机器学习 06:SMO 算法
文章目录概述选择变量的启发式方法选择第一个变量选择第二个变量目标函数的优化无约束求极值加入约束更新阈值 b概述SMOSMOSMO 是由 PlattPlattPlatt 在 1998 年提出的、针对软间隔最大化 SVMSVMSVM 对偶问题求解的一个算法,其基本思想很简单:如果所有变量的解都满足此优化问题的 KKT 条件,则这个优化问题的解就得到了;否则在每一步优化中,挑选出诸多参数 αk 
概述
S M O SMO SMO 是由 P l a t t Platt Platt 在 1998 年提出的、针对软间隔最大化 S V M SVM SVM 对偶问题求解的一个算法,其基本思想很简单:如果所有变量的解都满足此优化问题的 KKT 条件,则这个优化问题的解就得到了;否则在每一步优化中,挑选出诸多参数 α k ( k = 1 , 2 , ⋯ , n ) \alpha_k\ (k=1,2,\cdots,n) αk (k=1,2,⋯,n) 中的两个参数 α i , α j \alpha_i,\alpha_j αi,αj 作为变量,其余参数都视为常数,问题就变成了类似于二次方程求最大值的问题,从而我们就能求出解析解,这两个变量中,一个是违反 KKT 条件最严重的那一个,另一个由约束条件自动确定一个。
选择变量的启发式方法
先来回顾一下 S V M SVM SVM 中的优化目标函数:
min α i ≥ 0 ( 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j K ( x ⃗ i , x ⃗ j ) − ∑ i = 1 N α i ) s . t . ∑ i = 1 N α i y i = 0 , 0 ≤ α i ≤ C \min\limits_{\alpha_i\ge0}\left(\frac{1}{2}\sum\limits_{i=1}^N\sum\limits_{j=1}^N\alpha_i\alpha_jy_iy_jK(\vec x_i,\vec x_j)-\sum\limits_{i=1}^N\alpha_i\right)\\s.t. \sum\limits_{i=1}^N\alpha_iy_i=0,\ \ 0\le\alpha_i\le C αi≥0min(21i=1∑Nj=1∑NαiαjyiyjK(xi,xj)−i=1∑Nαi)s.t.i=1∑Nαiyi=0, 0≤αi≤C
由于要满足约束 ∑ i = 1 N α i y i = 0 \sum\limits_{i=1}^N\alpha_iy_i=0 i=1∑Nαiyi=0,所以每次需要选取两个 α i \alpha_i αi 做为变量,这一点与坐标上升法不同。
要使优化目标函数有解,我们需要使其满足 K K T KKT KKT 条件中的互补松弛:
α i ( y i ( w ⃗ ⋅ ϕ ( x ⃗ i ) + b ) − 1 + ξ i ) = 0 \alpha_i(y_i(\vec w\cdot\phi(\vec x_i)+b)-1+\xi_i)=0 αi(yi(w⋅ϕ(xi)+b)−1+ξi)=0
根据上面的条件我们可以得出:
{ y i ( w ⃗ ⋅ ϕ ( x ⃗ i ) + b ) ≥ 1 α i = 0 y i ( w ⃗ ⋅ ϕ ( x ⃗ i ) + b ) = 1 0 ≤ α i ≤ C y i ( w ⃗ ⋅ ϕ ( x ⃗ i ) + b ) ≤ 1 α i = C \begin{cases}y_i(\vec w\cdot\phi(\vec x_i)+b)\ge1&\alpha_i=0\\y_i(\vec w\cdot\phi(\vec x_i)+b)=1&0\le\alpha_i\le C\\y_i(\vec w\cdot\phi(\vec x_i)+b)\le1&\alpha_i=C\end{cases} ⎩⎪⎨⎪⎧yi(w⋅ϕ(xi)+b)≥1yi(w⋅ϕ(xi)+b)=1yi(w⋅ϕ(xi)+b)≤1αi=00≤αi≤Cαi=C
