自然语言处理导论与Python实践(二)词汇分析续
书接上回,此次继续介绍词汇分析中的基于感知器的中文分词方法。
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
一、Chinese Segmentation with a Word-Based Perceptron Algorithm 论文解读
1.1 摘要
中文分词可以定义为将连续字序列转换为对应的词序列的过程。即可以将问题转化为标记任务,为序列中的字符分配标签以指示字符是否为标记单词边界。在基于感知器的中文分词中,作者提出了另一种基于单词的分割方法,使用基于完整单词和单词序列的特征。使用广义感知器算法用于判别训练,使用集束搜索进行解码。
1.2 基于感知器的中文分词(基于神经网络的方法)
感知器的数学描述
中文分词可以定义为将连续字序列转换为对应的词序列的过程。使用 x = c 1 , c 2 , . . . , c n x = {c1, c2, . . . , cn} x=c1,c2,...,cn 表 示输入字序列, y = w 1 , w 2 , . . . , w m y = {w1, w2, . . . , wm} y=w1,w2,...,wm 表示输出词序列, F ( x ) F(x) F(x) 表示最优分词结果。根据上述定义中文分词可以形式化地表达为:
F ( x ) = a r g m a x S C O R E ( y ) ( 2.3 ) y ∈ G E N ( x ) F(x) = arg max SCORE(y) (2.3) y∈GEN(x) F(x)=argmaxSCORE(y)(2.3)y∈GEN(x)
其中$ GEN(x) $代表对于每一个输入句子 x x x 可能的所有候选输出, S C O R E ( y ) SCORE(y) SCORE(y) 为针对分词结果 y y y 的评分函数。
基于感知器中文分词方法,将每一个分词后的单词序列 y y y 定义为一个特征向量 Φ ( x , y ) ∈ R d Φ(x, y) ∈Rd Φ(x,y)∈Rd, 其中 d d d 代表模型中的特征数量,评分函数 S C O R E ( y ) SCORE(y) SCORE(y) 定义为由向量 Φ ( x , y ) Φ(x, y) Φ(x,y) 与参数 α ∈ R d α ∈ Rd α∈Rd 间的点积:
S C O R E ( y ) = Φ ( x , y ) ⋅ α ( 2.4 ) SCORE(y) = Φ(x, y) · α (2.4) SCORE(y)=Φ(x,y)⋅α(2.4)
多类感知器已经可以应付多类分类的问题了,那么它和中文分词有什么联系呢?连接中文分词与多类感知器的桥梁,就是基于字标注的分词方法。
应用基于字标注的分词方法,分词由切分问题转化为序列标注问题。每个字都有一个标注,也就是说每个字属于一个类别,那么给出一个字的标注的过程其实是一个分类过程。所以,利用多类感知器我们可以解决中文分词问题。
给定模型参数情况下,对输入句子的词序列预测问题,根据公式的定义需要计算所有候选分词结果得分。但是,每一个句子都有数量十分庞大的候选分词结果,如果将所有可能的结果都枚举 一遍的话,搜索空间将变得非常巨大,使得我们无法有效地进行训与推断。针对这一问题,常 见的解决方式是使用集束搜索(Beam Search)算法进行解码。集束搜索是一种常用的限制搜索空 间的启发式算法,在每一步解码过程中,从上一步解码的所有候选集中选取前 K 个得分最高的结果继续解码,而舍弃得分排在第K名之后的所有候选结果。集束搜索可以理解为一种松驰过的贪心算法,它并不能保证一定会得到得分最高的候选序列。
# !git clone https://github.com/ZTurboX/CWS.git
正克隆到 'CWS'...
remote: Enumerating objects: 208, done.[K
remote: Counting objects: 100% (26/26), done.[K
remote: Compressing objects: 100% (8/8), done.[K
remote: Total 208 (delta 19), reused 18 (delta 18), pack-reused 182[K
接收对象中: 100% (208/208), 167.91 MiB | 12.70 MiB/s, 完成.
处理 delta 中: 100% (91/91), 完成.
