【深度学习】【U-net】医学图像(血管)分割实验记录
医学图像分割实验记录U-net介绍数据集实验记录实验1本项目仅用于大创实验,使用pytorch编程,参考价值有限U-net介绍这里先行挖个坑,以后专门写一篇自己总结的资源吧。数据集使用hx医院提供的脑CT图像,原图像为医学图像数据(数据范围较大)。使用ITK−SNAPITK-SNAPITK−SNAP软件自行标注后得到的标记数据做标签。切片显示大致长这样:TODO:由于本人认为血...
本项目仅用于大创实验,使用pytorch编程,参考价值有限
U-net介绍
这里先行挖个坑,以后专门写一篇自己总结的资源吧。
数据集
使用hx医院提供的脑CT图像,原图像为医学图像数据(数据范围较大)。使用 I T K − S N A P ITK-SNAP ITK−SNAP软件自行标注后得到的标记数据做标签。
切片显示大致长这样:
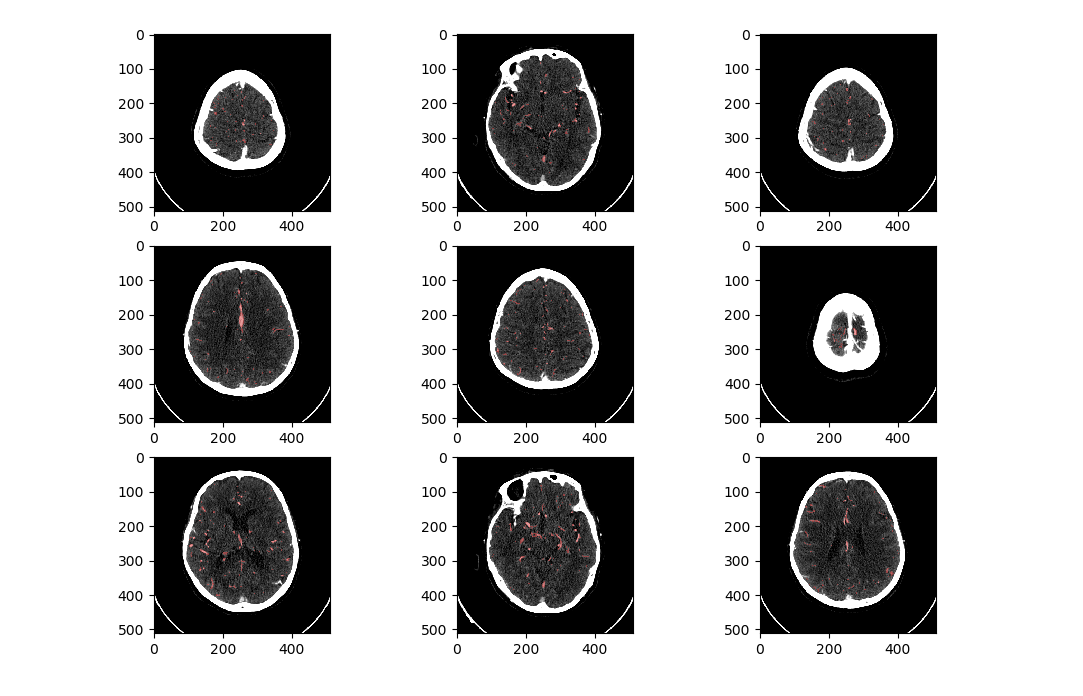
TODO:由于本人认为血管分割要参考每张图片上下几张空间序列上相邻切片的数据,因此想着直接把这些’相邻数据’作为每张图像的其他‘channel’。且令总的channel为奇数。 e g . eg. eg.输入数据维度可能为 ( 1 , 5 , 128 , 128 ) (1,5,128,128) (1,5,128,128),意味着 b a t c h s i z e = 1 batch size=1 batchsize=1, c h a n n e l = 5 channel = 5 channel=5, i m a g e s i z e = ( 128 , 128 ) image size=(128,128) imagesize=(128,128)。
实验记录
实验1
Epoch:15train data:800test data:200Learning Rate:0.05Img Size:(128,128)Batch Size:1Channel:5
模型结构:
Unet(
(conv1): DoubleConv(
(conv): Sequential(
(0): Conv2d(5, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): DoubleConv(
(conv): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
(pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv3): DoubleConv(
(conv): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
(pool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(up8): ConvTranspose2d(256, 128, kernel_size=(2, 2), stride=(2, 2))
(conv8): DoubleConv(
(conv): Sequential(
(0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
(up9): ConvTranspose2d(128, 64, kernel_size=(2, 2), stride=(2, 2))
(conv9): DoubleConv(
(conv): Sequential(
(0): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
(conv10): Conv2d(64, 1, kernel_size=(1, 1), stride=(1, 1))
)
实验结果:忘记了orz
实验参数保存为net040801_normal.pkl
实验2(fail)
相比于实验1只改变了image size。
Epoch:15train data:800test data:200Learning Rate:0.05Img Size:(256,256)Batch Size:1Channel:5
模型结构同实验1
loss: 0.693154
误差维持不变,模型没有收敛。
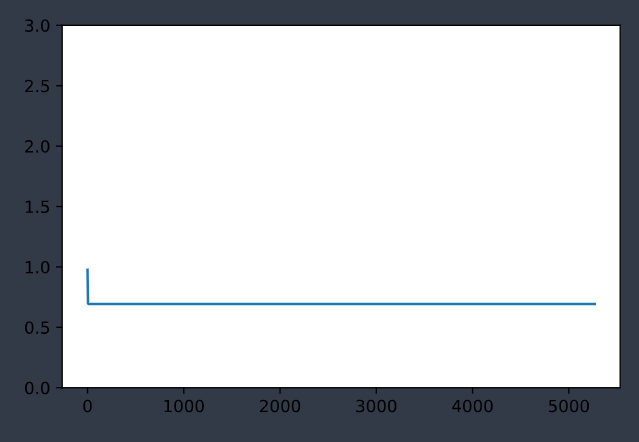
实验3(fail)
相比于实验2改变了learning rate,从0.05变为0.005。
Epoch:15train data:800test data:200Learning Rate:0.005Img Size:(256,256)Batch Size:1Channel:5
模型结构同实验1
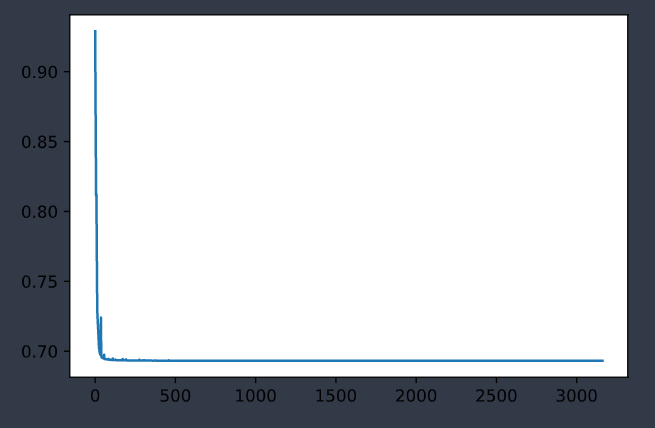 |
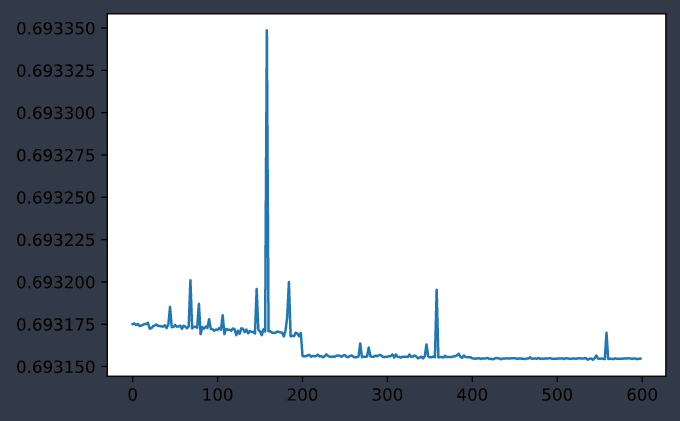 |