由于 w ⃗ = ∑ j = 1 N α j y j ϕ ( x ⃗ j ) \vec w=\sum\limits^N_{j=1}\alpha_jy_j\phi(\vec x_j) w=j=1∑Nαjyjϕ(xj),我们令
g ( x ⃗ i ) = w ⃗ ⋅ ϕ ( x ⃗ i ) + b = ∑ j = 1 N α j y j K ( x ⃗ i , x ⃗ j ) + b g(\vec x_i)=\vec w\cdot\phi(\vec x_i)+b=\sum\limits^N_{j=1}\alpha_jy_jK(\vec x_i,\vec x_j)+b g(xi)=w⋅ϕ(xi)+b=j=1∑NαjyjK(xi,xj)+b
则可以推出以下三个条件:
{ y i g ( x ⃗ i ) ≥ 1 α i = 0 y i g ( x ⃗ i ) = 1 0 ≤ α i ≤ C y i g ( x ⃗ i ) ≤ 1 α i = C \begin{cases}y_ig(\vec x_i)\ge1&\alpha_i=0\\y_ig(\vec x_i)=1&0\le\alpha_i\le C\\y_ig(\vec x_i)\le1&\alpha_i=C\end{cases} ⎩⎪⎨⎪⎧yig(xi)≥1yig(xi)=1yig(xi)≤1αi=00≤αi≤Cαi=C
选择第一个变量
在 S M O SMO SMO 中,我们称第一个变量为外循环。外循环取的是样本中违反 K K T KKT KKT 条件最严重的点。
我们可以借助上面推出的条件来度量一个点违反 K K T KKT KKT 条件的程度,具体来说,我们定义三份“差异向量”
c ⃗ ( k ) = ( c 1 ( k ) , c 2 ( k ) , ⋯ , c N ( k ) ) , k = 1 , 2 , 3 c i ( k ) = y i g ( x ⃗ i ) − 1 \vec c^{(k)}=(c_1^{(k)},c_2^{(k)},\cdots,c_N^{(k)}),\ k=1,2,3\\c_i^{(k)}=y_ig(\vec x_i)-1 c(k)=(c1(k),c2(k),⋯,cN(k)), k=1,2,3ci(k)=yig(xi)−1
其中第 k k k 个向量对应着第 k k k 个条件。对于不同的条件,我们按不同方式将对应向量的某些位置置为 0。
-
第一个条件: α i = 0 ⇒ c i ( 1 ) ≥ 0 \alpha_i=0\Rightarrow c_i^{(1)}\ge0 αi=0⇒ci(1)≥0 若满足:
- α i > 0 \alpha_i>0 αi>0 且 c i ( 1 ) ≤ 0 c_i^{(1)}\le0 ci(1)≤0
- α i = 0 \alpha_i=0 αi=0 且 c i ( 1 ) ≥ 0 c_i^{(1)}\ge0 ci(1)≥0
-
第二个条件: 0 ≤ α i ≤ C ⇒ c i ( 2 ) = 0 0\le\alpha_i\le C\Rightarrow c_i^{(2)}=0 0≤αi≤C⇒ci(2)=0 若满足:
- α i = 0 \alpha_i=0 αi=0 或 α i = C \alpha_i=C αi=C 且 c i ( 2 ) ≠ 0 c_i^{(2)}\ne0 ci(2)=0
- 0 ≤ α i ≤ C 0\le\alpha_i\le C 0≤αi≤C 且 c i ( 2 ) = 0 c_i^{(2)}=0 ci(2)=0
-
第三个条件: α i = C ⇒ c i ( 3 ) ≤ 0 \alpha_i=C\Rightarrow c_i^{(3)}\le0 αi=C⇒ci(3)≤0
