【InternLM 书生大模型】L0G2000 - Python
【代码】【InterLM 书生大模型】L0G2000 - Python
·
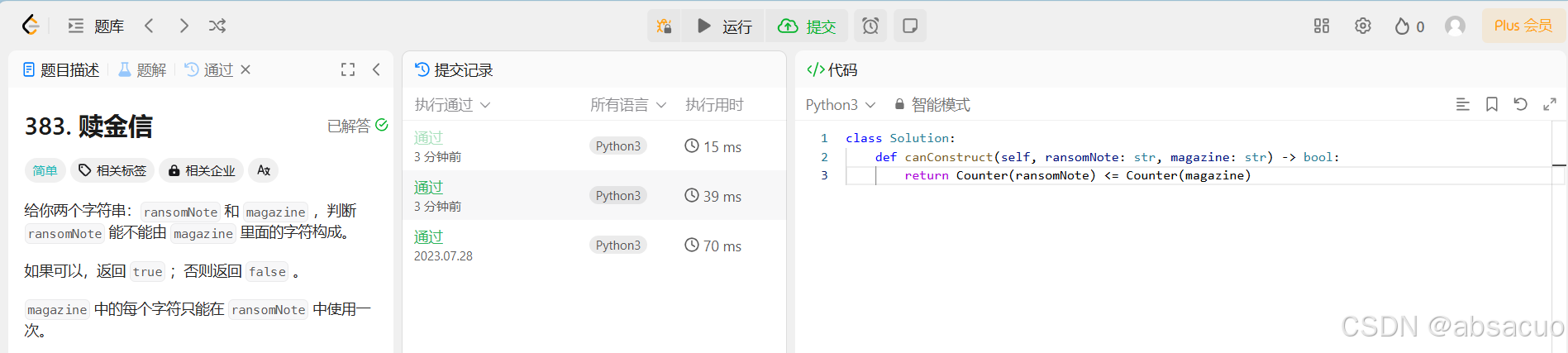
闯关任务 1:LeetCode 383
class Solution:
def canConstruct(self, ransomNote: str, magazine: str) -> bool:
return Counter(ransomNote) <= Counter(magazine)
- 使用 Python 内部自带的计数器 Counter
- 将两个字符串转化为类字典的字符个数统计形式,然后进行大小比较
闯关任务 2
- 直接运行原文件,显示在
json.loads(res)行报错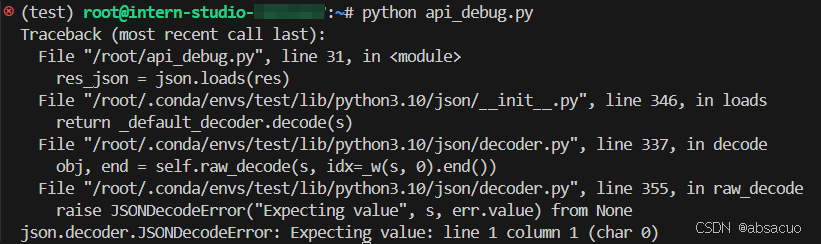
- 创建
launch.json文件,并选择Remote Attach形式运行,接口配置为本地 7860 接口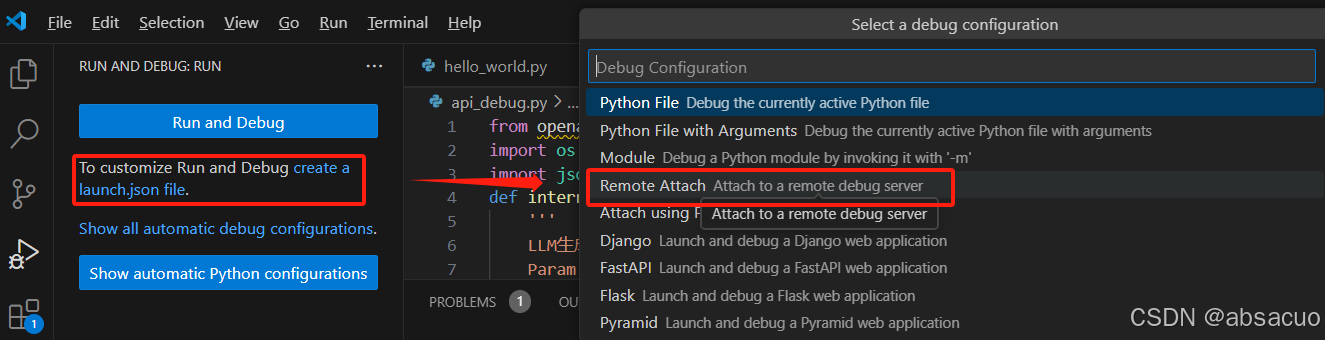
- 安装
debugpy包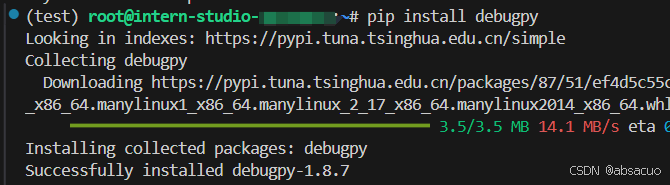
- 设置 log 断点,读取
res字符串的实际内容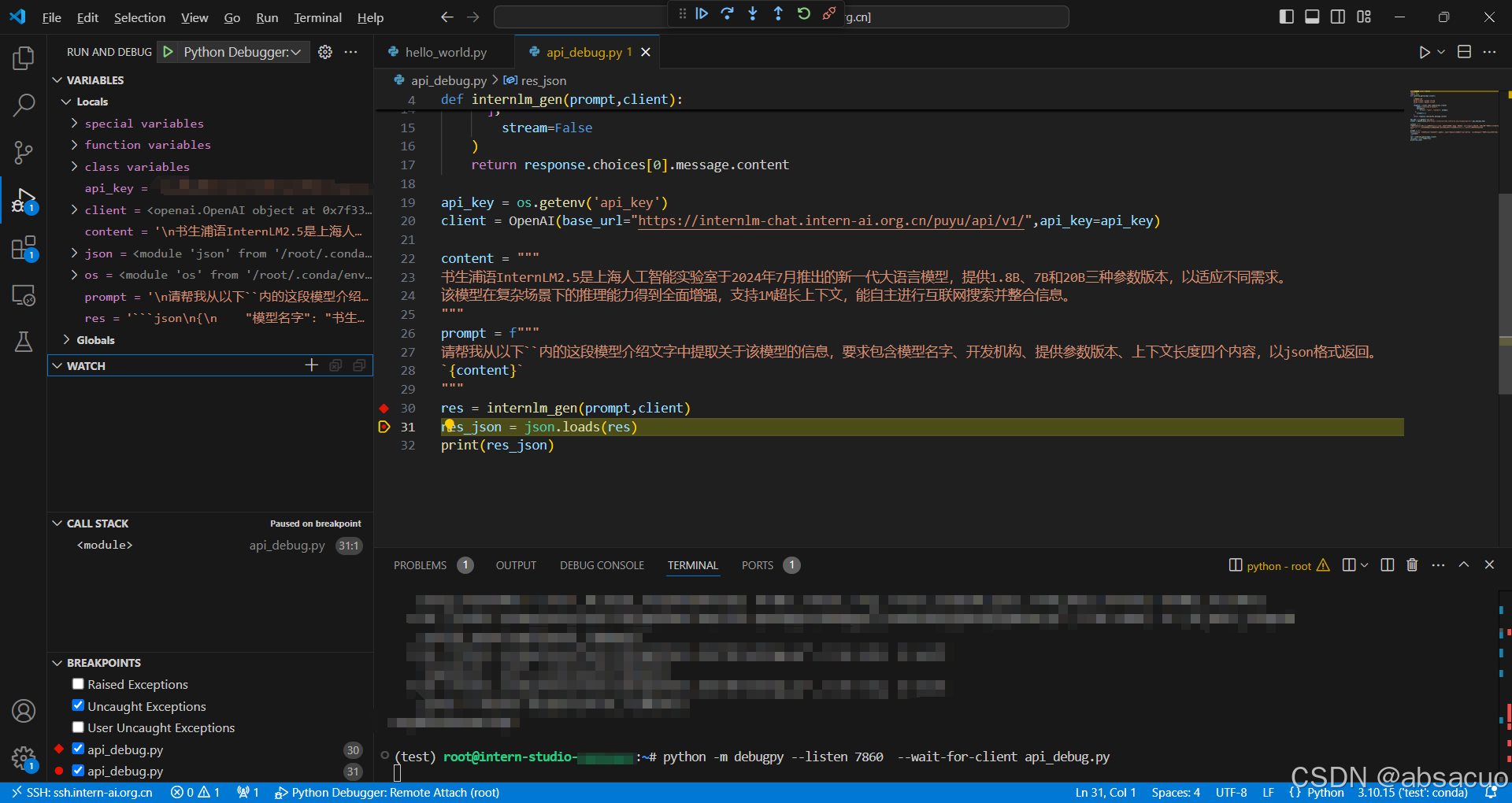
res_json = json.loads(res)报错原因- 字符串前后有多余符号,影响正确读取为 JSON 格式
'```json\n{\n "模型名字": "书生浦语InternLM2.5",\n "开发机构": "上海人工智能实验室",\n "提供参数版本": [1.8B, 7B, 20B],\n "上下文长度": "1M"\n}\n```' [1.8B, 7B, 20B]序列没有包裹为字符串
- 字符串前后有多余符号,影响正确读取为 JSON 格式
正确代码
from openai import OpenAI
import os
import re
