揭秘Ollama:一文读懂AI助手的“大脑”如何高效运转
引言还记得上一篇文章中,我们一起探索了如何用 Ollama 打造自己的私人 AI 助手吗?今天,让我们掀开 Ollama 的神秘面纱,一起深入了解它的"大脑"是如何运作的。就像解剖一台精密的机器,我们将逐层剖析 Ollama 的核心原理,看看它是如何让 AI 模型在你的电脑上高效运转的。系统架构想象一下,Ollama 就像一座精心设计的现代化工厂,每个部门都各司其职,又紧密配合。这座"AI工厂"采
引言
还记得上一篇文章中,我们一起探索了如何用 Ollama 打造自己的私人 AI 助手吗?今天,让我们掀开 Ollama 的神秘面纱,一起深入了解它的"大脑"是如何运作的。就像解剖一台精密的机器,我们将逐层剖析 Ollama 的核心原理,看看它是如何让 AI 模型在你的电脑上高效运转的。
系统架构
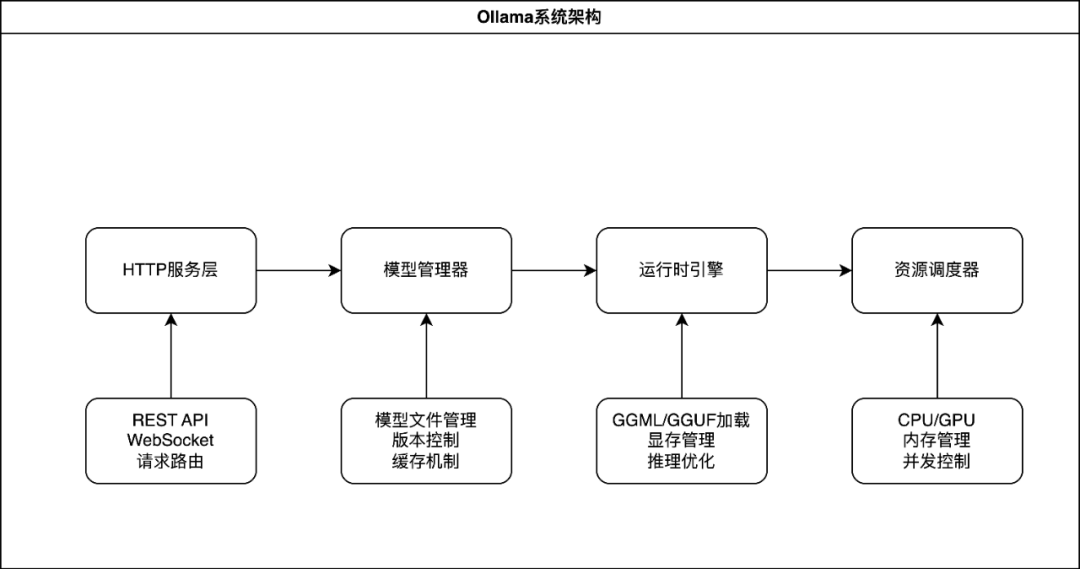
想象一下,Ollama 就像一座精心设计的现代化工厂,每个部门都各司其职,又紧密配合。这座"AI工厂"采用了模块化的架构设计,由以下几个核心部门构成:
-
1. HTTP 服务层 - 前台接待处
-
• REST API 接口设计:就像前台接待员,负责接收和回应访客的各种请求
-
• WebSocket 支持流式输出:像一条高速传送带,源源不断地传递信息
-
• 请求路由和处理:如同一位经验丰富的调度员,将不同的请求分发到相应的部门
2. 模型管理器 - 仓库管理中心
-
• 模型文件管理:像图书馆管理员,妥善保管各种AI模型
-
• 模型版本控制:记录每个模型的"成长历史"
-
• 缓存机制:在"快速取件区"存放常用模型,提高访问速度
3. 运行时引擎 - 核心生产车间
-
• GGML/GGUF 模型加载:就像启动精密的机器设备
-
• 显存管理:合理分配和使用GPU这个"超级计算工具"
-
• 推理优化:不断改进生产流程,提高效率
4. 资源调度器 - 总调度室
-
• CPU/GPU 资源分配:像一位精明的资源调度长,合理分配计算资源
-
• 内存管理:规划和管理"工作空间"