- α i < C \alpha_i< C αi<C 且 c i ( 3 ) ≥ 0 c_i^{(3)}\ge0 ci(3)≥0
- α i = C \alpha_i=C αi=C 且 c i ( 3 ) ≤ 0 c_i^{(3)}\le0 ci(3)≤0
最后只需要将这三个差异向量的平方相加作为“损失”,从而直接选出损失最大的 α i \alpha_i αi 作为外循环即可。
选择第二个变量
第二个变量成为内循环,只需要简单的随机选取一个即可。
取出这两个变量之后,把其它变量看做常数,这样优化目标函数就变成了带约束的二次规划问题。
目标函数的优化
假设选择的两个变量是 α 1 , α 2 \alpha_1,\alpha_2 α1,α2,把其它的 α i \alpha_i αi 都看作常数。定义 K i j = K ( x ⃗ i , x ⃗ j ) K_{ij}=K(\vec x_i,\vec x_j) Kij=K(xi,xj) 那么原先的优化目标函数就成了:
min α 1 , α 2 1 2 K 11 α 1 2 + 1 2 K 2 , 2 α 2 2 + y 1 y 2 K 1 , 2 α 1 α 2 − ( α 1 + α 2 ) + y 1 α 1 ∑ i = 3 N y i α i K i , 1 + y 2 α 2 ∑ i = 3 N y i α i K i , 2 + c s . t . α 1 y 1 + α 2 y 2 = C 0 ≤ α i ≤ C , i = 1 , 2 \min\limits_{\alpha_1,\alpha_2}\frac{1}{2}K_{11}\alpha_1^2+\frac{1}{2}K_{2,2}\alpha_2^2+y_1y_2K_{1,2}\alpha_1\alpha_2-(\alpha_1+\alpha_2)+y_1\alpha_1\sum\limits^N_{i=3}y_i\alpha_iK_{i,1}+y_2\alpha_2\sum\limits^N_{i=3}y_i\alpha_iK_{i,2}+c\\s.t.\ \ \alpha_1y_1+\alpha_2y_2=C\\0\le\alpha_i\le C,\ i=1,2 α1,α2min21K11α12+21K2,2α22+y1y2K1,2α1α2−(α1+α2)+y1α1i=3∑NyiαiKi,1+y2α2i=3∑NyiαiKi,2+cs.t. α1y1+α2y2=C0≤αi≤C, i=1,2
无约束求极值
我们先暂时不管约束条件 0 ≤ α i ≤ C , i = 1 , 2 0\le\alpha_i\le C,i=1,2 0≤αi≤C,i=1,2,通过 α 1 = ( C − α 2 y 2 ) y 1 \alpha_1=(C-\alpha_2y_2)y_1 α1=(C−α2y2)y1 可以将目标函数替换成单变量形式:
min ϕ ( α 2 ) = 1 2 K 1 , 1 ( C − α 2 y 2 ) 2 + 1 2 K 2 , 2 α 2 2 + y 2 K 12 α 2 ( C − α 2 y 2 ) − y 1 ( C − α 2 y 2 ) − α 2 + ( C − α 2 y 2 ) ∑ i = 3 N α i y i K 1 , i + y 2 α 2 ∑ j = 3 N α j y j K 2 , j + c \min \phi(\alpha_2)=\frac12K_{1,1}(C-\alpha_2y_2)^2+\frac12K_{2,2}\alpha^2_2+y_2K_{12}\alpha_2(C-\alpha_2y_2)-y_1(C-\alpha_2y_2)-\alpha_2+(C-\alpha_2y_2)\sum\limits^N_{i=3}\alpha_iy_iK_{1,i}+y_2\alpha_2\sum\limits^N_{j=3}\alpha_jy_jK_{2,j}+c minϕ(α2)=21K1,1(C−α2y2)2+21K2,2α22+y2K12α2(C−α2y2)−y1(C−α2y2)−α2+(C−α2y2)i=3∑NαiyiK1,i+y2α2j=3∑NαjyjK2,j+c
