遥感之机器学习树集成模型-ID3算法
介绍遥感,地理信息系统等领域常用的集成树算法,对算法源码进行层层剖析。
在前文基础上,本文对ID3算法做简要介绍,目前应用不多,并对其划分指标进行说明,最后贴上了核心源码。
前文相关可参考遥感之树集成专栏
1 ID3介绍
在决策树学习中,ID3(Iterative Dichotomiser 3)是由Ross Quinlan发明的一种算法,以Hunt算法为基础,用于从数据集生成决策树。
ID3是C4.5算法的前身。ID3算法只能处理特征属性均为离散数据类型的数据集且不支持剪枝。
- ID3算法以原始集合S为根节点。
- 在算法的每次迭代中,根据集合S的每一个未使用的属性进行遍历,根据该属性的所有取值,计算按该属性分割后的熵H(S)或信息增益IG(S)。
- 然后,从中选择熵值最小(或信息增益最大)的属性。
- 之后,根据该属性的所有取值对集合S进行分割,以产生数据的子集。
需要指出的是,ID3算法生成的树可能是多元树,即一个节点的子节点可能会多于两个,具体数量依赖于该节点所对应的属性的所有可能的取值。
该算法继续对每个子集进行递归,只考虑以前从未选择过的属性,因为此时每个子集中,已经选择过的属性的数据都是纯的。
ID3算法与CART算法的不同之处主要表现在:
ID3只能处理特征属性为离散数据类型的数据集。
ID3不支持剪枝。
选择特征属性依据信息熵和信息增益。
ID3生成的树是一个多元树,集合S按照属性A进行分割后,子集的数量(子节点的数量)与属性A的取值有关。所有属性A的取值都是分割点,因此,每个子集里的样本数据的属性A的取值都是相同的。因此,针对子集的后续分割将不再考虑已经选择过的属性。
ID3算法主要用于分类决策树。ID3不保证最优解,它可能收敛于局部最优解。它采用贪婪的策略,在每次迭代中选择局部最佳属性来分割数据集。在搜索最优决策树的过程中,可以通过使用回溯来提高算法的最优解,但代价是可能需要更长的时间。
ID3对训练数据可能会出现过拟合。为了避免过拟合,应该优先选择较小的决策树,而不是较大的决策树。ID3在连续数据上比在离散数据上更难使用。如果任何一个给定属性的值是连续的,那么在这个属性上有更多的地方可以拆分数据,寻找最佳的拆分值会很耗时。
2 分割指标
2.1 信息熵
熵衡量的是数据集S的不确定性的大小,熵越高,数据越混杂。
给定一个离散随机变量X和样本数据集合S,X有N个取值,可能的取值为x1,…,xn,各自发生的概率分别为p(x1),…,p(xn),则S的熵正式定义为: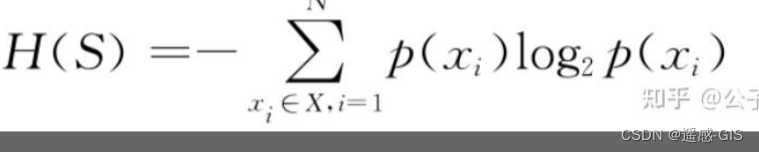
2.2 信息增益
在信息理论和机器学习中,信息增益是KL散度(Kullback-Leibler divergence)的同义词,即在观察样本中,基于另一个随机变量获得的关于一个随机变量或信号的信息量。然而,在决策树的上下文中,它与互信息(mutual information)同义,即一个变量的单变量概率分布与这个变量基于给定的另一个变量的条件分布的KL散度的条件期望值。
对于离散随机变量X和样本数据集合S,给定另一个随机变量A,它代表样本数据集合S的另一个属性,它的取值可能是{a1,a2,a3,…,aw},这样根据随机变量A的取值,样本集合S被划分为w个子集合SA(ai),ai∈{a1,a2,a3,…,aw}其中,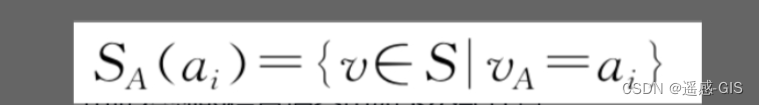
由此得到的信息增益由如下公式计算: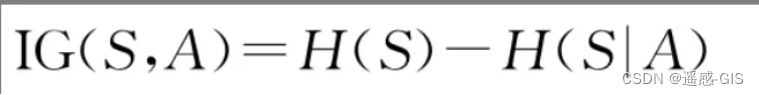
其中H(S|A)是给定取值a时S的条件熵: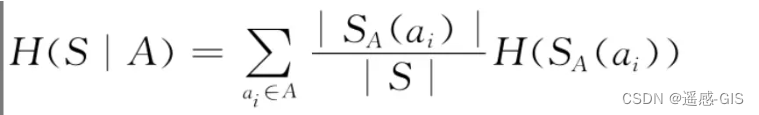
信息增益是衡量样本数据集合S对某一属性A进行拆分前后熵差的指标,在训练决策树时,通过最大化信息增益来选择最佳的分割方式,信息增益的计算方法是从原始熵中减去分支的加权熵。在训练决策树时,通过最大化信息增益来选择最佳分割。
3 核心源码
上述原理和公式介绍可知,其关键部分就是计算信息熵和信息增益,其中信息增益关键是计算条件熵,其他部分和CART树的结构一致。
3.1 计算信息熵
def cal_shannon_entropy(y_tensor):
'''
return shannon_entropy: 熵 float
'''
# 统计y_tensor中的目标变量值的个数
y_counts = {}
for v in y_tensor:
if v.item() not in y_counts.keys():
y_counts[v.item()] = 0
y_counts[v.item()] += 1
# 计算信息熵
shannon_entropy = 0.0
num_sample = len(y_tensor)
for key in y_counts.keys():
prob = float(y_counts[key]) / num_sample
shannon_entropy -= prob * log(prob, 2)
return shannon_entropy
由上述可知,y主要是离散的,ID3算法主要由于分类目的。
3.2 构建树
def create_tree(X_tensor, y_tensor, feature_names):
"""创建树
feature_names: numpy.array
return tree: dict
"""
# 若X中样本全属于同一类别C,则停止划分
if y_tensor.max() == y_tensor.min():
return get_value(y_tensor[0], to_X=False)
# 若属性集为空,或者属性集上的取值均相同
if len(X_tensor)==0 or X_tensor.max()==X_tensor.min():
return get_value(majority_y_id(y_tensor), to_X=False)