-
• 并发控制:协调多个任务同时进行,就像指挥交通一样有条不紊
工作流程
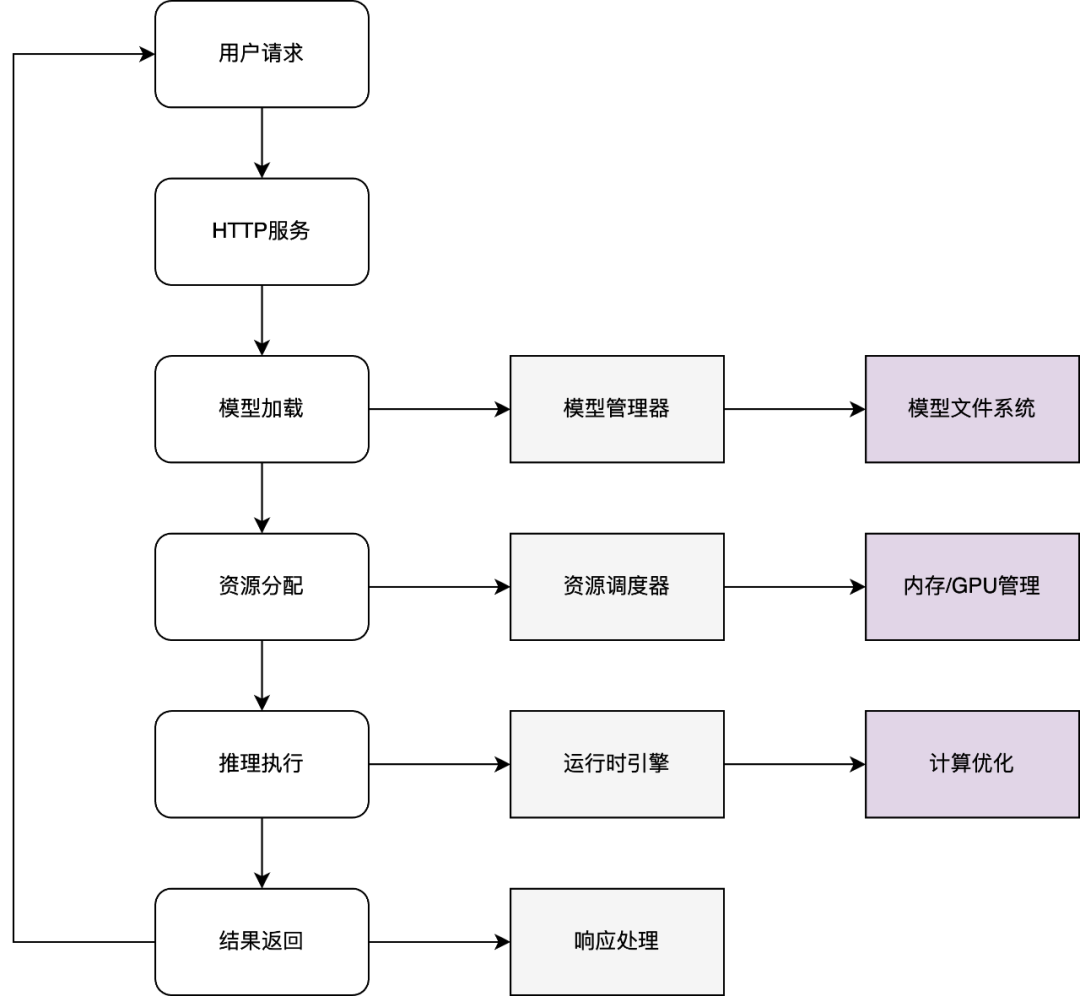
让我们跟随一个AI请求,看看它是如何在这座"智能工厂"中完成处理的:
推理过程
当我们向Ollama提出一个问题时,它的"思考过程"(推理过程)是这样的:
内存管理策略
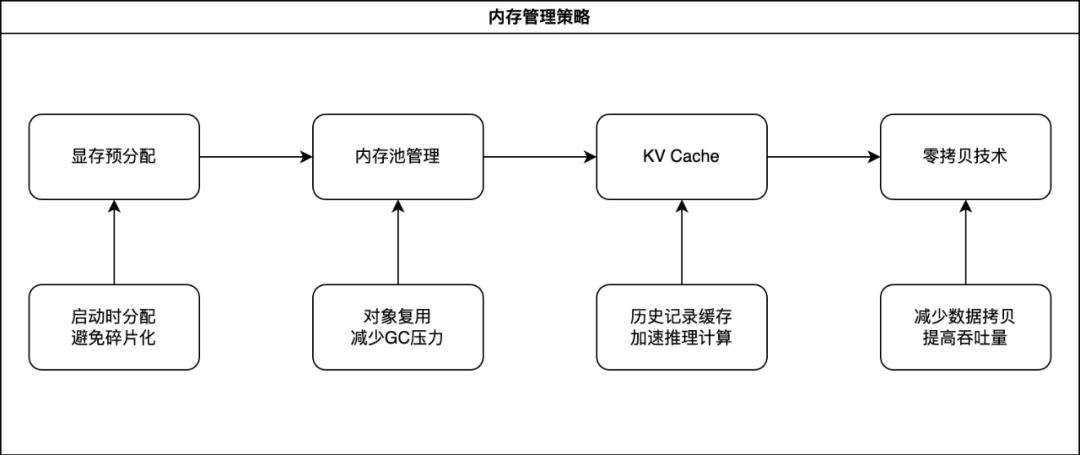
就像一个出色的管家需要把房间收拾得井井有条,Ollama也需要精心管理它的"记忆空间"。为了让AI模型运行得更快更流畅,Ollama设计了一套多层次的内存管理策略:
底层技术基石
在深入Ollama的核心原理之前,让我们先了解它赖以运行的"发动机"。就像汽车需要强劲的引擎才能高速行驶,Ollama也需要强大的底层支持才能高效运行AI模型。
1. GGML - 高性能推理引擎
GGML(Georgi Gerganov Machine Learning)是Ollama的核心计算引擎,就像一台精密的计算机器:
-
1. 核心特性
-
• 专为大语言模型优化的张量计算库
-
• 支持CPU和GPU混合计算
-
• 高效的内存管理机制
2. 关键优势
-
• 计算速度快:通过SIMD指令集优化
-
• 内存占用小:智能的内存复用策略
-
• 部署灵活:支持多种硬件平台
2. GGUF - 统一模型格式
GGUF(GGML Universal Format)是新一代的模型文件格式,就像一个智能的"容器":
-
1. 设计特点
-
• 统一的模型存储格式
-
• 支持元数据管理
-
• 灵活的版本控制
2. 主要优势
-
• 加载速度快:优化的文件结构
-
• 兼容性好:支持多种模型转换
-
• 体积更小:高效的数据组织
3. 技术协同
这些底层组件如何协同工作?想象一下:
-
• GGUF就像一个精心设计的"快递包装",将AI模型安全高效地存储
-
• GGML则是一个强大的"拆封处理中心",快速解析并运行模型
-
• Ollama在此基础上,通过优化调度和资源管理,实现了高效的本地AI服务
核心实现原理
