老杨说运维 | 智能场景实践:运维大模型和根因定界探索(文末附现场演讲视频)
运维大模型的更新迭代速度愈来愈快,性能日益变强,它正在赋能或重塑各行各业。在运维领域内,与大模型的有效结合正成为热门话题。大模型通过海量的运维数据建模和训练,赋予了运维场景更智能化的认知能力和行为能力,全方位提高了运维效率,包括高效关联各维度监控指标、快速完成根因定界定位以及实现自动化、智能化的排障等。

前言
青城山脚下的滔滔江水奔涌而过,承载着擎创一往无前的势头,共同去向未来。2024年6月,双态IT成都用户大会擎创科技“数智化可观测赋能双态运维”专场迎来了完满的收尾。

本期回顾来自擎创科技算法总监汪洋的现场演讲:运维大模型的更新迭代速度愈来愈快,性能日益变强,它正在赋能或重塑各行各业。在运维领域内,与大模型的有效结合正成为热门话题。大模型通过海量的运维数据建模和训练,赋予了运维场景更智能化的认知能力和行为能力,全方位提高了运维效率,包括高效关联各维度监控指标、快速完成根因定界定位以及实现自动化、智能化的排障等。
一、运维大模型探索实践
当大模型最早问世的时候,我们只能利用它去解释一些专业性的告警,到现在已经可以使之完成更深层的任务,比如对告警或日志进行模板提取、对告警内容分析给出处置建议及生成相关故障报告等。而基于运维知识库的RAG技术是解决上述任务的最有效方法之一,它包括了两项重要工作:一个是知识库的构建,一个是告警与知识库的匹配。
1.知识库构建(分为公域知识库与私域知识库)
公域知识库包含了服务器、数据库、操作系统、容器等运维知识,主要通过字符串和向量检索的混合方式将官方文档、论坛、帖子以及其他公开性知识收集起来,进行学习和训练。一般的构建过程为:先全面收集各类运维数据,完成数据的清洗后将数据文档以向量等形式进行存储并构建相关索引以便随时提取使用。
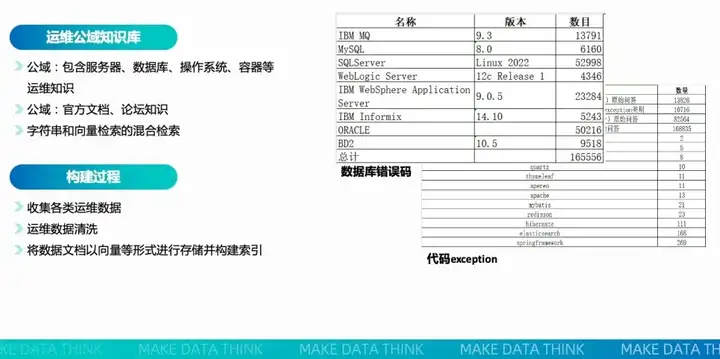
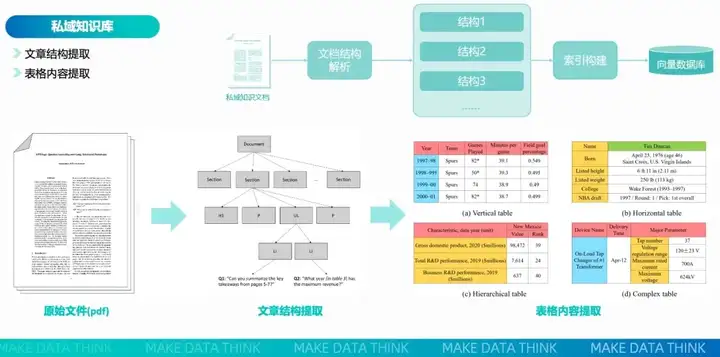
私域知识库则主要会从用户的环境中去获取工单、拓扑信息、告警文档、日志、已有的处置预案等。通过文章结构提取和表格内容提取两种形式,使上述信息规范化、量化入库。
2.告警与知识库的匹配
基于对运维语义中一些关键字的理解,去进行内容的自动切分,在不同的数据库里完成检索,将检索出来的结果交由大模型来处理,以供场景消费使用。

二、大模型与根因定界结合
我们在数年的实践中发现,不是所有企业机构的CMDB都做的十分完善,很多CMDB数据不全或质量不佳的企业通常都有以下三种痛点。
-
监控告警数据覆盖面全,但数量过大
-
CMDB数量质量不满足拓扑定界的要求
-
告警风暴出现时,处置效率过低(熵过载)
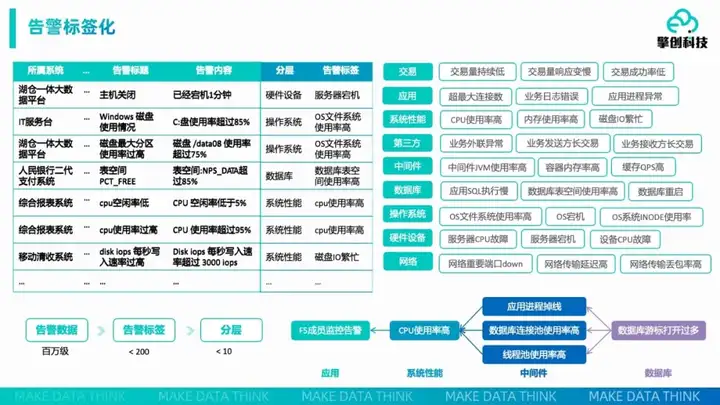
擎创认为,在这种情况下最优的解决方案即是“告警标签化”,通过提取关键信息,从业务视角出发分层分级对告警进行标签化处置,根据这些标签能够快速筛除冗余信息,方便运维人员在应急排障等场景下快速理解告警、完成排障。
更多精彩内容,可戳下面现场演讲视频
运维大模型和根因定界探索
![]()

擎创科技,Gartner连续推荐的AIOps领域标杆供应商。公司专注于通过提升企业客户对运维数据的洞见能力,为运维降本增效,充分体现科技运维对业务运营的影响力。
行业龙头客户的共同选择

了解更多运维干货与行业前沿动态
可以右上角一键关注
我们是深耕智能运维领域近十年的
连续多年获Gartner推荐的AIOps标杆供应商
下期我们不见不散~

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 13
13 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)