| 训练集误差变化曲线 | 测试集误差变化曲线 |
实验4(fail)
相比于实验3改变了image size,从(256,256)改回(128,128)。
Epoch:15train data:800test data:200Learning Rate:0.005Img Size:(128, 128)Batch Size:1Channel:5
模型结构同实验1
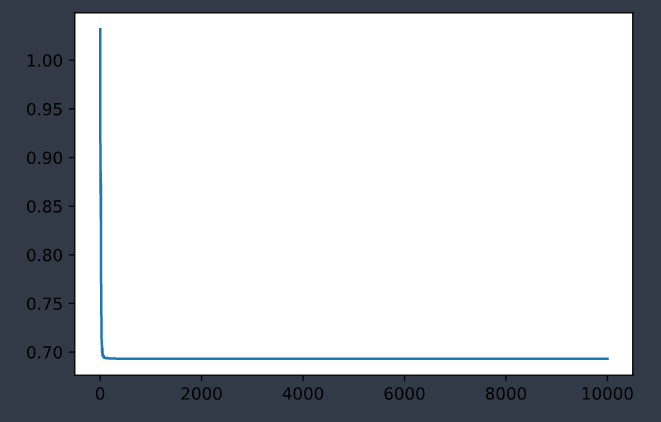 |
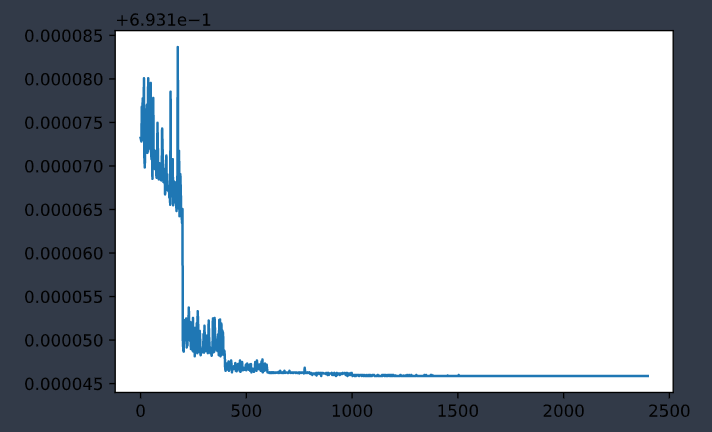 |
| 训练集误差变化曲线 | 测试集误差变化曲线 |
最后误差维持在
loss: 0.693146
实验5(fail)
相比于实验4改变了learning rate,从0.005改为0.0005。
Epoch:20+train data:800test data:200Learning Rate:0.0005Img Size:(128, 128)Batch Size:1Channel:5
模型结构同实验1
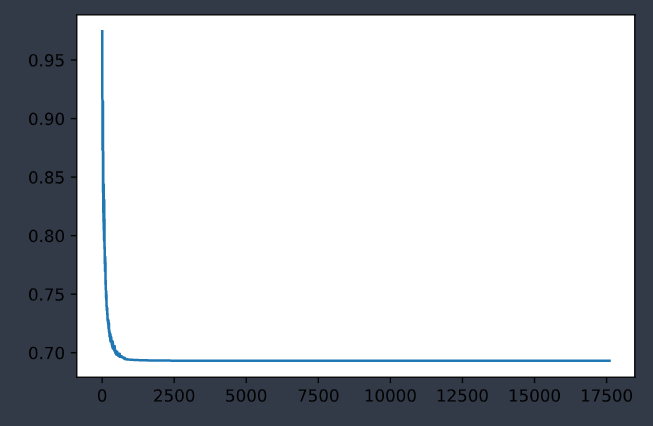 |
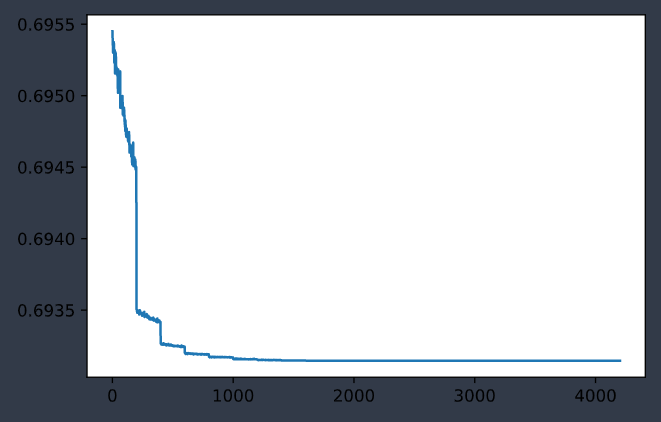 |
| 训练集误差变化曲线 | 测试集误差变化曲线 |
最后误差维持在
loss: 0.693146
好吧这个数和实验4一样
实验6(fail)
相比于实验5改变了网络结构加了一层深度。
Epoch:20+train data:800test data:200Learning Rate:0.0005Img Size:(128, 128)Batch Size:1Channel:5
模型结构为
Unet(
(conv1): DoubleConv(
(conv): Sequential(
(0): Conv2d(5, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): DoubleConv(
(conv): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
(pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv3): DoubleConv(