import json
def internlm_gen(prompt,client):
'''
LLM生成函数
Param prompt: prompt string
Param client: OpenAI client
'''
response = client.chat.completions.create(
model="internlm2.5-latest",
messages=[
{"role": "user", "content": prompt},
],
stream=False
)
return response.choices[0].message.content
api_key = os.getenv('api_key')
client = OpenAI(base_url="https://internlm-chat.intern-ai.org.cn/puyu/api/v1/",api_key=api_key)
content = """
书生浦语InternLM2.5是上海人工智能实验室于2024年7月推出的新一代大语言模型,提供1.8B、7B和20B三种参数版本,以适应不同需求。
该模型在复杂场景下的推理能力得到全面增强,支持1M超长上下文,能自主进行互联网搜索并整合信息。
"""
prompt = f"""
请帮我从以下``内的这段模型介绍文字中提取关于该模型的信息,要求包含模型名字、开发机构、提供参数版本、上下文长度四个内容,以json格式返回。
`{content}`
"""
res = internlm_gen(prompt,client)
# 去掉干扰符号
res = res[7:-3].strip()
# 正则
res = re.sub(r'(\d+\.\d+B|\d+B)', r'"\1"', res)
res_json = json.loads(res)
print(res_json)
可选任务:pip 安装到指定目录


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)