【计算机视觉】【论文阅读】DeepLab系列论文阅读笔记
DeepLab全系列论文阅读笔记 深入浅出
DeepLab系列论文阅读笔记
DeepLab系列
DeepLabV1
DeepLab V1是基于VGG16网络改写的,一共做了三件事。

首先,去掉了最后的全连接层。做语义分割使用全卷积网络是大势所趋,DeepLab当然也不能例外。
然后,去掉了最后两个池化层。池化层是神经网络中的一个经典结构,没记错的话,BP解决了神经网络训练的软件问题(权重更新),pooling解决了训练的硬件问题(对计算资源的需求)。这就是池化层的第一个作用,缩小特征层的尺寸。池化层还有另一个重要作用,快速扩大感受野。为什么要扩大感受野呢?为了利用更多的上下文信息进行分析。

既然pooling这么好用,为什么要去掉俩呢?这个问题需要从头捋。先说传统(早期)DCNN,主要用来解决图片的分类问题,举个栗子,对于下边这张语义分割的图,传统模型只需要指出图片中有没有小轿车,至于小轿车在哪儿,不care。这就需要网络网络具有平移不变性。我们都知道,卷积本身就具有平移不变性,而pooling可以进一步增强网络的这一特性,因为pooling本身就是一个模糊位置的过程。所以pooling对于传统DCNN可以说非常nice了。
再来说语义分割。语义分割是一个end-to-end的问题,需要对每个像素进行精确的分类,对像素的位置很敏感,是个精细活儿。这就很尴尬了,pooling是一个不断丢失位置信息的过程,而语义分割又需要这些信息,矛盾就产生了。没办法,只好去掉pooling喽。全去掉行不行,理论上是可行的,实际使用嘛,一来显卡没那么大的内存,二来费时间。所以只去掉了两层。
(PS:在DeepLab V1原文中,作者还指出一个问题,使用太多的pooling,特征层尺寸太小,包含的特征太稀疏了,不利于语义分割。)

哦,去了两个pooling,感受野又不够了怎么办?没关系,作者想了个办法,把atrous convolution借来用一下,这也是对VGG16的最后一个修改。atrous convolution人称空洞卷积(好像多称为dilation convolution,不过这是DeepLab的总结,那就得按DeepLab的来啊),相比于传统卷积,可以在不增加计算量的情况下扩大感受野,厉害了。先上张图
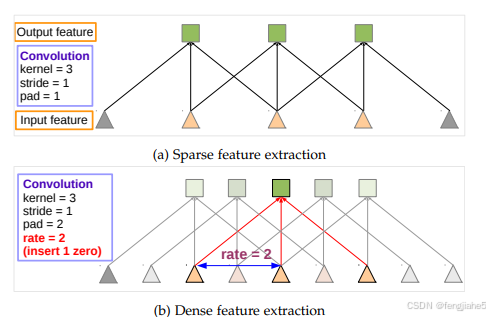
空洞卷积与传统卷积的区别在于,传统卷积是三连抽,感受野是3,空洞卷积是跳着抽,也就是使用图中的rate,感受野一下扩大到了5(rate=2),相当于两个传统卷积,而通过调整rate可以自由选择感受野。这样感受野的问题就解决了。
另外,原文指出,空洞卷积的优势在于增加了特征的密度。盯着上边这张图我想了很久这个问题,虽然你画的密,但是卷积都是一对一的输入多大输出多大,怎么空洞卷积的特征就密了呢,这张图你不能单独看,上边的传统卷积是经过pooling以后的第一个卷积层,而下边卷积输入的浅粉色三角正是被pooling掉的像素。所以,下边的输出是上边的两倍,特征多出了一倍当然密啦。
DeepLab V1的另一个贡献是使用条件随机场CRF提高分类精度。效果如下图,可以看到提升是非常明显的。具体CRF是什么原理呢?没有去研究,因为懒到了V3就舍弃了CRF。