有了这些强大的底层支持,让我们继续深入Ollama的"控制室",看看它的核心部件是如何协同工作的。
1. 模型文件管理 - AI模型的"衣柜管理员"
就像我们需要一个智能的衣柜管理系统来整理各种衣物一样,Ollama也需要一个高效的系统来管理各种AI模型。它采用了类似Docker的分层设计理念:
// 模型的基本结构
type Model struct {
Name string // 模型名称
Version string // 版本信息
Format string // 模型格式
Config ModelConfig // 模型配置
}这个"智能衣柜"的设计非常巧妙,它分为三层:
-
• 基础模型层:就像基础款衣物,存放模型的"原始材料"(权重数据)
-
• 配置层:相当于搭配指南,记录着模型的各种参数设置
-
• 自定义层:好比个性化定制,存放用户的特殊配置
2. 推理引擎优化 - 打造高效的"思考大脑"
为了让AI模型思考得又快又好,Ollama在性能上做了一系列精妙的优化:
-
1. 内存优化
-
• 提前规划和分配GPU显存空间,就像提前准备好工作台
-
• 智能管理内存使用,避免资源浪费
-
• 及时清理不需要的数据,保持系统运行流畅
2. 计算优化
-
• 采用批量处理机制,一次处理多个任务
-
• 使用并行计算技术,充分利用硬件性能
-
• 优化计算流程,减少不必要的运算
3. 并发控制 - AI的"多线程思维"
想象一下,如果你的大脑能同时处理多个任务,效率会提高多少?Ollama就实现了这样的"多线程思维"能力。它通过一个智能的任务调度系统,可以同时处理多个用户的请求:
-
1. 工作池机制
-
• 维护一组活跃的工作线程
-
• 合理分配计算资源
-
• 确保任务高效执行
2. 任务队列管理
-
• 有序处理用户请求
-
• 动态调整处理优先级
-
• 避免资源争抢
4. 量化处理 - AI模型的"减重计划"
就像我们需要将高清视频压缩后才能在手机上流畅播放,AI模型也需要"减重"才能在普通电脑上高效运行。Ollama支持多种"减重"(量化)策略:
// 量化配置
