template:
# spec 定义了 Pod 的详细规格。
spec:
# containers 定义了在此 Pod 中运行的容器列表。
containers:
# name 是容器在此 Pod 内的唯一名称。
- name: pytorch
# image 指定了用于此容器的 Docker 镜像。
# 这里使用了包含 PyTorch 1.9.0、CUDA 11.1 和 cuDNN 8 的官方镜像。
image: pytorch/pytorch:1.9.0-cuda11.1-cudnn8-runtime
# command 指定了容器启动时要执行的主命令。
# 这会覆盖 Docker 镜像中定义的默认 ENTRYPOINT。
command: ["python", "/workspace/train.py"]
# args 是传递给上面 command 的参数列表。
# 这里传递了 '--epochs' 参数,值为 '10'。
args: ["--epochs", "10"]
# resources 定义了容器所需的计算资源(CPU、内存、GPU 等)以及限制。
resources:
# limits 定义了容器可以使用的资源上限。
limits:
# nvidia.com/gpu 指定了需要分配给此容器的 NVIDIA GPU 数量。
# 这里请求了 1 个 GPU。节点必须有可用的 GPU 资源并且配置了 NVIDIA device plugin。
nvidia.com/gpu: 1
# Worker 定义了 Worker 角色的配置。Worker 通常执行实际的训练计算任务。
Worker:
# replicas 指定了要创建的 Worker Pod 的数量。
# 这里配置了 2 个 Worker Pod,与 Master Pod 一起构成一个包含 3 个节点的分布式训练集群。
replicas: 2
# restartPolicy 定义了 Worker Pod 的重启策略,与 Master 类似。
restartPolicy: OnFailure
# template 定义了用于创建 Worker Pod 的 Pod 模板。
template:
# spec 定义了 Worker Pod 的详细规格。
spec:
# containers 定义了在 Worker Pod 中运行的容器列表。
containers:
# name 是 Worker 容器的名称。
- name: pytorch
# image 指定了 Worker 容器使用的 Docker 镜像。
# 通常 Worker 和 Master 使用相同的镜像以确保环境一致。
image: pytorch/pytorch:1.9.0-cuda11.1-cudnn8-runtime
# command 指定了 Worker 容器启动时要执行的主命令。
# 这通常与 Master 的命令相同,因为训练脚本内部会根据环境变量区分角色。
command: ["python", "/workspace/train.py"]
# args 是传递给 Worker 容器 command 的参数。
args: ["--epochs", "10"]
# resources 定义了 Worker 容器的资源请求和限制。
resources:
# limits 定义了 Worker 容器的资源上限。
limits:
# nvidia.com/gpu 指定了需要分配给每个 Worker 容器的 GPU 数量。
# 这里每个 Worker 也请求了 1 个 GPU。
nvidia.com/gpu: 1在这个示例中,定义了一个包含1个Master节点和2个Worker节点的PyTorch分布式训练任务。Master节点负责协调任务和数据分发,Worker节点负责执行训练任务。通过Kubernetes的自动化部署和管理,可以轻松地实现PyTorch模型的分布式训练。
4.2 Kubernetes 环境下的抽象拓扑
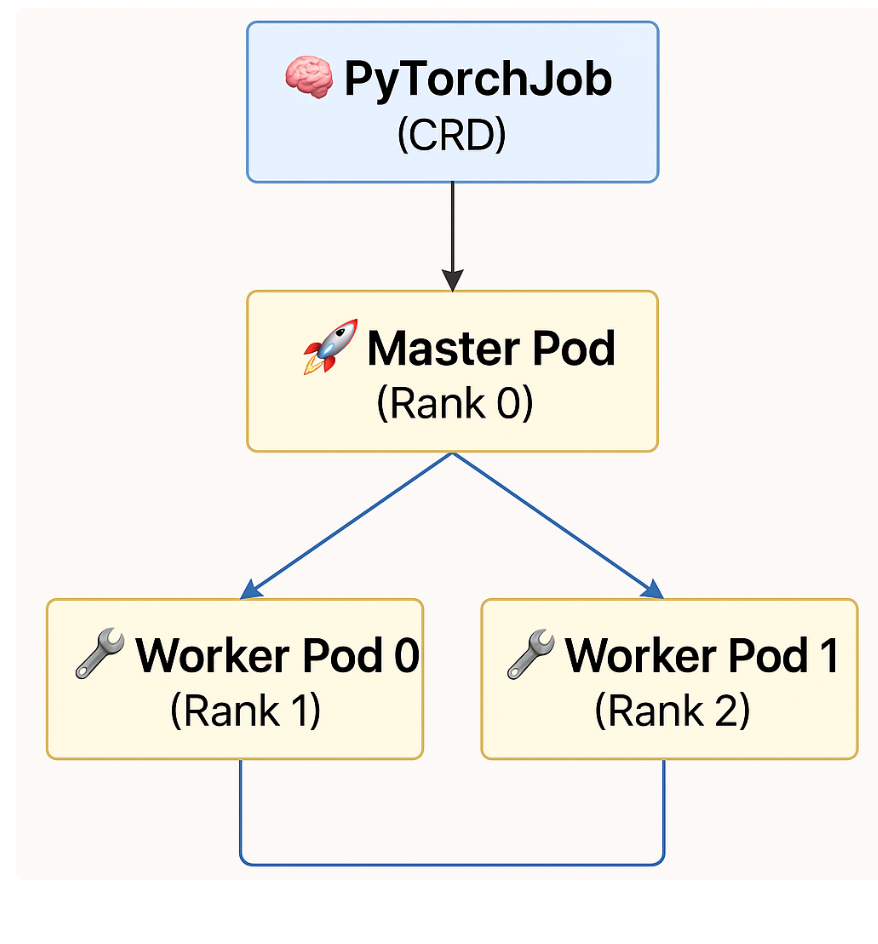
每一个 Pod 是一个训练节点,图中箭头代表进程间通信(如 NCCL、Gloo 通信):
Master 节点
是 rank=0 的主控节点,负责:
初始化训练(创建 TCP rendezvous)
协调 distributed backend(如 NCCL、Gloo)
控制 checkpoint 等操作
在 DDP 初始化时,其他 Worker 会连接到 Master。
Worker 节点
执行实际训练任务,与 Master 和其他 Worker 全量通信。
5 分布式训练总结
使用Kubernetes部署PyTorch框架实现分布式训练和部署,并结合Kubeflow构建端到端的机器学习管道,是一个高效、可靠且可扩展的解决方案。它充分利用了Kubernetes的容器编排能力和Kubeflow的机器学习工具链优势,为机器学习模型的训练与部署提供了全流程的自动化支持。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 14
14 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)