最后来张DeepLab V1的全流程图,其中上采样直接使用了双线性采样。

DeepLabV2
在DeepLab V2中,可能是觉得VGG16表达能力有限,于是换用了更复杂,表达能力更强的ResNet-101。
在V2中,同样对ResNet动了刀,刀法和V1相同。V2的贡献在于更加灵活的使用了atrous convolution,提出了空洞空间金字塔池化ASPP。还是先给图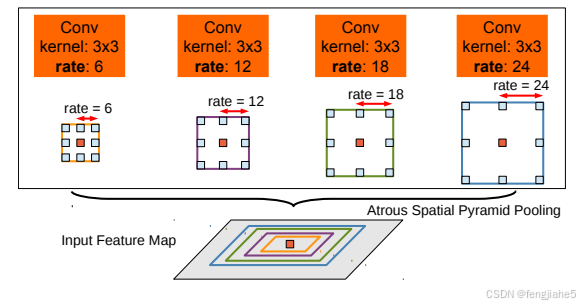
虽然名字挺复杂,但是看图就能轻易理解ASPP作用,说白了就是利用空洞卷积的优势,从不同的尺度上提取特征。
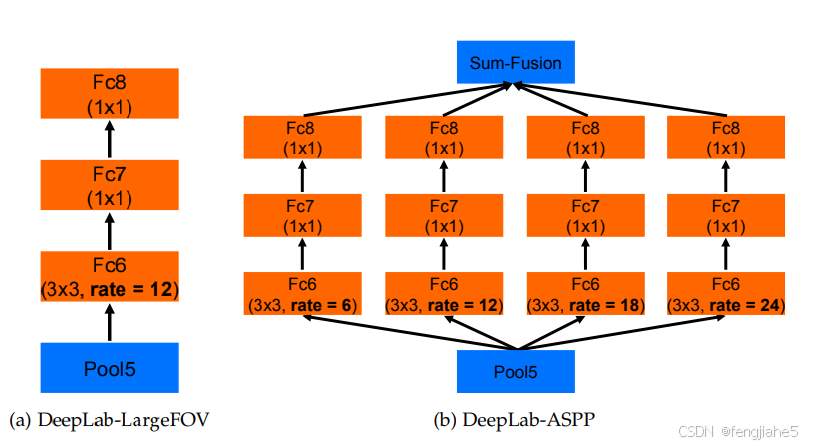
至于ASPP如何融合到ResNet中,看图说话。将VGG16的conv6,换成不同rate的空洞卷积,再跟上conv7,8,最后做个大融合(对应相加或1*1卷积)就OK了。
DeepLabV3
DeepLab V3 的主要改进包括:1) 去掉了 CRF 后处理,因为分类精度已足够高;2) 改进 ASPP 模块,加入 Batch Normalization 提升训练效果,新增 1×1 卷积分支和全局 image pooling 分支,解决空洞卷积因膨胀率增大导致的有效像素减少问题;3) 通过空洞卷积加深网络,提高模型捕获多尺度特征的能力。从效果来看,改进 ASPP 比单纯加深网络更具优势。
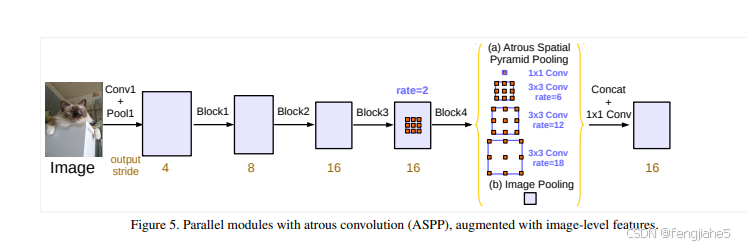
用空洞卷积代替池化 是其中一种核心思路。通过空洞卷积,模型在不显著减小特征图尺寸的情况下,能够扩大感受野,捕获更丰富的上下文信息。感受野的需求: 深层网络需要更大的感受野,以提取更大范围的上下文特征。但直接堆叠池化层虽然能增加感受野,却会导致特征图尺寸急剧减小,导致空间信息损失,尤其对于需要像素级预测的任务(如语义分割)是不可取的。空洞卷积的优势:
- 在不改变特征图分辨率的情况下,通过设置膨胀率(dilation rate)扩大感受野。
- 与池化不同,空洞卷积不会减少特征图的空间分辨率,而是保留了更多的局部细节信息。
Going deeper with atrous convolution 的思路就是通过堆叠空洞卷积层来不断加深网络,使其能够在更大的感受野范围内学习多尺度上下文信息,同时避免池化导致的分辨率损失。这种方法为语义分割任务提供了更高的精度和更精细的预测结果。