(conv): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
(pool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv4): DoubleConv(
(conv): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
(pool4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(up7): ConvTranspose2d(512, 256, kernel_size=(2, 2), stride=(2, 2))
(conv7): DoubleConv(
(conv): Sequential(
(0): Conv2d(512, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
(up8): ConvTranspose2d(256, 128, kernel_size=(2, 2), stride=(2, 2))
(conv8): DoubleConv(
(conv): Sequential(
(0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
(up9): ConvTranspose2d(128, 64, kernel_size=(2, 2), stride=(2, 2))
(conv9): DoubleConv(
(conv): Sequential(
(0): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
(conv10): Conv2d(64, 1, kernel_size=(1, 1), stride=(1, 1))
)
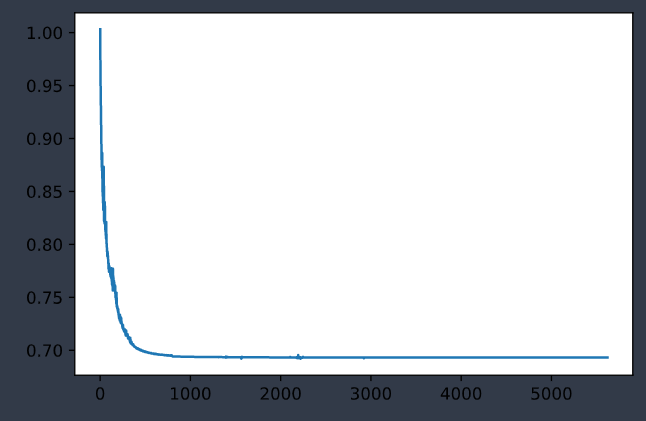 |
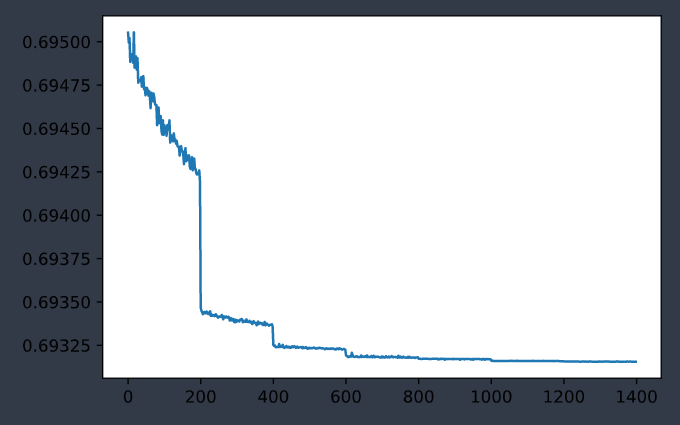 |
| 训练集误差变化曲线 | 测试集误差变化曲线 |
最后误差维持在
loss: 0.693156

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 1
1 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)