检查连接... 完成。
… 完成。
对应CWS文件夹。大家可以对比论文阅读相应的代码,即为CWS算法。代码文件的使用方法请参考CWS文件中的README文件。
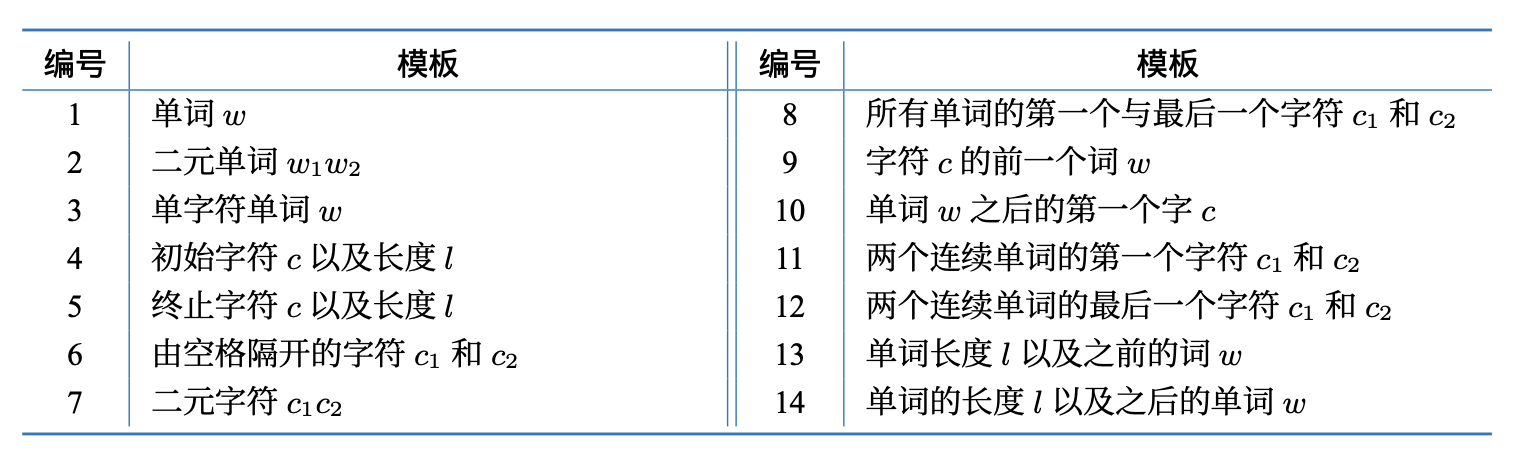
特征模板
论文中使用的特征模板如下图所示:
- 主要代码展示
通过Feature类对输入数据进行编码,beamSearch,集束搜索算法包含进了Decoder类中;具体的算法大家可以参照论文中的介绍,大家一定要结合论文来看代码,加深理解。伪代码流程如下图所示:


class Decoder:
def __init__(self, beam_size, get_score):
self.beam_size = beam_size
self.get_score = get_score
def beamSearch(self, sent):
src = [([], 0.0)]
tgt = []
split_sent = [char for char in sent if(char != ' ') and (char != '\n')]
for index in range(len(split_sent)):
char = split_sent[index]
for item, score in src:
item1 = copy.deepcopy(item)
new_sent = item1 + [char]
tgt.append((new_sent, score + self.get_score(new_sent)))
if len(item) > 0:
item2 = item.copy()
item2[-1] += char
tgt.append(
(item2, score - self.get_score(item) + self.get_score(item2)))
src = self.get_best_item(tgt, self.beam_size)
tgt = []
return self.get_best_item(src, 1)[0][0]
class Feature:
def __init__(self):
self.weight = {}
self.avg_weight = {}
self.r = {}
def add(self, local_feature, name, *args):
# for example:
# ' '.join(("w1w2",) + ("张","岳")) ---> 'w1w2 张 岳'
feature_name = ' '.join((name,) + tuple(args))
local_feature[feature_name] = 1
def get_features(self, item):
w1 = item[-1]
w2 = None
if len(item) > 1:
w2 = item[-2]
local_feature = {}
self.add(local_feature, "w", w1)
if w2 != None:
self.add(local_feature, "w1w2", w1, w2)
if len(w1) == 1:
self.add(local_feature, "single-c_w", w1)
if w2 != None:
self.add(local_feature, "separated c1c2", w2[-1], w1)
else:
self.add(local_feature, "bigram c1c2", w1[-2], w1[-1])
self.add(local_feature, "start(c)len(w)", w1[0], str(len(w1)))
self.add(local_feature, "end(c)len(w)", w1[-1], str(len(w1)))
self.add(local_feature, "first(c1)lst(c2)", w1[0], w1[-1])
if w2 != None:
self.add(local_feature, "w2-c", w2, w1[-1])
self.add(local_feature, "c-w1", w2[-1], w1)
self.add(local_feature, "start(c1)start(c2)", w2[0], w1[0])
self.add(local_feature, "end(c1)end(c2)", w2[-1], w1[-1])
self.add(local_feature, "len(w1)w2", str(len(w1)), w2)
self.add(local_feature, "len(w2)w1", str(len(w2)), w1)
return local_feature
def get_score(self, item):
score = 0
local_feature = self.get_features(item)
for feature_name in local_feature.keys():
score += local_feature[feature_name]*(
self.weight[feature_name] if feature_name in self.weight.keys() else 0)
return score
def get_global_feature(self, item):
global_feature = {}
for i in range(len(item)):
local_feature = self.get_features(item[0:i+1])
for feature_name in local_feature.keys():
global_feature[feature_name] = \
(global_feature[feature_name] if feature_name in global_feature.keys() else 0) + local_feature[feature_name]