DeepLabV3+
DeepLab V3+再次修改了主网络,将ResNet-101升级到了Xception。在原始的Xception的基础上,进行了三点修改:1)使用更深的网络;2)将所有的卷积层和池化层用深度分离卷积Depthwise separable convolution进行替代,也就是下图中的Sep Conv;3)在每一次3*3 depthwise convolution之后使用BN和ReLU。
因为V3+使用深度分离卷积替代了pooling,那么为了缩小特征层尺寸,有几个block的最后一层的stride就必须为2,也就是下图中标红的层。具体有几个取决于输出output stride(下采样的大小)的设置。
Xception的核心是使用了Depthwise separable convolution。Depthwise separable convolution的思想来自inception结构,是inception结构的一种极限情况。Inception 首先给出了一种假设:卷积层通道间的相关性和空间相关性是可以退耦合的,将它们分开映射,能达到更好的效果。在inception结构中,先对输入进行11的卷积,之后将通道分组,分别使用不同的33卷积提取特征,最后将各组结果串联在一起作为输出。
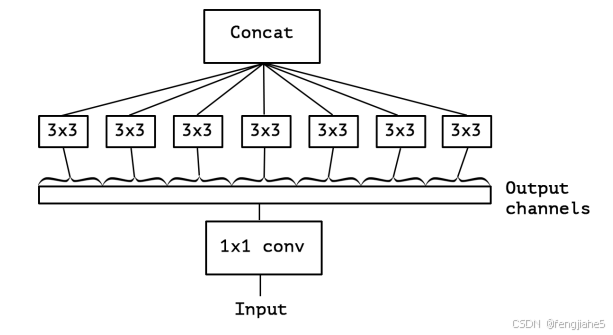
Depthwise separable convolution是将这种分组演化到了极致,即把每一个通道作为一组。先对输入的每一个通道做33的卷积,将各个通道的结果串联后,再通过1×1的卷积调整到目标通道数。
好处也很简单,大幅缩减参数个数。幅度有多大呢?举个简单的栗子,假设输入输出都是64通道,卷积核采用3*3,那么传统卷积的参数个数为3∗3∗64∗64=36864而Depthwise separable convolution为3∗3∗64+1∗1∗64∗64=4672
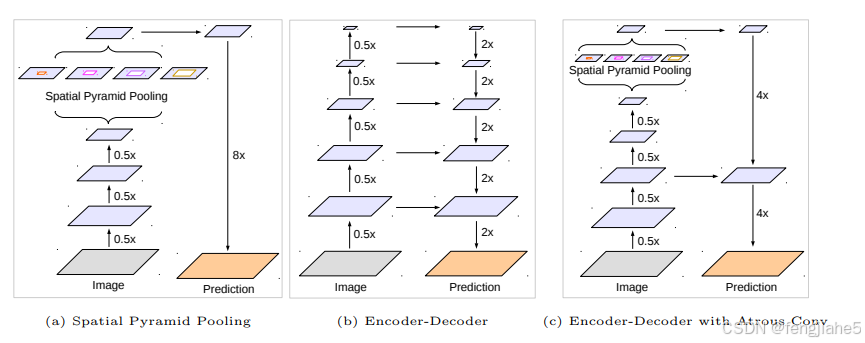
说完了backbone,再来说说V3+的整体结构。前三个版本都是backbone(ASPP)输出的结果直接双线性上采样到原始分辨率,非常简单粗暴的方法,下图中的(a)。用了三个版本,也觉得这样做太粗糙了,于是吸取Encoder-Deconder的结构,下图中的(b),增加了一个浅层到输出的skip层,下图中的c。
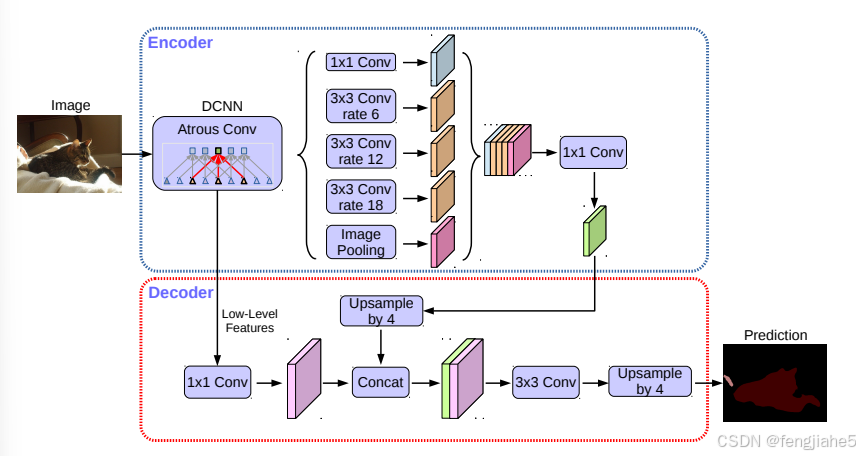
下面说说具体的skip方法。首先,选取block2中的第二个卷积输出(看代码这个是固定的),使用11卷积调整通道数到48(减小通道数是为了降低其在最终结果中的比重),然后resize到指定的尺寸,也就是output stride。然后,将ASPP的输出resize到output stride。最后将两部分串联起来做两次33的卷积。最后的最后再做一次1*1的卷积,得到分类结果。最后的最后的最后将分类结果resize到原来的分辨率,嗯,还是熟悉的双线性采样。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)