deepseek R1 671B满血/量化 本地部署记录(ollama\sglang)
Deepseek R1 满血和量化版 不同方式的部署记录
·
ollama 运行 量化671B deepseek R1
ollama准备
- 下载并解压软件
curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz
sudo tar -C /usr -xzf ollama-linux-amd64.tgz
- 配置环境变量
export OLLAMA_HOST=0.0.0.0:11434
export OLLAMA_ORIGINS=*
export OLLAMA_MODELS=/u01/ollama/models # 设置ollama的模型缓存位置
source ~/.bashrc 刷新下配置
模型准备
- 首先下载模型
pip install modelscope
modelscope download --model unsloth/DeepSeek-R1-GGUF DeepSeek-R1-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL-00001-of-00005.gguf --local_dir /u01/models
modelscope download --model unsloth/DeepSeek-R1-GGUF DeepSeek-R1-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL-00002-of-00005.gguf --local_dir /u01/models
modelscope download --model unsloth/DeepSeek-R1-GGUF DeepSeek-R1-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL-00003-of-00005.gguf --local_dir /u01/models
modelscope download --model unsloth/DeepSeek-R1-GGUF DeepSeek-R1-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL-00004-of-00005.gguf --local_dir ~/u01/models
modelscope download --model unsloth/DeepSeek-R1-GGUF DeepSeek-R1-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL-00005-of-00005.gguf --local_dir /u01/models
- llama.cpp下载
需要使用llama-gguf-split工具将刚刚得到5个字文件进行合并操作。
首先安装llama.cpp
直接git clone仓库文件并且build下
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
cmake -B build
cmake --build build --config Release -j 8
- 模型合并
cd build/bin
./llama-gguf-split --merge /u01/models/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL-00001-of-00005.gguf /u01/models/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-2.51bit.gguf
ollama加载模型
- 构建ModelFile
Vim /u01/ollama/r1/Modelfile
# 将下面的配置内容粘贴进去
cd /u01/ollama/r1
ollama serve # 先在一个端口启动下服务
ollama create deepseek-reasoner -f ./Modelfile
ollama list # 查看是配置好了
Modelfile配置文件:
FROM /u01/models/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-2.51bit.gguf
# 以下为模型模板配置
TEMPLATE """{{- if .System }}{{ .System }}{{ end }}
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1}}
{{- if eq .Role "user" }}<|User|>{{ .Content }}
{{- else if eq .Role "assistant" }}<|Assistant|>{{ .Content }}{{- if not $last }}<|end▁of▁sentence|>{{- end }}
{{- end }}
{{- if and $last (ne .Role "assistant") }}<|Assistant|>{{- end }}
{{- end }}"""
PARAMETER stop "<|begin▁of▁sentence|>"
PARAMETER stop "<|end▁of▁sentence|>"
PARAMETER stop "<|User|>"
PARAMETER stop "<|Assistant|>"
PARAMETER num_ctx 12800
- 启动模型
ollama run deepseek-reasoner
- 接下来到对应的应用配置下就行
http://x.x.x.x:11434
性能测试
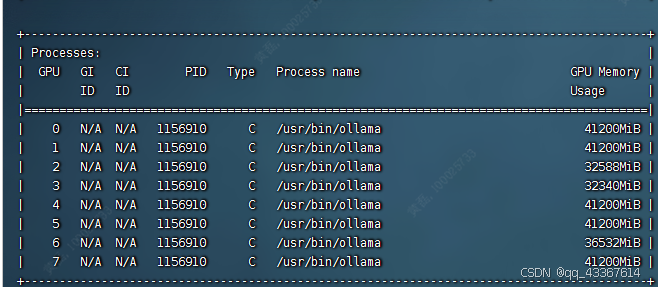
八开L20的机器(每张卡48G显存) 单人单次对话资源使用情况如下
输入token:37 输出token:1895 总耗时:76S
目前看来速度还是很堪忧,但是vllm和sglang对2bit的支持还不太好,等支持好了再来更新下启动方式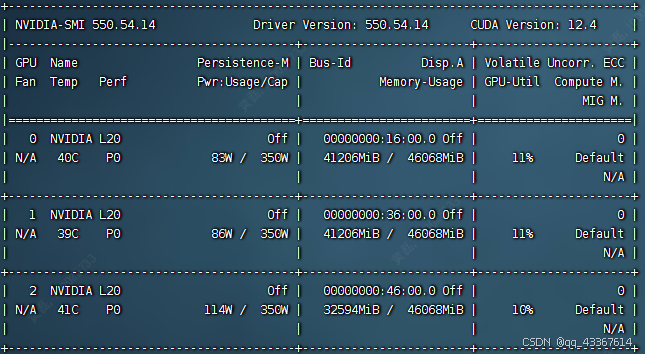
sglang 运行满血 671B deepseek R1(推荐)
为什么用sglang 不用vllm呢? 其实vllm也测试过,结果输出速度只有8 token/s 不知道怎么优化,这里就不推荐了
部署
- 模型下載
下载模型不再赘述 - 环境准备
pip install "sglang[all]>=0.4.3" --find-links https://flashinfer.ai/whl/cu124/torch2.5/flashinfer-python
- 模型启动
python3 -m sglang.launch_server \
--model /u01/model/deepseek-ai/DeepSeek-R1 \
--served-model-name deepseek-reasoner \
--trust-remote-code \
--mem-fraction-static 0.9 \
--tp 8 \
--host 0.0.0.0 \
--port 8000 \
结果评估
机器 : 8卡 H20服务器 96G * 8 - 671 基本只有很少的kv cache空间了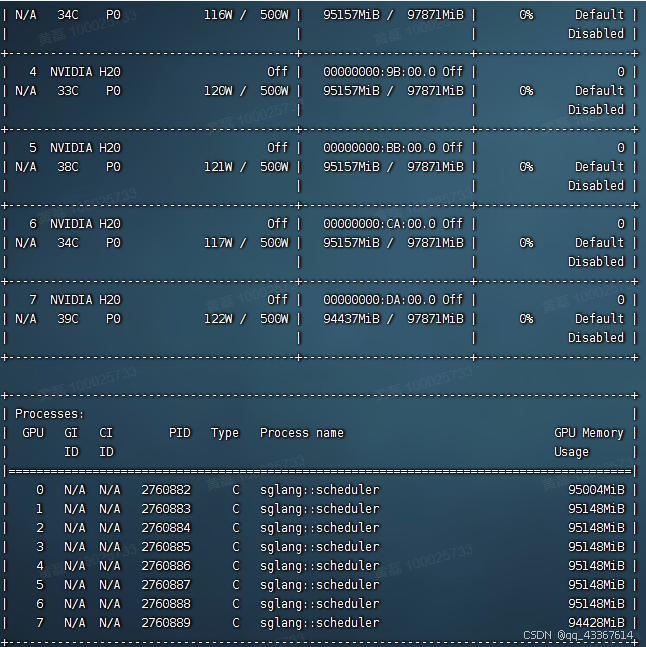
单人的 输出token速度大概在23tokens/s,token的最大长度大概在60k左右
估计只够5个人用,还是得2台H20服务器
KTransformer
这个还没时间,晚点去尝试下
先把链接挂上来
KTransformer guide book
看到的一个KTransformer guide库
参考

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)