type QuantizationConfig struct {
Bits int // 量化位数(4/8位)
Strategy string // 量化策略
}-
1. 精度调整
-
• 4位量化:体积最小,适合资源受限场景
-
• 8位量化:平衡性能和精度
-
• 自适应量化:根据硬件条件智能选择
2. 智能压缩
-
• 保留重要权重参数
-
• 压缩次要数据
-
• 平衡模型大小和性能
性能优化策略
1. KV Cache 优化 - AI的"超级记忆力"
想象一下,如果每次回忆都要从头开始思考,那该多么低效。Ollama通过KV Cache(键值缓存)实现了高效的"记忆检索"机制:
-
1. 智能缓存系统
-
• 记住重要的中间计算结果
-
• 快速检索历史信息
-
• 动态更新缓存内容
2. 记忆管理
-
• 及时清理过期数据
-
• 保持记忆的新鲜度
-
• 优化存储空间使用
2. 推理性能优化 - 思维加速器
-
1. 智能批处理
-
• 将相似的问题打包处理,就像一次性处理一批相关的工作
-
• 多个任务共享计算资源,像拼车一样提高效率
-
• 减少GPU切换带来的时间浪费,就像减少工作环境的切换
2. 记忆空间优化
-
• 使用内存池,像共享工作空间一样高效利用内存
-
• 零拷贝技术,避免不必要的数据搬运
-
• 智能显存分配,让每一寸计算空间都物尽其用
实现细节 - 揭秘AI引擎的运作机制
1. 模型加载流程 - AI模型的"开机启动"
就像启动一台复杂的机器需要一系列准备工作,AI模型的加载也需要精心的步骤:
-
1. 文件读取
-
• 检查模型文件完整性
-
• 准备必要的系统资源
-
• 建立文件读取通道
2. 模型初始化
-
• 解析模型配置信息
-
• 加载模型权重数据
-
• 准备运行时环境
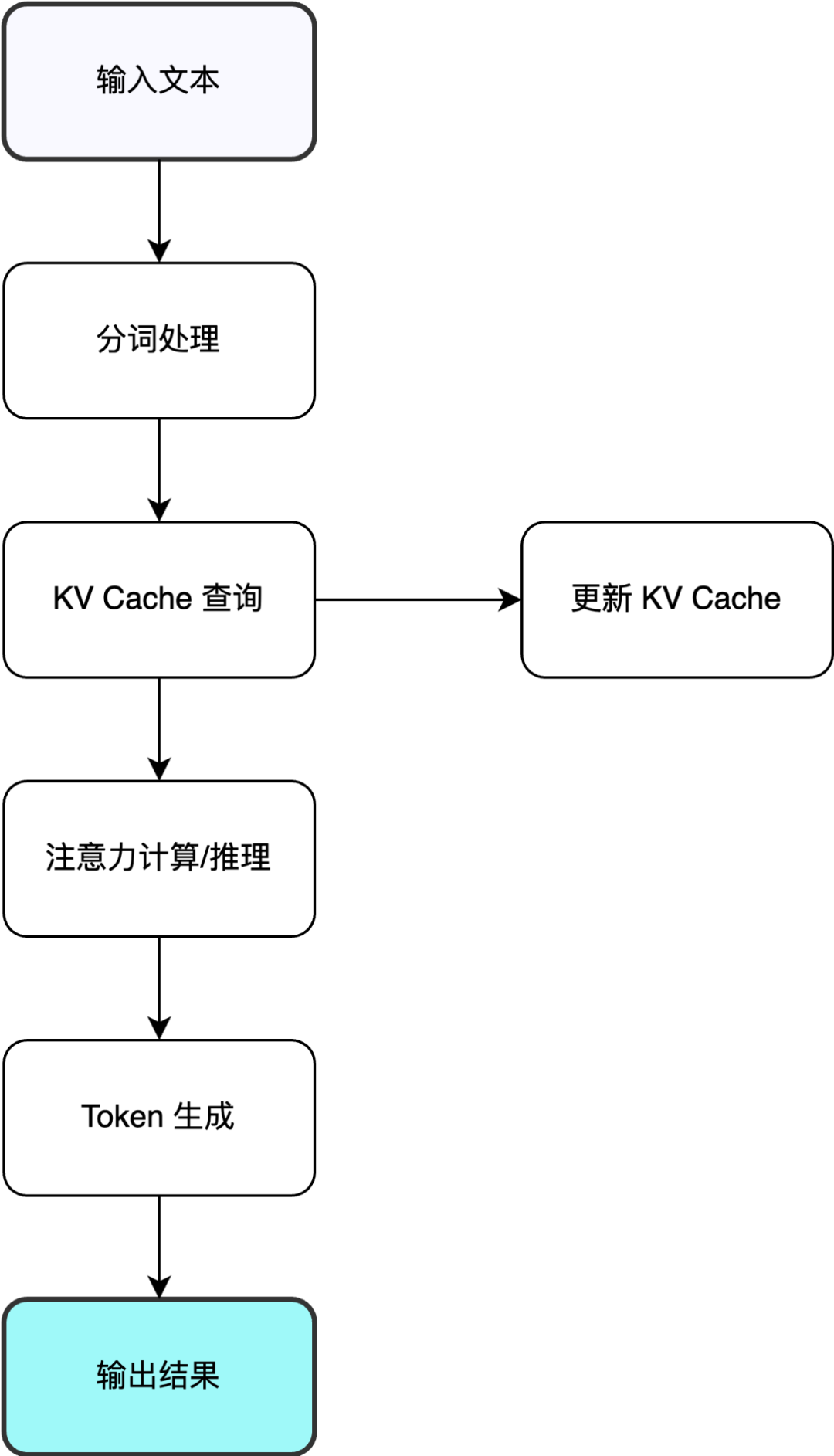
2. 推理过程 - AI的"思考链路"
当我们向AI提出问题时,它的思考过程是这样的:
// 生成回答的核心流程
func Generate(prompt string) string {
// 1. 分词处理
tokens := Tokenize(prompt)