我们设更新前的值为 α i o l d \alpha_i^{old} αiold, 更新后的值为 α i n e w \alpha_i^{new} αinew,对目标函数进行一个偏导的求:
∂ ϕ ( α 2 n e w ) ∂ α 2 n e w = ( K 1 , 1 + K 2 , 2 − 2 K 1 , 2 ) α 2 n e w − K 1 , 1 C y 2 + K 1 , 2 C y 2 + y 1 y 2 − 1 − y 2 ∑ i = 3 N α i y i K 1 , i + y 2 ∑ j = 3 N α j y j K 2 , j = 0 \frac{\partial\phi(\alpha_2^{new})}{\partial\alpha_2^{new}}=(K_{1,1}+K_{2,2}-2K_{1,2})\alpha_2^{new}-K_{1,1}Cy_2+K_{1,2}Cy_2+y_1y_2-1-y_2\sum\limits^N_{i=3}\alpha_iy_iK_{1,i}+y_2\sum\limits^N_{j=3}\alpha_jy_jK_{2,j}=0 ∂α2new∂ϕ(α2new)=(K1,1+K2,2−2K1,2)α2new−K1,1Cy2+K1,2Cy2+y1y2−1−y2i=3∑NαiyiK1,i+y2j=3∑NαjyjK2,j=0
因为 SVM 中数据点的预测值为: f ( x ⃗ j ) = ∑ i = 1 N α i y i K ( x ⃗ i , x ⃗ j ) + b f(\vec x_j)=\sum\limits^N_{i=1}\alpha_iy_iK(\vec x_i,\vec x_j)+b f(xj)=i=1∑NαiyiK(xi,xj)+b 因此有:
- ∑ i = 3 N α i y i K 1 , i = f ( x ⃗ 1 ) − α 1 n e w y 1 K 1 , 1 − α 2 n e w y 2 K 1 , 2 − b \sum\limits^N_{i=3}\alpha_iy_iK_{1,i}=f(\vec x_1)-\alpha_1^{new}y_1K_{1,1}-\alpha_2^{new}y_2K_{1,2}-b i=3∑NαiyiK1,i=f(x1)−α1newy1K1,1−α2newy2K1,2−b
- ∑ i = 3 N α i y i K 2 , i = f ( x ⃗ 2 ) − α 1 n e w y 1 K 1 , 2 − α 2 n e w y 2 K 2 , 2 − b \sum\limits^N_{i=3}\alpha_iy_iK_{2,i}=f(\vec x_2)-\alpha_1^{new}y_1K_{1,2}-\alpha_2^{new}y_2K_{2,2}-b i=3∑NαiyiK2,i=f(x2)−α1newy1K1,2−α2newy2K2,2−b
另有: C = α 1 o l d y 1 + α 2 o l d y 2 C=\alpha_1^{old}y_1+\alpha_2^{old}y_2 C=α1oldy1+α2oldy2
将上面三个式子带入偏导中并化简得:
