【计算机科学】【2017.01】基于深度学习的语音信号增强
本文为西班牙加泰罗尼亚政治大学(作者:Dan Mihai Badescu)的论文,共33页。本文探讨了利用深度神经网络对含噪语音信号进行增强的可能性。信号增强是语音处理中的一个经典问题。近年来,基于深度学习的研究在许多语音处理任务中得到了应用,取得了令人满意的结果。作为第一步,我们实现了一个信号分析模块来计算数据库中每个音频文件的幅度和相位。通过将信号表示为幅度和相位,用神经网络对幅值进行修正..
本文为西班牙加泰罗尼亚政治大学(作者:Dan Mihai Badescu)的论文,共33页。
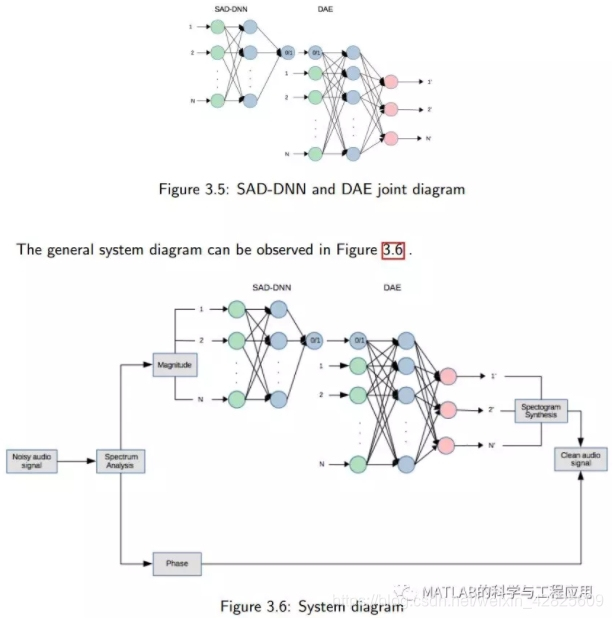
本文探讨了利用深度神经网络对含噪语音信号进行增强的可能性。信号增强是语音处理中的一个经典问题。近年来,基于深度学习的研究在许多语音处理任务中得到了应用,取得了令人满意的结果。作为第一步,我们实现了一个信号分析模块来计算数据库中每个音频文件的幅度和相位。通过将信号表示为幅度和相位,用神经网络对幅值进行修正,然后用原相位进行重构。神经网络的实现分为两个阶段。第一阶段是语音活动检测的深度神经网络(SAD-DNN)实现。先前计算的幅度应用于噪声数据,通过训练SAD-DNN,以便在语音或非语音中对每个帧进行分类,此分类对于执行最终清理的网络非常有用。语音活动检测采用深度神经网络,然后采用去噪自动编码器(DAE)。幅度和标记语音或非语音将作为第二深度神经网络的输入,负责完成语音信号的去噪。第一阶段也经过了优化,足以完成第二阶段的最终任务。为了进行训练,神经网络需要利用数据集。在这个项目中,Timit语料库被用作无噪语音(目标)的数据集,QUT-NOISE TIMIT语料库被用作噪声数据集(源)。最后,信号合成模块根据增强的幅度和相位重建干净的语音信号。最后,运用客观和主观两种方法对系统提供的结果进行了分析。
This thesis explores the possibility toachieve enhancement on noisy speech signals using Deep Neural Networks. Signalenhancement is a classic problem in speech processing. In the last years, researchesusing deep learning has been used in many speech processing tasks since theyhave provided very satisfactory results. As a first step, a Signal AnalysisModule has been implemented in order to calculate the magnitude and phase ofeach audio file in the database. The signal is represented into its magnitudeand its phase, where the magnitude is modified by the neural network, and thenit is reconstructed with the original phase. The implementation of the NeuralNetworks is divided into two stages. The first stage was the implementation ofa Speech Activity Detection Deep Neural Network (SAD-DNN). The magnitudepreviously calculated, applied to the noisy data, will train the SAD-DNN inorder to classify each frame in speech or non-speech. This classification isuseful for the network that does the final cleaning. The Speech ActivityDetection Deep Neural Network is followed by a Denoising Auto-Encoder (DAE).The magnitude and the label speech or non-speech will be the input of thissecond Deep Neural Network in charge of denoising the speech signal. The firststage is also optimized to be adequate for the final task in this second stage.In order to do the training, Neural Networks require datasets. In this projectthe Timit corpus [9] has been used as dataset for the clean voice (target) andthe QUT-NOISE TIMIT corpus[4] as noisy dataset (source). Finally, SignalSynthesis Module reconstructs the clean speech signal from the enhancedmagnitudes and the phase. In the end, the results provided by the system havebeen analysed using both objective and subjective measures.
1 引言
2 深度学习技术和语音增强的最新进展
3 基于深度学习进展的语音信号增强
4 结果
5 预算
6 结论与未来工作展望
更多精彩文章请关注公众号:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 0
0 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)