// 2. 逐步推理
for !IsComplete() {
// 预测下一个词
nextWord := PredictNext(tokens)
tokens = append(tokens, nextWord)
}
// 3. 生成最终答案
return Decode(tokens)
}-
1. 理解输入
-
• 将问题分解成小单元(分词)
-
• 建立理解的上下文
-
• 准备推理环境
2. 生成答案
-
• 逐步推理和思考
-
• 不断积累和更新信息
-
• 组织语言输出结果
写在最后
通过这次"解剖"Ollama的源码之旅,我们看到了一个精心设计的AI引擎是如何运作的。就像一台精密的机器,Ollama在以下几个方面展现出了独特的创新:
-
1. 模块化设计 - 像积木一样的架构
-
• 代码结构清晰,就像一本整理得当的说明书
-
• 扩展性良好,可以轻松添加新功能
-
• 维护简单,出现问题容易定位和修复
2. 性能优化 - 追求极致的速度
-
• 内存管理高效,像一个节俭的管家
-
• 资源调度智能,让每份算力物尽其用
-
• 并发处理出色,多任务协同无间
3. 用户友好 - 以人为本的设计
-
• 接口设计简洁,用起来得心应手
-
• 配置选项灵活,满足不同需求
-
• 错误处理完善,及时发现并解决问题
通过深入理解这些设计理念,我们不仅能更好地驾驭Ollama这个强大的AI助手,还能在开发自己的AI应用时借鉴这些宝贵经验。正是这些精妙的设计,让Ollama成为了一个既高效又可靠的本地AI引擎,为我们打开了AI应用的新世界。
参考资源
-
1. Ollama 源码仓库:https://github.com/ollama/ollama
-
2. GGML 文档:https://github.com/ggerganov/ggml
-
3. GGUF 规范:https://github.com/ggerganov/ggml/blob/master/docs/gguf.md

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)