( K 1 , 1 + K 2 , 2 − 2 K 1 , 2 ) α 2 n e w = ( K 1 , 1 + K 2 , 2 − 2 K 1 , 2 ) α 2 o l d + y 2 [ ( f ( x ⃗ 1 ) − y 1 ) − ( f ( x ⃗ 2 ) − y 2 ) ] (K_{1,1}+K_{2,2}-2K_{1,2})\alpha_2^new=(K_{1,1}+K_{2,2}-2K_{1,2})\alpha_2^{old}+y_2[(f(\vec x_1)-y_1)-(f(\vec x_2)-y_2)] (K1,1+K2,2−2K1,2)α2new=(K1,1+K2,2−2K1,2)α2old+y2[(f(x1)−y1)−(f(x2)−y2)]
设 η = K 1 , 1 + K 2 , 2 − 2 K 1 , 2 \eta=K_{1,1}+K_{2,2}-2K_{1,2} η=K1,1+K2,2−2K1,2,则有:
{ α 2 n e w = α 2 o l d + y 2 [ ( f ( x ⃗ 1 ) − y 1 ) − ( f ( x ⃗ 2 ) − y 2 ) ] η α 1 o l d y 1 + α 2 o l d y 2 = α 1 n e w y 1 + α 2 n e w y 2 \begin{cases}\alpha_2^{new}=\alpha_2^{old}+\frac{y_2[(f(\vec x_1)-y_1)-(f(\vec x_2)-y_2)]}{\eta}\\\alpha_1^{old}y_1+\alpha_2^{old}y_2=\alpha_1^{new}y_1+\alpha_2^{new}y_2\end{cases} {α2new=α2old+ηy2[(f(x1)−y1)−(f(x2)−y2)]α1oldy1+α2oldy2=α1newy1+α2newy2
这样我们就求出了这两个变量在无约束情况下的解析解。
加入约束
当 y 1 ≠ y 2 y_1\ne y_2 y1=y2 时,线性限制条件可以写成: α 1 − α 2 = k \alpha_1-\alpha_2=k α1−α2=k,根据 k k k 的正负可以得到不同的上下界,可以统一表示为:
- 下界: L = max ( 0 , α 2 − α 1 ) L=\max(0,\alpha_2-\alpha_1) L=max(0,α2−α1)
- 上界: H = min ( C , C + α 2 − α 1 ) H=\min(C,C+\alpha_2-\alpha_1) H=min(C,C+α2−α1)
当 y 1 = y 2 y_1=y_2 y1=y2 时,限制条件可以写成: α 1 + α 2 = k \alpha_1+\alpha_2=k α1+α2=k,此时上下界可以统一为:
- 下界: L = m a x ( 0 , α 1 + α 2 − C ) L=max(0,\alpha_1+\alpha_2-C) L=max(0,α1+α2−C)
- 上界: H = m i n ( C , α 1 + α 2 ) H=min(C,\alpha_1+\alpha_2) H=min(C,α1+α2)
由此可知,此约束为方形约束,下图为它的限制区域。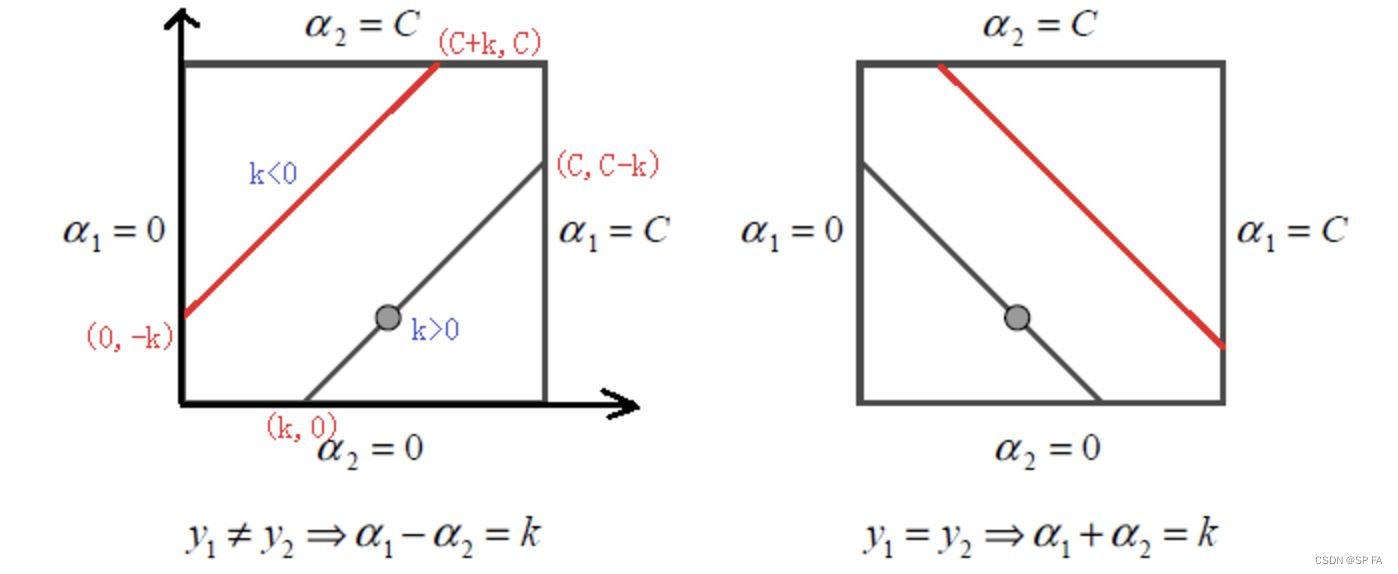
根据得到的上下界,我们可知加入约束后的 α 2 n e w \alpha_2^{new} α2new 为:
α 2 n e w = { H α 2 n e w > H a 2 n e w L ≤ α 2 n e w ≤ H L α 2 n e w < L \alpha_2^{new}=\begin{cases}H&\alpha_2^{new}>H\\a_2^{new}&L\le\alpha_2^{new}\le H\\L&\alpha_2^{new}<L\end{cases} α2new=⎩⎪⎨⎪⎧Ha2newLα2new>HL≤α2new≤Hα2new<L
这样就实现了对 α i , α j \alpha_i,\alpha_j αi,αj 的更新。
