机器学习-----回归树
分类树与回归树分类树用于分类问题。分类决策树在选取划分点,用信息熵、信息增益、或者信息增益率、或者基尼系数为标准。Classification tree analysis is when the predicted outcome is the class to which the data belongs.回归决策树用于处理输出为连续型的数据。回归决策树在选取划分点,就希望划分的两个分支的误差越
分类树与回归树
分类树用于分类问题。分类决策树在选取划分点,用信息熵、信息增益、或者信息增益率、或者基尼系数为标准。
Classification tree analysis is when the predicted outcome is the class to which the data belongs.
回归决策树用于处理输出为连续型的数据。回归决策树在选取划分点,就希望划分的两个分支的误差越小越好。
Regression tree analysis is when the predicted outcome can be considered a real number (e.g. the price of a house, or a patient’s length of stay in a hospital)。
回归树
英文名字:Regression Tree
原理介绍
回归树总体流程也是类似,区别在于,回归树的每个节点(不一定是叶子节点)都会得一个预测值,以年龄为例,该预测值等于属于这个节点的所有人年龄的平均值。分枝时穷举每一个feature的每个阈值找最好的分割点,但衡量最好的标准不再是最大熵,而是最小化均方差即(每个人的年龄-预测年龄)^2 的总和 / N。也就是被预测出错的人数越多,错的越离谱,均方差就越大,通过最小化均方差能够找到最可靠的分枝依据。分枝直到每个叶子节点上人的年龄都唯一或者达到预设的终止条件(如叶子个数上限),若最终叶子节点上人的年龄不唯一,则以该节点上所有人的平均年龄做为该叶子节点的预测年龄。
总结:回归树使用最大均方差划分节点;每个节点样本的均值作为测试样本的回归预测值[1]。
节点的预测值是该节点下所有点的均值,这点在李航老师的《统计及旗下学习》中有体现:

code: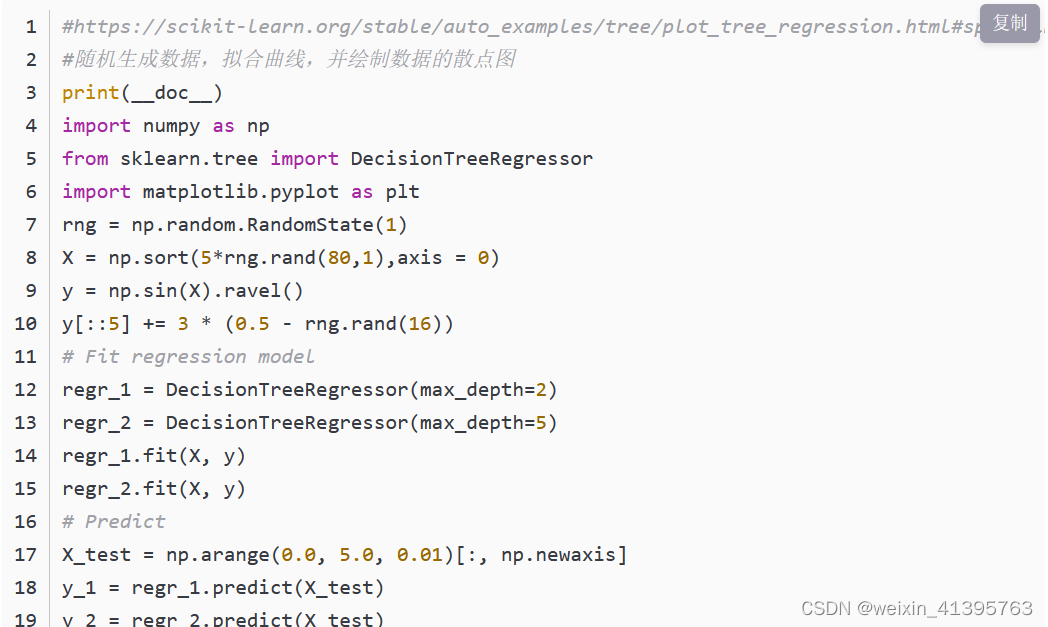

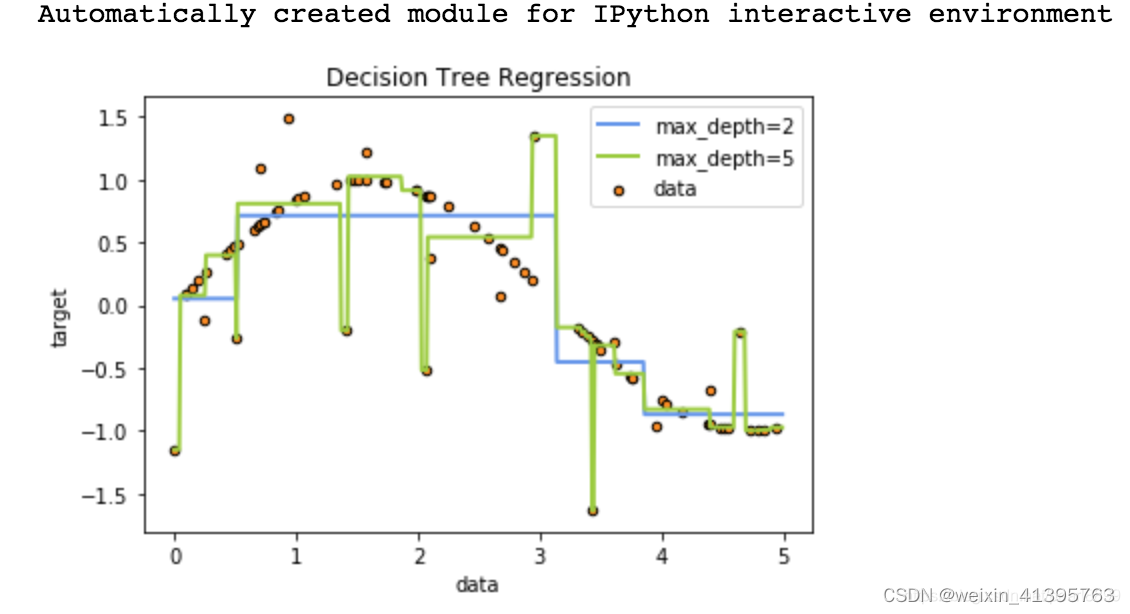
输出结果:
决策树优缺点
优点:
(1)速度快: 计算量相对较小, 且容易转化成分类规则. 只要沿着树根向下一直走到叶, 沿途的分裂条件就能够唯一确定一条分类的谓词.
(2)准确性高: 挖掘出来的分类规则准确性高, 便于理解, 决策树可以清晰的显示哪些字段比较重要, 即可以生成可以理解的规则.
(3)可以处理连续和种类字段
(4)不需要任何领域知识和参数假设
(5)适合高维数据
缺点:
(1)对于各类别样本数量不一致的数据, 信息增益偏向于那些更多数值的特征
(2)容易过拟合
(3)忽略属性之间的相关性

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)