# 按照“信息增益最高”,从feature_names中选择最优分裂属性
best_feature_index = choose_best_feature_to_split(X_tensor, y_tensor)
best_feature_name = feature_names[best_feature_index] # 属性名
# 根据最优分裂属性,进行子树的划分
tree = {best_feature_name: {}} # 构建树的字典
sub_feature_names = np.delete(feature_names, best_feature_index) # 删除已使用的属性
feature_values = X_tensor[:, best_feature_index] # 最优属性集
unique_feature_values = set(feature_values) # 去除最优属性集中的重复属性值
for feature_value in unique_feature_values: # 根据不同属性值进行数据集的划分
sub_X_tensor, sub_y_tensor = plit_data_set(X_tensor, y_tensor, best_feature_index, feature_value)
real_feature_value = get_value(feature_value) # 获取映射前的特征值
tree[best_feature_name][real_feature_value] = create_tree(sub_X_tensor, sub_y_tensor, sub_feature_names)
return tree
划分数据集
def choose_best_feature_to_split(X_tensor, y_tensor):
"""选择最优分裂属性的索引
X_tensor: torch.tensor
y_tensor: torch.tensor
return best_feature_index: 最优分裂属性的索引 int
"""
dataset_entropy = cal_shannon_entropy(X_tensor, y_tensor)
best_info_gain = 0.0
best_feature_index = -1
num_feature = X_tensor.shape[1] # 属性的个数
for i in range(num_feature): # 遍历每个属性
feature_value_list = X_tensor[:, i] # 得到某个属性下的所有值,即某列
unique_feature_value = set(feature_value_list) # 得到无重复的属性特征值
sub_dataset_entropy = 0.0
for feature_value in unique_feature_value:
sub_X, sub_y = split_data_set(X_tensor, y_tensor, i, feature_value)
prob = len(sub_X) / float(len(X_tensor))
sub_dataset_entropy += prob * __cal_shannon_entropy(sub_X, sub_y)
info_gain = dataset_entropy - sub_dataset_entropy
# 最大信息增益
if info_gain > best_info_gain:
best_info_gain = info_gain
best_feature_index = i
return best_feature_index
def split_data_set( X_tensor, y_tensor, feature_col_index, feature_value):
"""根据最优分裂属性的不同特征值对当前数据集进行划分
feature_col_index: 分裂属性的列索引 int
feature_value: 分裂属性的属性值 int
return sub_X_tensor: 划分后的数据集X pytorch.tensor
return sub_y_tensor: 划分后的数据集y pytorch.tensor
"""
mask_vec_row = X_tensor[:, feature_col_index]==feature_value
mask_vec_col = np.arange(X_tensor.shape[1])!=feature_col_index
sub_X_tensor = X_tensor[:, mask_vec_col][mask_vec_row, :]
sub_y_tensor = y_tensor[mask_vec_row]
return sub_X_tensor, sub_y_tensor
4 总结
目前ID3算法应用不多,和CART框架类似,不做重点说明。
本文主要对ID3做了简单介绍以及划分的指标介绍,最后对核心源码进行了说明。
欢迎点赞,收藏,关注,支持小生,打造一个好的遥感领域知识分享专栏。
关注其他平台专栏:遥感之集成树专栏
同时欢迎私信咨询讨论学习,咨询讨论的方向不限于:地物分类/语义分割(如水体,云,建筑物,耕地,冬小麦等各种地物类型的提取),变化检测,夜光遥感数据处理,目标检测,图像处理(几何矫正,辐射矫正(大气校正),图像去噪等),遥感时空融合,定量遥感(土壤盐渍化/水质参数反演/气溶胶反演/森林参数(生物量,植被覆盖度,植被生产力等)/地表温度/地表反射率等反演)以及高光谱数据处理等领域以及深度学习,机器学习等技术算法讨论,以及相关实验指导/论文指导等多方面。
如果对具体的详细示例有兴趣,可以参考本专栏的参考书目:
<现代决策树模型及其编程实践:从传统决策树到深度决策树 黄智濒>
其电子书和其相关的源码可通过下述咨询链接获取资源获取链接

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)