return global_feature
def update_weight(self, y, z):
y_feature = self.get_global_feature(y)
z_feature = self.get_global_feature(z)
for feature_name in y_feature.keys():
self.weight[feature_name] = (self.weight[feature_name] if feature_name in self.weight.keys() else 0) \
+ y_feature[feature_name]
for feature_name in z_feature.keys():
self.weight[feature_name] = (self.weight[feature_name] if feature_name in self.weight.keys() else 0) \
- z_feature[feature_name]
def update_avgWeight(self, y, z, n, t, data_size):
z_feature = self.get_global_feature(z)
for feature_name in z_feature.keys():
self.weight[feature_name] = self.weight[feature_name] if feature_name in self.weight.keys() else 0
self.r[feature_name] = self.r[feature_name] if feature_name in self.r.keys() else (0, 0)
self.avg_weight[feature_name] = (self.avg_weight[feature_name] if feature_name in self.avg_weight.keys() else 0) \
+ self.weight[feature_name]*(t*data_size + n - self.r[feature_name][1]*data_size-self.r[feature_name][0])
self.weight[feature_name] -= z_feature[feature_name]
self.r[feature_name] = (n, t)
y_feature = self.get_global_feature(y)
for feature_name in y_feature.keys():
self.weight[feature_name] = self.weight[feature_name] if feature_name in self.weight.keys() else 0
self.r[feature_name] = self.r[feature_name] if feature_name in self.r.keys() else (0, 0)
self.avg_weight[feature_name] = (self.avg_weight[feature_name] if feature_name in self.avg_weight.keys() else 0) \
+ self.weight[feature_name]*(t*data_size+n-self.r[feature_name][1]*data_size-self.r[feature_name][0])
self.weight[feature_name] += y_feature[feature_name]
self.r[feature_name] = (n, t)
def last_update(self, iterations, data_size):
for feature_name in self.weight.keys():
if feature_name not in self.avg_weight.keys():
self.avg_weight[feature_name] = self.weight[feature_name] * \
iterations*data_size
else:
self.avg_weight[feature_name] += self.weight[feature_name]*(
iterations*data_size - self.r[feature_name][1]*data_size - self.r[feature_name][0] + 1)
def cal_avg_weight(self, iterations, data_size):
for feature_name in self.avg_weight.keys():
self.weight[feature_name] = self.avg_weight[feature_name] / \
(iterations*data_size)
def save_model(self, model_file):
pickle.dump(self.weight, model_file)
def load_model(self, model_file):
self.weight = pickle.load(model_file)
1.3 小结
基于感知器的方法可以使用词作为特征,而基于线性链条件随机场的方法只能使用字作为特征。再上一个项目中自然语言处理导论与Python实践(一)词汇分析所介绍的以字为单位作为分类目标的方法也称为基于字的中文分词算法,本节所介绍的以词为基础的方法也称为基于词的中文分词算法。
需要注意的是,当未登录词其出现在训练语料中时,本教程中提到的算法仍会按照规则抽取特征,但是此时抽取的出的特征模型从未见过,在模型的特征中不会有它的记录。这就会导致严重的错误发生:因为没有特征记录,无法生成特征向量,导致模型识别能力的下降。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)