机器学习:无监督学习
所谓无监督学习,是指利用无标签的数据学习数据的分布或者数据之间的关系;下面通过跟监督学习的对比来理解无监督学习:监督学习是一种目的明确的训练方式,你知道得到的是什么;而无监督学习则是没有明确目的的训练方式,你无法提前知道结果是什么。监督学习需要给数据打标签;而无监督学习不需要给数据打标签。监督学习由于目标明确,所以可以衡量效果;而无监督学习几乎无法量化效果如何。
什么是无监督学习
所谓无监督学习,是指利用无标签的数据学习数据的分布或者数据之间的关系;
下面通过跟监督学习的对比来理解无监督学习:
监督学习是一种目的明确的训练方式,你知道得到的是什么;而无监督学习则是没有明确目的的训练方式,你无法提前知道结果是什么。
监督学习需要给数据打标签;而无监督学习不需要给数据打标签。
监督学习由于目标明确,所以可以衡量效果;而无监督学习几乎无法量化效果如何。
为什么要使用无监督学习
以下是描述无监督学习重要性的一些主要原因:
无监督学习有助于从数据中找到有用的见解。
无监督学习与人类通过自己的经验学习思考非常相似,这使得它更接近真正的人工智能。
无监督学习适用于未标记和未分类的数据,这使得无监督学习更加重要。
在现实世界中,我们并不总是有输入数据和相应的输出,因此为了解决这种情况,我们需要无监督学习。
无监督学习的工作原理
下图可以理解无监督学习的工作原理: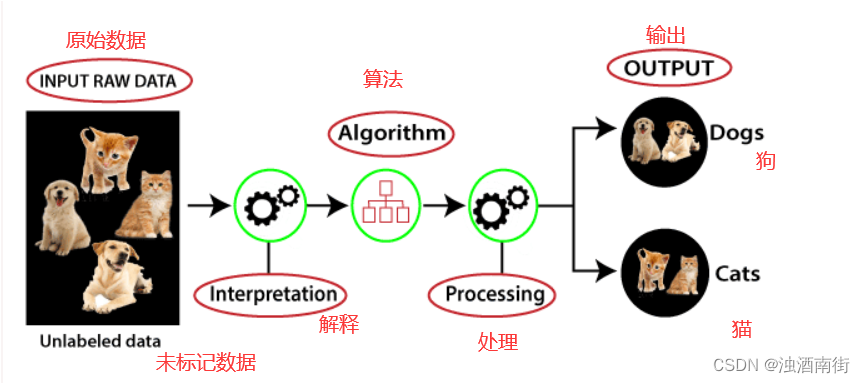
我们采用了未标记的输入数据,这些数据被输入机器学习模型以对其进行训练。它将解释原始数据以从数据中找到隐藏的模式,然后应用合适的算法,如 k-means 聚类等,该算法就会根据对象之间的相似性和差异性将数据对象分组。
无监督学习分类
常见的2类算法是:聚类、降维
聚类:简单说就是一种自动分类的方法,在监督学习中,你很清楚每一个分类是什么,但是聚类则不是,你并不清楚聚类后的几个分类每个代表什么意思。聚类常用算法:K均值,基于密度的聚类,最大期望聚类;
降维:降维看上去很像压缩。这是为了在尽可能保存相关的结构的同时降低数据的复杂度。
降维算法有潜语义模型(LSA),主成分分析(PCA),奇异值分解(SVD)等

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)