更新阈值 b
每次更新完一对 α i , α j \alpha_i,\alpha_j αi,αj 之后都需要重新计算阈值 b b b,因为它关系到 f ( x ⃗ ) f(\vec x) f(x) 的计算和优化时误差 E i E_i Ei 的计算。
当 0 < a l p h a 1 n e w < C 0<alpha_1^{new}<C 0<alpha1new<C,根据 K K T KKT KKT 条件可知相应的数据点为支持向量,满足 y 1 ( w T + b ) = 1 y_1(w^T+b)=1 y1(wT+b)=1,两边同时乘 y 1 y_1 y1 得: ∑ i = 1 N α i y i K i , 1 + b = y 1 \sum\limits^N_{i=1}\alpha_iy_iK_{i,1}+b=y_1 i=1∑NαiyiKi,1+b=y1,因此 b 1 n e w b_1^{new} b1new 的值为:
b 1 n e w = y 1 − ∑ i = 3 N α i y i K i , 1 − α 1 n e w y 1 K 1 , 1 − α 2 n e w y 2 K 2 , 1 b_1^{new}=y1-\sum\limits^N_{i=3}\alpha_iy_iK_{i,1}-\alpha_1^{new}y_1K_{1,1}-\alpha_2^{new}y_2K_{2,1} b1new=y1−i=3∑NαiyiKi,1−α1newy1K1,1−α2newy2K2,1
其中, y 1 − ∑ i = 3 N α i y i K i , 1 = − E 1 + α 1 o l d y 1 K 1 , 1 + α 2 o l d y 2 K 2 , 1 + b o l d y1-\sum\limits^N_{i=3}\alpha_iy_iK_{i,1}=-E_1+\alpha_1^{old}y_1K_{1,1}+\alpha_2^{old}y_2K_{2,1}+b^{old} y1−i=3∑NαiyiKi,1=−E1+α1oldy1K1,1+α2oldy2K2,1+bold
当 0 < α 2 n e w < C 0<\alpha_2^{new}<C 0<α2new<C 时:
b 2 n e w = − E 2 − y 1 K 1 , 2 ( α 1 n e w − α 1 o l d ) − y 2 K 2 , 2 ( α 2 n e w − α 2 o l d ) + b o l d b_2^{new}=-E_2-y_1K_{1,2}(\alpha_1^{new}-\alpha_1^{old})-y_2K_{2,2}(\alpha_2^{new}-\alpha_2^{old})+b^{old} b2new=−E2−y1K1,2(α1new−α1old)−y2K2,2(α2new−α2old)+bold
当 b 1 , b 2 b_1,b_2 b1,b2 都有效时他们是相等的,即 b n e w = b 1 n e w = b 2 n e w b^{new}=b_1^{new}=b_2^{new} bnew=b1new=b2new
当 α 1 , α 2 \alpha_1,\alpha_2 α1,α2 都在边界上,且 L ≠ H L\ne H L=H 时,选择它们的中点作为新的阈值: b n e w = b 1 n e w + b 2 n e w 2 b^{new}=\frac{b_1^{new}+b_2^{new}}2 bnew=2b1new+b2new
同步更新于:SP-FA 的博客

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 1
1 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)